 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFish Audio S2 Technical Report
Mar 11, 2026We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.
Differentially Private Joint Independence Test
Mar 24, 2025



Identification of joint dependence among more than two random vectors plays an important role in many statistical applications, where the data may contain sensitive or confidential information. In this paper, we consider the the d-variable Hilbert-Schmidt independence criterion (dHSIC) in the context of differential privacy. Given the limiting distribution of the empirical estimate of dHSIC is complicated Gaussian chaos, constructing tests in the non-privacy regime is typically based on permutation and bootstrap. To detect joint dependence in privacy, we propose a dHSIC-based testing procedure by employing a differentially private permutation methodology. Our method enjoys privacy guarantee, valid level and pointwise consistency, while the bootstrap counterpart suffers inconsistent power. We further investigate the uniform power of the proposed test in dHSIC metric and $L_2$ metric, indicating that the proposed test attains the minimax optimal power across different privacy regimes. As a byproduct, our results also contain the pointwise and uniform power of the non-private permutation dHSIC, addressing an unsolved question remained in Pfister et al. (2018).
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022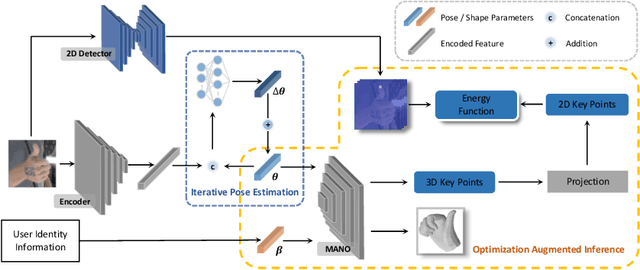
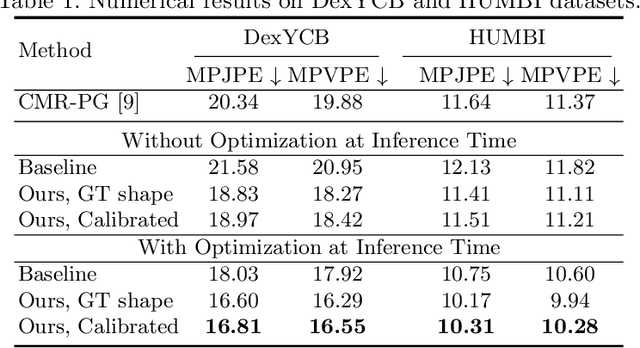
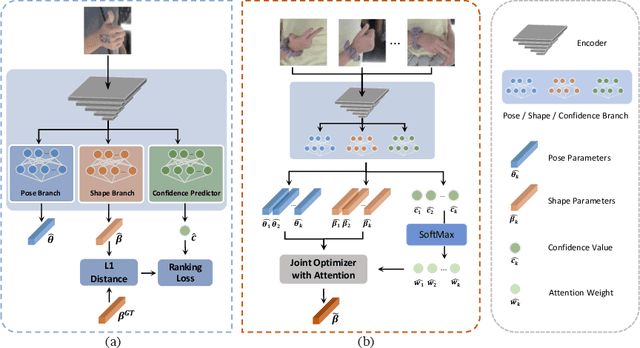
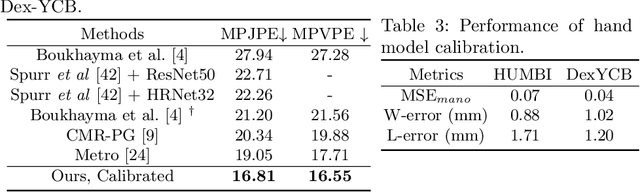
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation
Sep 16, 2022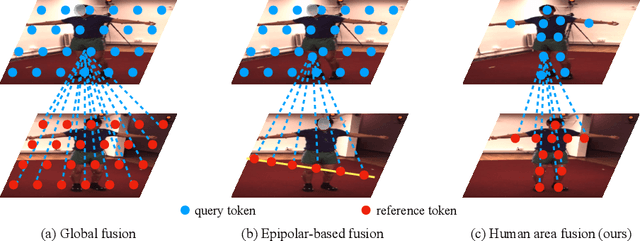
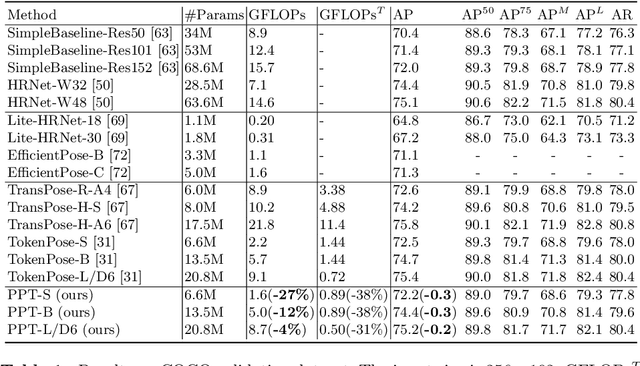

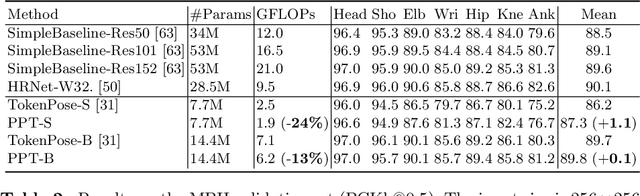
Recently, the vision transformer and its variants have played an increasingly important role in both monocular and multi-view human pose estimation. Considering image patches as tokens, transformers can model the global dependencies within the entire image or across images from other views. However, global attention is computationally expensive. As a consequence, it is difficult to scale up these transformer-based methods to high-resolution features and many views. In this paper, we propose the token-Pruned Pose Transformer (PPT) for 2D human pose estimation, which can locate a rough human mask and performs self-attention only within selected tokens. Furthermore, we extend our PPT to multi-view human pose estimation. Built upon PPT, we propose a new cross-view fusion strategy, called human area fusion, which considers all human foreground pixels as corresponding candidates. Experimental results on COCO and MPII demonstrate that our PPT can match the accuracy of previous pose transformer methods while reducing the computation. Moreover, experiments on Human 3.6M and Ski-Pose demonstrate that our Multi-view PPT can efficiently fuse cues from multiple views and achieve new state-of-the-art results.
TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation
Oct 29, 2021
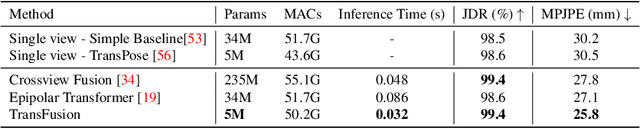
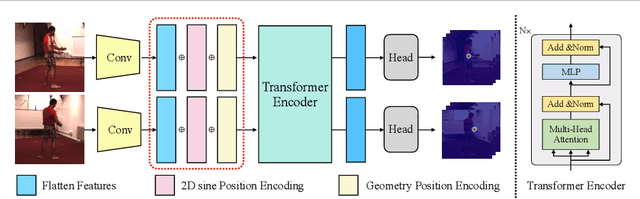

Estimating the 2D human poses in each view is typically the first step in calibrated multi-view 3D pose estimation. But the performance of 2D pose detectors suffers from challenging situations such as occlusions and oblique viewing angles. To address these challenges, previous works derive point-to-point correspondences between different views from epipolar geometry and utilize the correspondences to merge prediction heatmaps or feature representations. Instead of post-prediction merge/calibration, here we introduce a transformer framework for multi-view 3D pose estimation, aiming at directly improving individual 2D predictors by integrating information from different views. Inspired by previous multi-modal transformers, we design a unified transformer architecture, named TransFusion, to fuse cues from both current views and neighboring views. Moreover, we propose the concept of epipolar field to encode 3D positional information into the transformer model. The 3D position encoding guided by the epipolar field provides an efficient way of encoding correspondences between pixels of different views. Experiments on Human 3.6M and Ski-Pose show that our method is more efficient and has consistent improvements compared to other fusion methods. Specifically, we achieve 25.8 mm MPJPE on Human 3.6M with only 5M parameters on 256 x 256 resolution.
Recurrent Mask Refinement for Few-Shot Medical Image Segmentation
Aug 04, 2021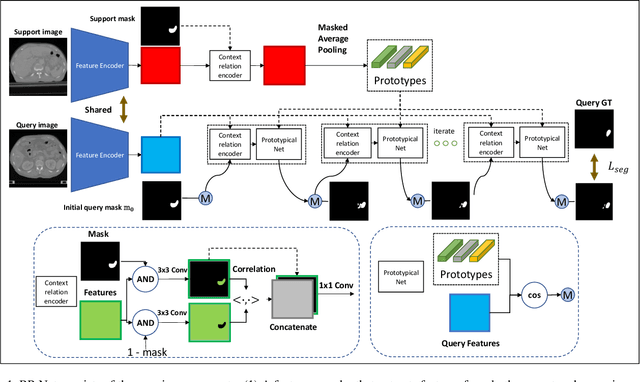
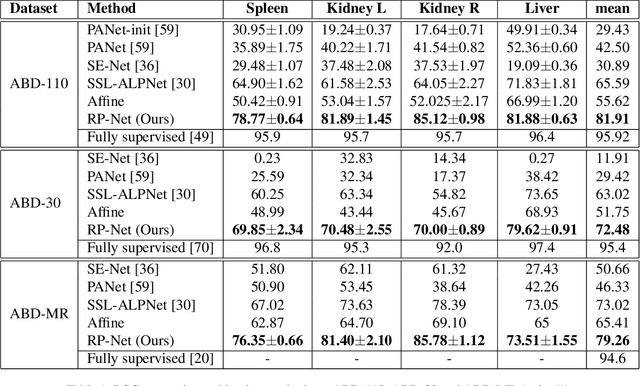
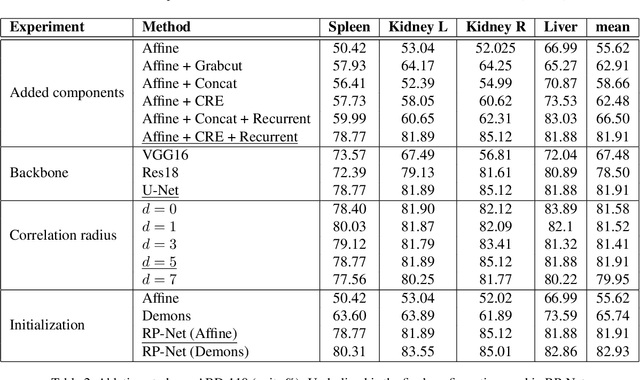
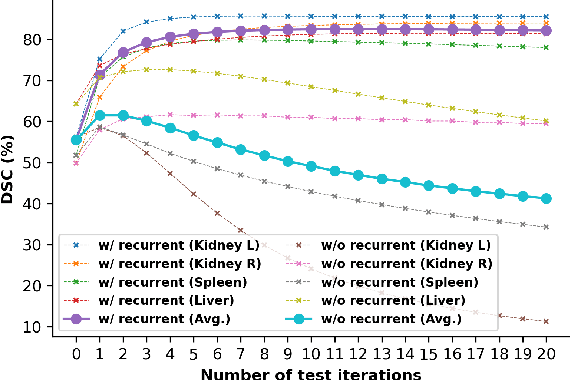
Although having achieved great success in medical image segmentation, deep convolutional neural networks usually require a large dataset with manual annotations for training and are difficult to generalize to unseen classes. Few-shot learning has the potential to address these challenges by learning new classes from only a few labeled examples. In this work, we propose a new framework for few-shot medical image segmentation based on prototypical networks. Our innovation lies in the design of two key modules: 1) a context relation encoder (CRE) that uses correlation to capture local relation features between foreground and background regions; and 2) a recurrent mask refinement module that repeatedly uses the CRE and a prototypical network to recapture the change of context relationship and refine the segmentation mask iteratively. Experiments on two abdomen CT datasets and an abdomen MRI dataset show the proposed method obtains substantial improvement over the state-of-the-art methods by an average of 16.32%, 8.45% and 6.24% in terms of DSC, respectively. Code is publicly available.
Spatial Context-Aware Self-Attention Model For Multi-Organ Segmentation
Dec 16, 2020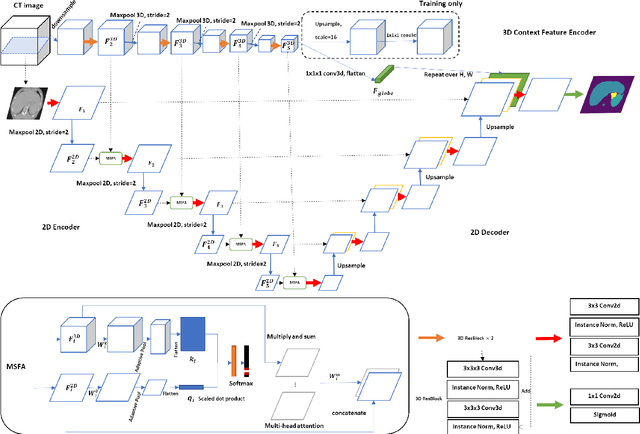

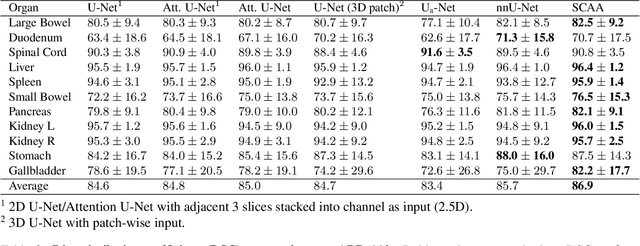
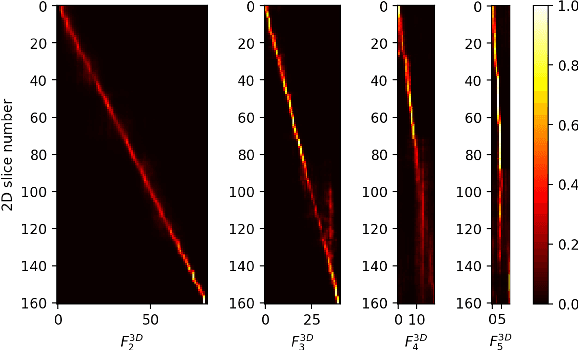
Multi-organ segmentation is one of most successful applications of deep learning in medical image analysis. Deep convolutional neural nets (CNNs) have shown great promise in achieving clinically applicable image segmentation performance on CT or MRI images. State-of-the-art CNN segmentation models apply either 2D or 3D convolutions on input images, with pros and cons associated with each method: 2D convolution is fast, less memory-intensive but inadequate for extracting 3D contextual information from volumetric images, while the opposite is true for 3D convolution. To fit a 3D CNN model on CT or MRI images on commodity GPUs, one usually has to either downsample input images or use cropped local regions as inputs, which limits the utility of 3D models for multi-organ segmentation. In this work, we propose a new framework for combining 3D and 2D models, in which the segmentation is realized through high-resolution 2D convolutions, but guided by spatial contextual information extracted from a low-resolution 3D model. We implement a self-attention mechanism to control which 3D features should be used to guide 2D segmentation. Our model is light on memory usage but fully equipped to take 3D contextual information into account. Experiments on multiple organ segmentation datasets demonstrate that by taking advantage of both 2D and 3D models, our method is consistently outperforms existing 2D and 3D models in organ segmentation accuracy, while being able to directly take raw whole-volume image data as inputs.
An End-to-end Framework For Integrated Pulmonary Nodule Detection and False Positive Reduction
Mar 23, 2019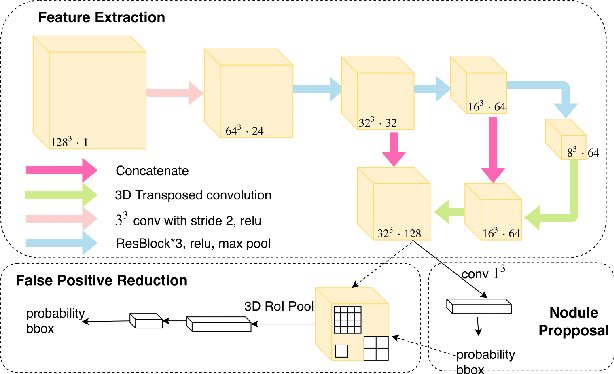

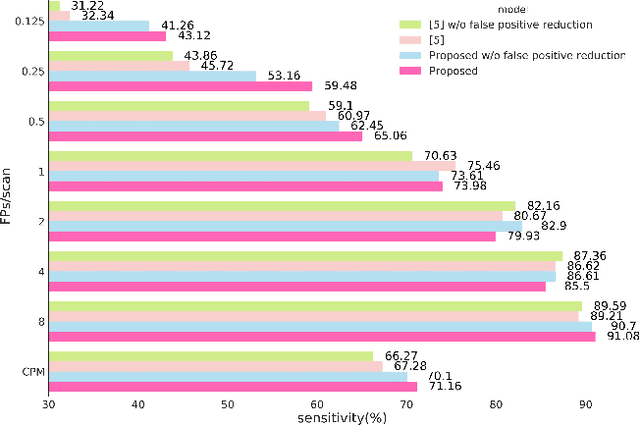
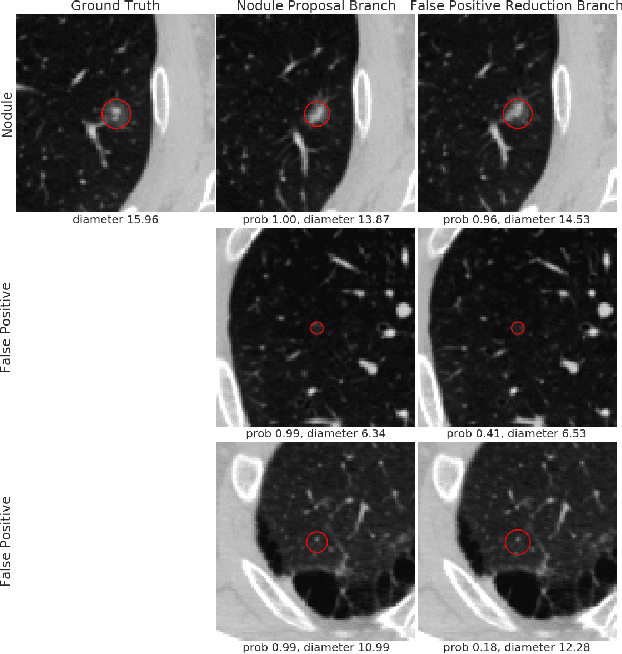
Pulmonary nodule detection using low-dose Computed Tomography (CT) is often the first step in lung disease screening and diagnosis. Recently, algorithms based on deep convolutional neural nets have shown great promise for automated nodule detection. Most of the existing deep learning nodule detection systems are constructed in two steps: a) nodule candidates screening and b) false positive reduction, using two different models trained separately. Although it is commonly adopted, the two-step approach not only imposes significant resource overhead on training two independent deep learning models, but also is sub-optimal because it prevents cross-talk between the two. In this work, we present an end-to-end framework for nodule detection, integrating nodule candidate screening and false positive reduction into one model, trained jointly. We demonstrate that the end-to-end system improves the performance by 3.88\% over the two-step approach, while at the same time reducing model complexity by one third and cutting inference time by 3.6 fold. Code will be made publicly available.