 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOuroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering
Aug 20, 2025



While multi-step diffusion models have advanced both forward and inverse rendering, existing approaches often treat these problems independently, leading to cycle inconsistency and slow inference speed. In this work, we present Ouroboros, a framework composed of two single-step diffusion models that handle forward and inverse rendering with mutual reinforcement. Our approach extends intrinsic decomposition to both indoor and outdoor scenes and introduces a cycle consistency mechanism that ensures coherence between forward and inverse rendering outputs. Experimental results demonstrate state-of-the-art performance across diverse scenes while achieving substantially faster inference speed compared to other diffusion-based methods. We also demonstrate that Ouroboros can transfer to video decomposition in a training-free manner, reducing temporal inconsistency in video sequences while maintaining high-quality per-frame inverse rendering.
Drive-1-to-3: Enriching Diffusion Priors for Novel View Synthesis of Real Vehicles
Dec 19, 2024The recent advent of large-scale 3D data, e.g. Objaverse, has led to impressive progress in training pose-conditioned diffusion models for novel view synthesis. However, due to the synthetic nature of such 3D data, their performance drops significantly when applied to real-world images. This paper consolidates a set of good practices to finetune large pretrained models for a real-world task -- harvesting vehicle assets for autonomous driving applications. To this end, we delve into the discrepancies between the synthetic data and real driving data, then develop several strategies to account for them properly. Specifically, we start with a virtual camera rotation of real images to ensure geometric alignment with synthetic data and consistency with the pose manifold defined by pretrained models. We also identify important design choices in object-centric data curation to account for varying object distances in real driving scenes -- learn across varying object scales with fixed camera focal length. Further, we perform occlusion-aware training in latent spaces to account for ubiquitous occlusions in real data, and handle large viewpoint changes by leveraging a symmetric prior. Our insights lead to effective finetuning that results in a $68.8\%$ reduction in FID for novel view synthesis over prior arts.
CoMA: Compositional Human Motion Generation with Multi-modal Agents
Dec 10, 2024



3D human motion generation has seen substantial advancement in recent years. While state-of-the-art approaches have improved performance significantly, they still struggle with complex and detailed motions unseen in training data, largely due to the scarcity of motion datasets and the prohibitive cost of generating new training examples. To address these challenges, we introduce CoMA, an agent-based solution for complex human motion generation, editing, and comprehension. CoMA leverages multiple collaborative agents powered by large language and vision models, alongside a mask transformer-based motion generator featuring body part-specific encoders and codebooks for fine-grained control. Our framework enables generation of both short and long motion sequences with detailed instructions, text-guided motion editing, and self-correction for improved quality. Evaluations on the HumanML3D dataset demonstrate competitive performance against state-of-the-art methods. Additionally, we create a set of context-rich, compositional, and long text prompts, where user studies show our method significantly outperforms existing approaches.
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes
May 04, 2024Photorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which is fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes.
DiL-NeRF: Delving into Lidar for Neural Radiance Field on Street Scenes
May 01, 2024Photorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which is fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes.
Integrating Efficient Optimal Transport and Functional Maps For Unsupervised Shape Correspondence Learning
Mar 04, 2024



In the realm of computer vision and graphics, accurately establishing correspondences between geometric 3D shapes is pivotal for applications like object tracking, registration, texture transfer, and statistical shape analysis. Moving beyond traditional hand-crafted and data-driven feature learning methods, we incorporate spectral methods with deep learning, focusing on functional maps (FMs) and optimal transport (OT). Traditional OT-based approaches, often reliant on entropy regularization OT in learning-based framework, face computational challenges due to their quadratic cost. Our key contribution is to employ the sliced Wasserstein distance (SWD) for OT, which is a valid fast optimal transport metric in an unsupervised shape matching framework. This unsupervised framework integrates functional map regularizers with a novel OT-based loss derived from SWD, enhancing feature alignment between shapes treated as discrete probability measures. We also introduce an adaptive refinement process utilizing entropy regularized OT, further refining feature alignments for accurate point-to-point correspondences. Our method demonstrates superior performance in non-rigid shape matching, including near-isometric and non-isometric scenarios, and excels in downstream tasks like segmentation transfer. The empirical results on diverse datasets highlight our framework's effectiveness and generalization capabilities, setting new standards in non-rigid shape matching with efficient OT metrics and an adaptive refinement module.
Adaptive Image Registration: A Hybrid Approach Integrating Deep Learning and Optimization Functions for Enhanced Precision
Nov 27, 2023Image registration has traditionally been done using two distinct approaches: learning based methods, relying on robust deep neural networks, and optimization-based methods, applying complex mathematical transformations to warp images accordingly. Of course, both paradigms offer advantages and disadvantages, and, in this work, we seek to combine their respective strengths into a single streamlined framework, using the outputs of the learning based method as initial parameters for optimization while prioritizing computational power for the image pairs that offer the greatest loss. Our investigations showed that an improvement of 0.3\% in testing when utilizing the best performing state-of-the-art model as the backbone of the framework, while maintaining the same inference time and with only a 0.8\% loss in deformation field smoothness.
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
Nov 11, 2023Reconstructing personalized animatable head avatars has significant implications in the fields of AR/VR. Existing methods for achieving explicit face control of 3D Morphable Models (3DMM) typically rely on multi-view images or videos of a single subject, making the reconstruction process complex. Additionally, the traditional rendering pipeline is time-consuming, limiting real-time animation possibilities. In this paper, we introduce CVTHead, a novel approach that generates controllable neural head avatars from a single reference image using point-based neural rendering. CVTHead considers the sparse vertices of mesh as the point set and employs the proposed Vertex-feature Transformer to learn local feature descriptors for each vertex. This enables the modeling of long-range dependencies among all the vertices. Experimental results on the VoxCeleb dataset demonstrate that CVTHead achieves comparable performance to state-of-the-art graphics-based methods. Moreover, it enables efficient rendering of novel human heads with various expressions, head poses, and camera views. These attributes can be explicitly controlled using the coefficients of 3DMMs, facilitating versatile and realistic animation in real-time scenarios.
Light Field Diffusion for Single-View Novel View Synthesis
Sep 23, 2023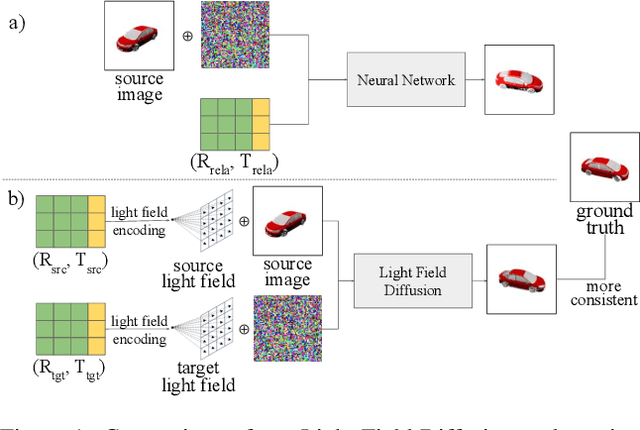
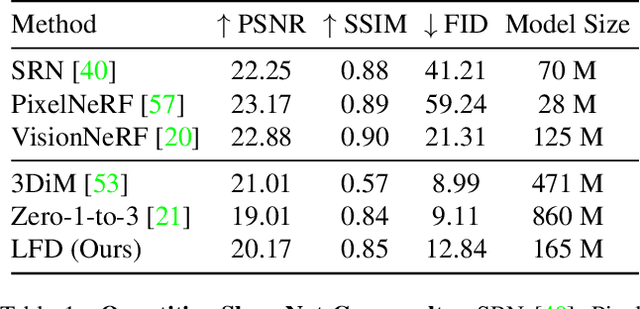
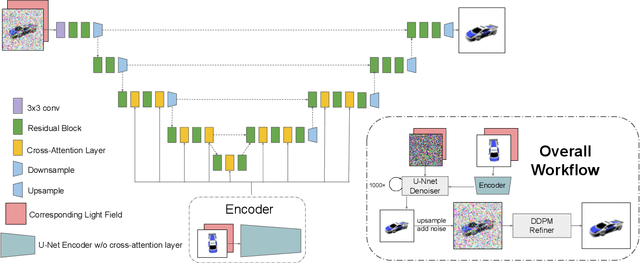
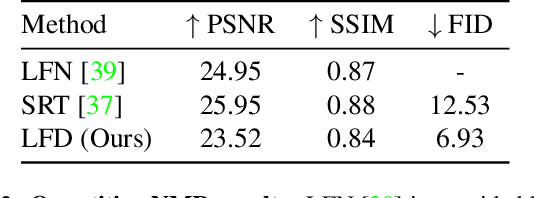
Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
Hybrid-CSR: Coupling Explicit and Implicit Shape Representation for Cortical Surface Reconstruction
Jul 23, 2023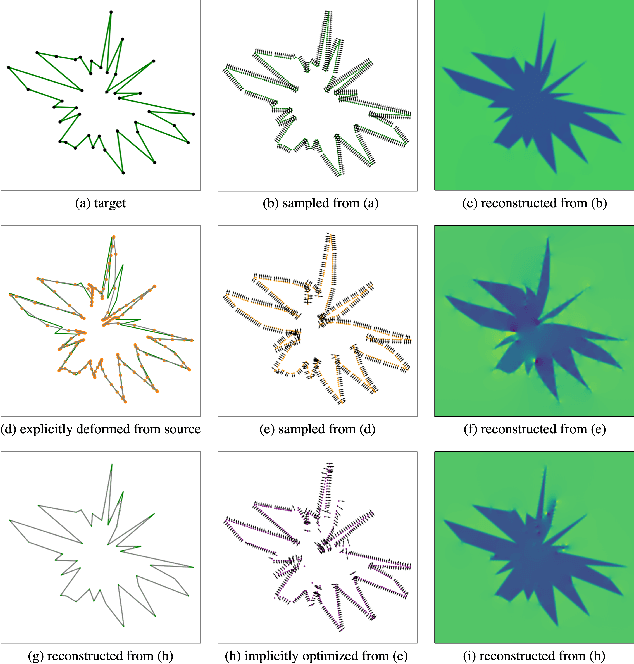
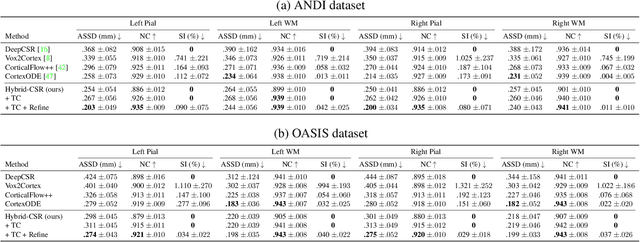
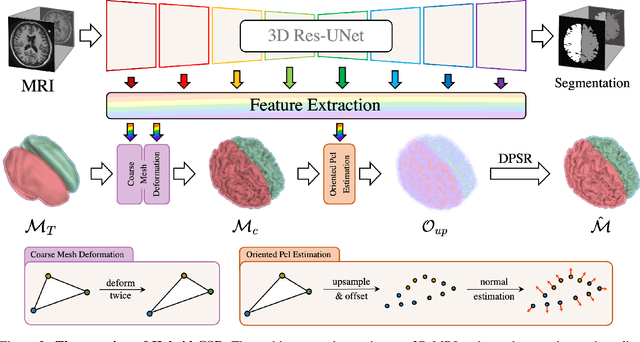
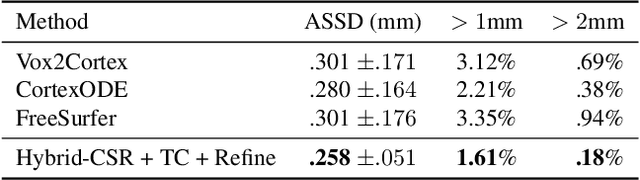
We present Hybrid-CSR, a geometric deep-learning model that combines explicit and implicit shape representations for cortical surface reconstruction. Specifically, Hybrid-CSR begins with explicit deformations of template meshes to obtain coarsely reconstructed cortical surfaces, based on which the oriented point clouds are estimated for the subsequent differentiable poisson surface reconstruction. By doing so, our method unifies explicit (oriented point clouds) and implicit (indicator function) cortical surface reconstruction. Compared to explicit representation-based methods, our hybrid approach is more friendly to capture detailed structures, and when compared with implicit representation-based methods, our method can be topology aware because of end-to-end training with a mesh-based deformation module. In order to address topology defects, we propose a new topology correction pipeline that relies on optimization-based diffeomorphic surface registration. Experimental results on three brain datasets show that our approach surpasses existing implicit and explicit cortical surface reconstruction methods in numeric metrics in terms of accuracy, regularity, and consistency.