 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Jun 18, 2026Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
High-Fidelity 4D Hand-Object Capture via Multi-View Spatiotemporal Tracking and Physics-Aware Gaussians
Jun 18, 2026The growing demand for high-fidelity 4D hand-object interaction (HOI) data in embodied AI and spatial computing is currently bottlenecked by the reliance on pre-scanned object templates and physical markers. While recent methods have demonstrated promising results in reconstructing 4D hand-object interaction from videos, they are highly sensitive to initial estimates of hand and object poses. Yet, estimating these poses from images is challenging, in particular under severe occlusion which is inherent in hand-object interaction scenarios. We propose a novel system for the robust and accurate reconstruction of hands and objects from synchronized and calibrated multi-view videos without requiring any templates or markers. Our system consists of two main components with key innovations: (1) a multi-view feed-forward transformer model that aggregates cross-view geometry and temporal cues to provide a reliable, metric-consistent initialization for both poses and dense object geometry, and (2) a hand-object physics-aware Gaussian-based optimization framework to refine the initial estimates, integrating tetrahedral constraints, collision refinement, and appearance decomposition to produce physically plausible and visually accurate reconstruction. Validated on public benchmarks and an extensive internal dataset, our pipeline achieves highly robust, artifact-free reconstruction, providing an efficient foundation for automated 4D asset generation. Our project page are available at https://zyshen021.github.io/HOSTPG/.
DSA: Dynamic Step Allocation for Fast Autoregressive Video Generation
Jun 03, 2026Video diffusion transformers have achieved state-of-the-art visual quality, but their high inference cost remains a major bottleneck for real-time applications. Recent distillation frameworks produce autoregressive video diffusion models with reduced latency, yet these models still use a fixed number of denoising steps per frame, wasting computation on predictable frames and under-refining challenging ones. We present DSA, a confidence-guided adaptive computation framework for AR video diffusion. DSA introduces a lightweight confidence head, trained jointly with the generator under a distribution-matching distillation objective, to estimate per-frame denoising reliability. At inference, this confidence signal dynamically adjusts the number of diffusion steps: simple frames terminate early for speed, while complex frames receive additional refinement. Our method requires no extra video data, no heuristics, and little architectural modification. Experiments show that DSA achieves real-time autoregressive video generation, reaching 22.63 FPS with sub-second latency on H100 GPUs, while maintaining competitive or superior VBench quality compared to recent autoregressive and bidirectional video diffusion models. Our results demonstrate that confidence-guided adaptive sampling provides an effective and practical path toward interactive video generation.
UMAMI: Unifying Masked Autoregressive Models and Deterministic Rendering for View Synthesis
Dec 23, 2025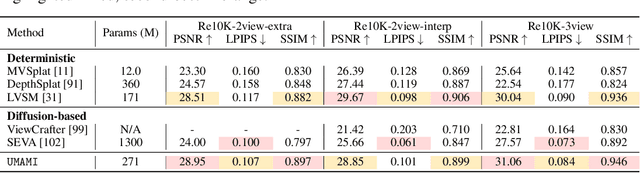
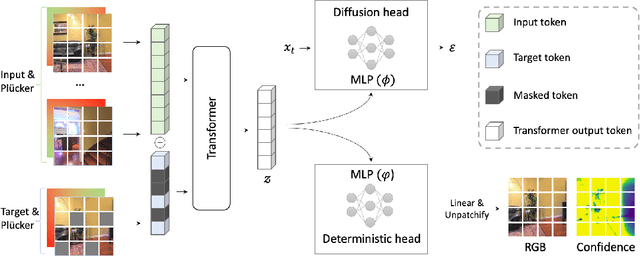
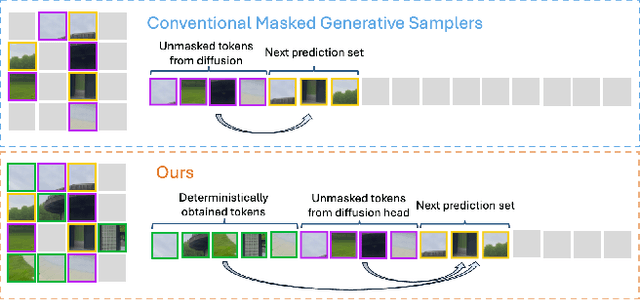

Novel view synthesis (NVS) seeks to render photorealistic, 3D-consistent images of a scene from unseen camera poses given only a sparse set of posed views. Existing deterministic networks render observed regions quickly but blur unobserved areas, whereas stochastic diffusion-based methods hallucinate plausible content yet incur heavy training- and inference-time costs. In this paper, we propose a hybrid framework that unifies the strengths of both paradigms. A bidirectional transformer encodes multi-view image tokens and Plucker-ray embeddings, producing a shared latent representation. Two lightweight heads then act on this representation: (i) a feed-forward regression head that renders pixels where geometry is well constrained, and (ii) a masked autoregressive diffusion head that completes occluded or unseen regions. The entire model is trained end-to-end with joint photometric and diffusion losses, without handcrafted 3D inductive biases, enabling scalability across diverse scenes. Experiments demonstrate that our method attains state-of-the-art image quality while reducing rendering time by an order of magnitude compared with fully generative baselines.
Hybrid-CSR: Coupling Explicit and Implicit Shape Representation for Cortical Surface Reconstruction
Jul 23, 2023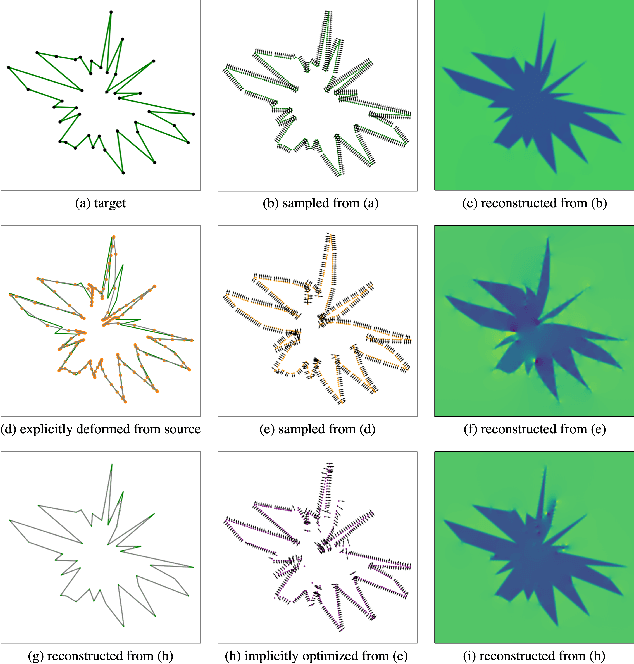
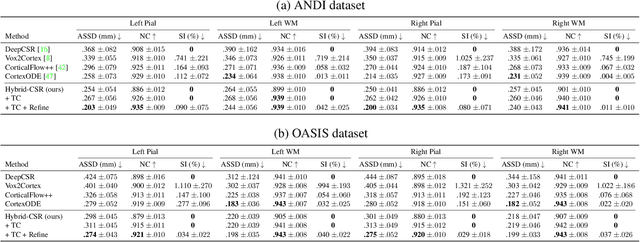
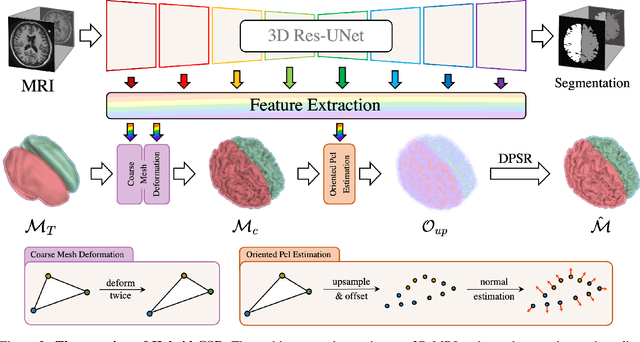
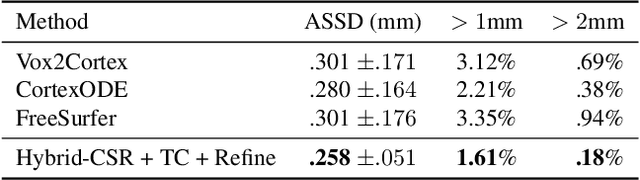
We present Hybrid-CSR, a geometric deep-learning model that combines explicit and implicit shape representations for cortical surface reconstruction. Specifically, Hybrid-CSR begins with explicit deformations of template meshes to obtain coarsely reconstructed cortical surfaces, based on which the oriented point clouds are estimated for the subsequent differentiable poisson surface reconstruction. By doing so, our method unifies explicit (oriented point clouds) and implicit (indicator function) cortical surface reconstruction. Compared to explicit representation-based methods, our hybrid approach is more friendly to capture detailed structures, and when compared with implicit representation-based methods, our method can be topology aware because of end-to-end training with a mesh-based deformation module. In order to address topology defects, we propose a new topology correction pipeline that relies on optimization-based diffeomorphic surface registration. Experimental results on three brain datasets show that our approach surpasses existing implicit and explicit cortical surface reconstruction methods in numeric metrics in terms of accuracy, regularity, and consistency.
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022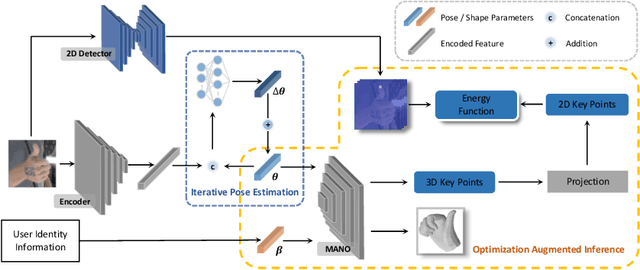
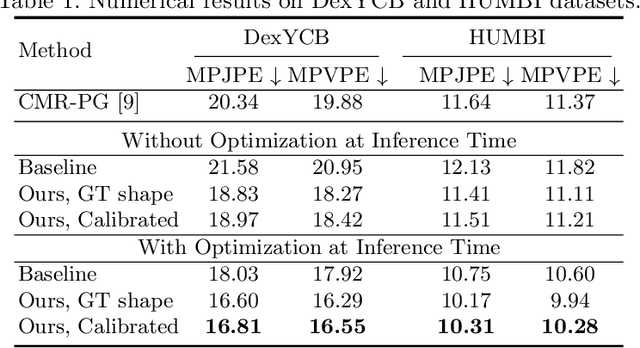
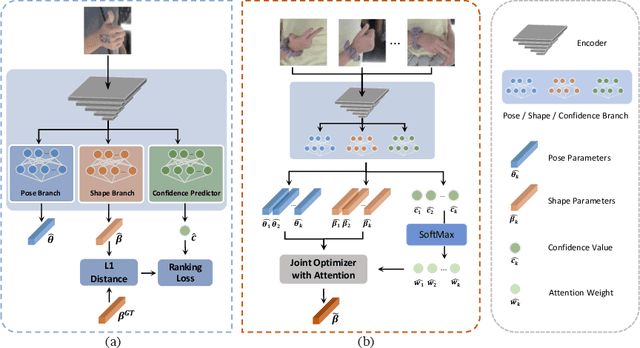
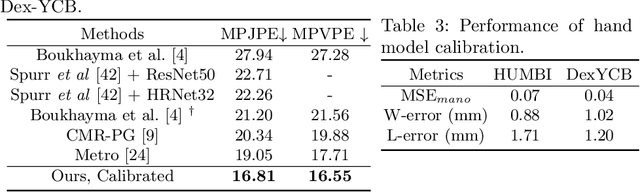
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation
Sep 16, 2022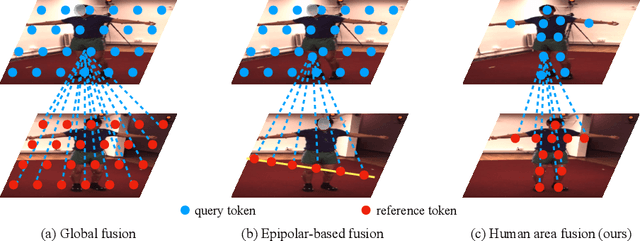
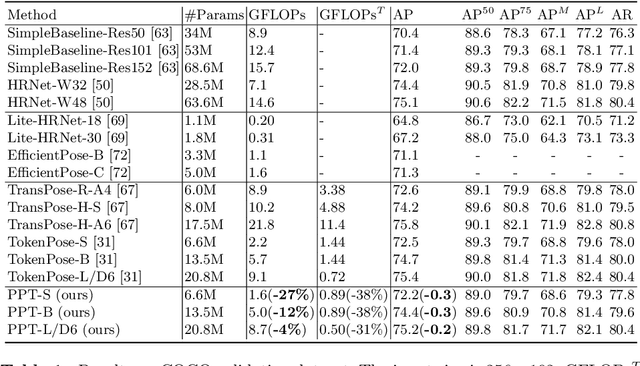

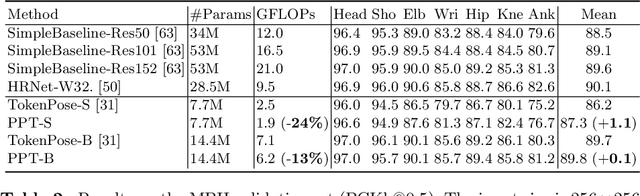
Recently, the vision transformer and its variants have played an increasingly important role in both monocular and multi-view human pose estimation. Considering image patches as tokens, transformers can model the global dependencies within the entire image or across images from other views. However, global attention is computationally expensive. As a consequence, it is difficult to scale up these transformer-based methods to high-resolution features and many views. In this paper, we propose the token-Pruned Pose Transformer (PPT) for 2D human pose estimation, which can locate a rough human mask and performs self-attention only within selected tokens. Furthermore, we extend our PPT to multi-view human pose estimation. Built upon PPT, we propose a new cross-view fusion strategy, called human area fusion, which considers all human foreground pixels as corresponding candidates. Experimental results on COCO and MPII demonstrate that our PPT can match the accuracy of previous pose transformer methods while reducing the computation. Moreover, experiments on Human 3.6M and Ski-Pose demonstrate that our Multi-view PPT can efficiently fuse cues from multiple views and achieve new state-of-the-art results.
MIRNF: Medical Image Registration via Neural Fields
Jun 07, 2022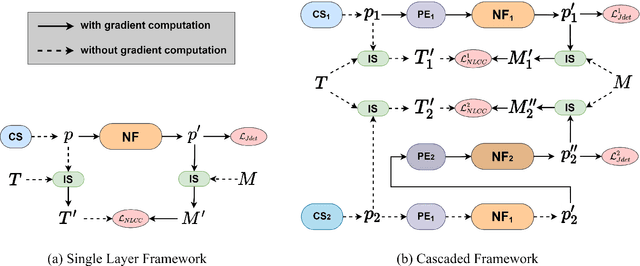
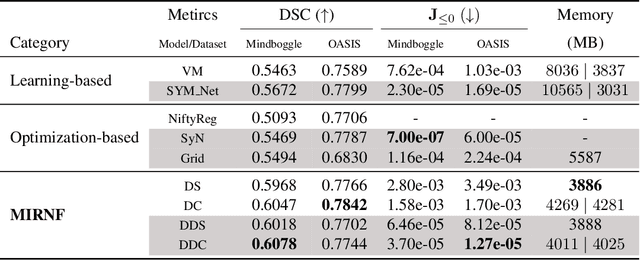
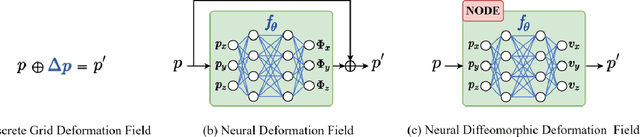
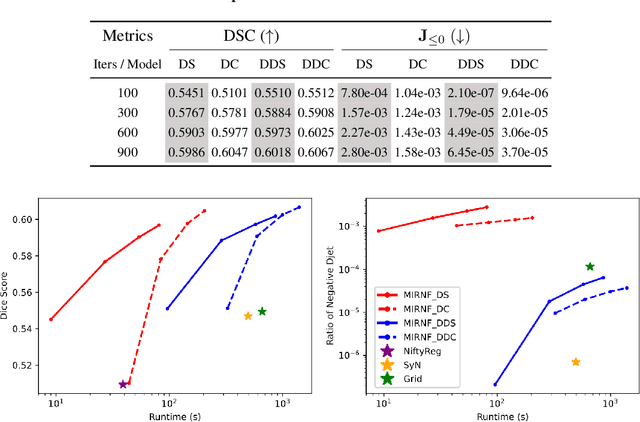
Image registration is widely used in medical image analysis to provide spatial correspondences between two images. Recently learning-based methods utilizing convolutional neural networks (CNNs) have been proposed for solving image registration problems. The learning-based methods tend to be much faster than traditional optimization-based methods, but the accuracy improvements gained from the complex CNN-based methods are modest. Here we introduce a new deep-neural net-based image registration framework, named \textbf{MIRNF}, which represents the correspondence mapping with a continuous function implemented via Neural Fields. MIRNF outputs either a deformation vector or velocity vector given a 3D coordinate as input. To ensure the mapping is diffeomorphic, the velocity vector output from MIRNF is integrated using the Neural ODE solver to derive the correspondences between two images. Furthermore, we propose a hybrid coordinate sampler along with a cascaded architecture to achieve the high-similarity mapping performance and low-distortion deformation fields. We conduct experiments on two 3D MR brain scan datasets, showing that our proposed framework provides state-of-art registration performance while maintaining comparable optimization time.
Topology-Preserving Shape Reconstruction and Registration via Neural Diffeomorphic Flow
Mar 21, 2022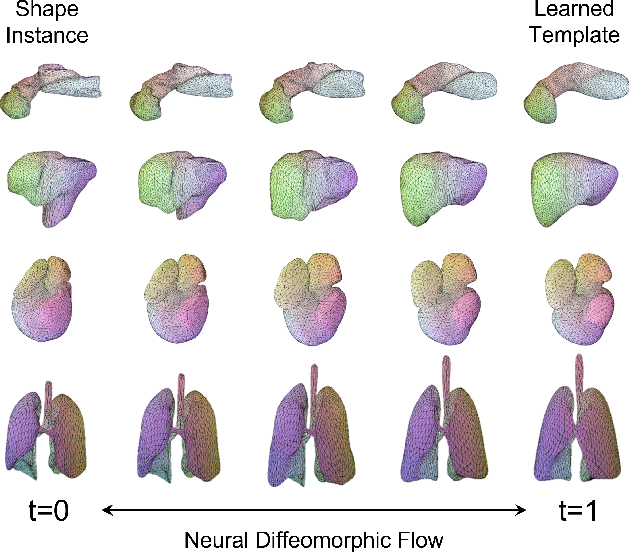

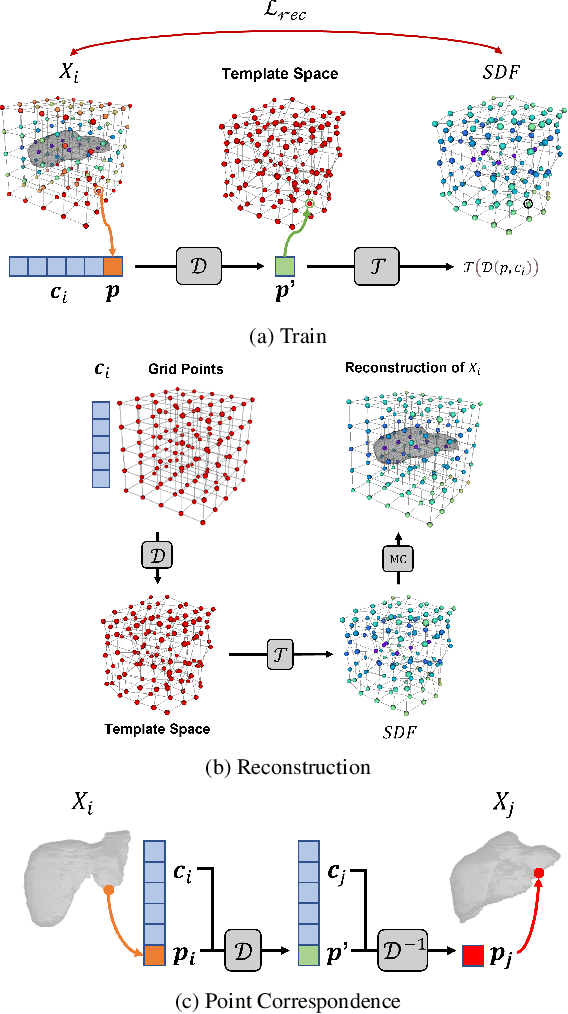
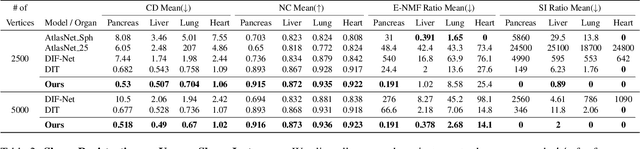
Deep Implicit Functions (DIFs) represent 3D geometry with continuous signed distance functions learned through deep neural nets. Recently DIFs-based methods have been proposed to handle shape reconstruction and dense point correspondences simultaneously, capturing semantic relationships across shapes of the same class by learning a DIFs-modeled shape template. These methods provide great flexibility and accuracy in reconstructing 3D shapes and inferring correspondences. However, the point correspondences built from these methods do not intrinsically preserve the topology of the shapes, unlike mesh-based template matching methods. This limits their applications on 3D geometries where underlying topological structures exist and matter, such as anatomical structures in medical images. In this paper, we propose a new model called Neural Diffeomorphic Flow (NDF) to learn deep implicit shape templates, representing shapes as conditional diffeomorphic deformations of templates, intrinsically preserving shape topologies. The diffeomorphic deformation is realized by an auto-decoder consisting of Neural Ordinary Differential Equation (NODE) blocks that progressively map shapes to implicit templates. We conduct extensive experiments on several medical image organ segmentation datasets to evaluate the effectiveness of NDF on reconstructing and aligning shapes. NDF achieves consistently state-of-the-art organ shape reconstruction and registration results in both accuracy and quality. The source code is publicly available at https://github.com/Siwensun/Neural_Diffeomorphic_Flow--NDF.
Diffeomorphic Image Registration with Neural Velocity Field
Mar 08, 2022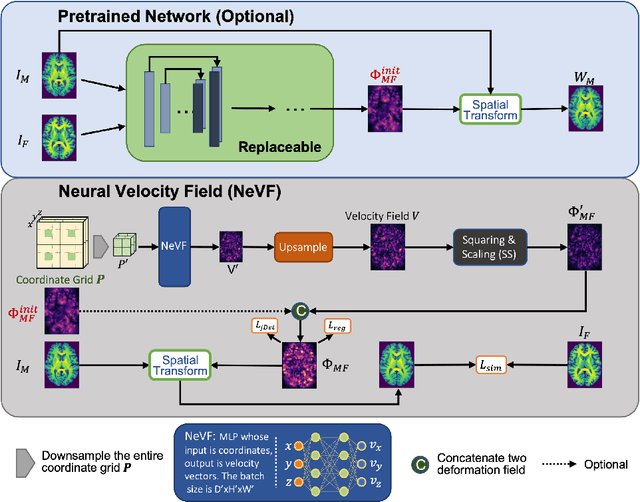
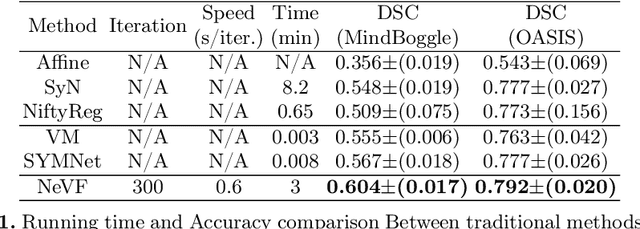
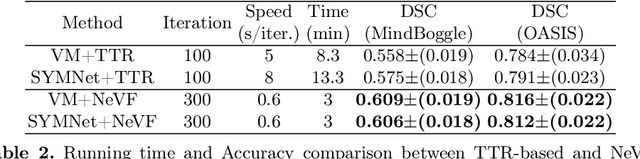
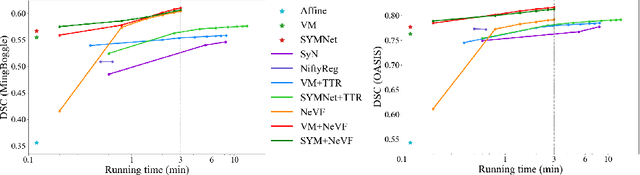
Diffeomorphic image registration is a crucial task in medical image analysis. Recent learning-based image registration methods utilize convolutional neural networks (CNN) to learn the spatial transformation between image pairs and achieve a fast inference speed. However, these methods often require a large number of training data to improve their generalization abilities. During the test time, learning-based methods might fail to provide a good registration result, which is likely because of the model overfitting on the training dataset. In this paper, we propose a neural representation of continuous velocity field (NeVF) to describe the deformations across two images. Specifically, this neural velocity field assigns a velocity vector to each point in the space, which has higher flexibility in modeling the complex deformation field. Furthermore, we propose a simple sparse-sampling strategy to reduce the memory consumption for the diffeomorphic registration. The proposed NeVF can also incorporate with a pre-trained learning-based model whose predicted deformation is taken as an initial state for optimization. Extensive experiments conducted on two large-scale 3D MR brain scan datasets demonstrate that our proposed method outperforms the state-of-the-art registration methods by a large margin.