 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
Geometric Neural Distance Fields for Learning Human Motion Priors
Sep 11, 2025We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
Dec 03, 2024



Despite remarkable progress in image generation models, generating realistic hands remains a persistent challenge due to their complex articulation, varying viewpoints, and frequent occlusions. We present FoundHand, a large-scale domain-specific diffusion model for synthesizing single and dual hand images. To train our model, we introduce FoundHand-10M, a large-scale hand dataset with 2D keypoints and segmentation mask annotations. Our insight is to use 2D hand keypoints as a universal representation that encodes both hand articulation and camera viewpoint. FoundHand learns from image pairs to capture physically plausible hand articulations, natively enables precise control through 2D keypoints, and supports appearance control. Our model exhibits core capabilities that include the ability to repose hands, transfer hand appearance, and even synthesize novel views. This leads to zero-shot capabilities for fixing malformed hands in previously generated images, or synthesizing hand video sequences. We present extensive experiments and evaluations that demonstrate state-of-the-art performance of our method.
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024



We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022
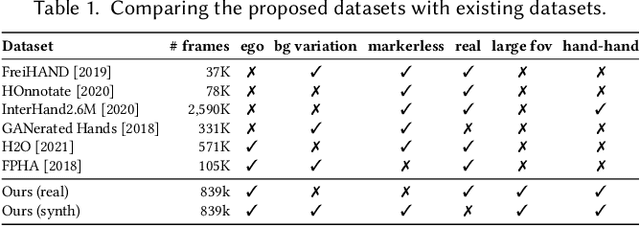
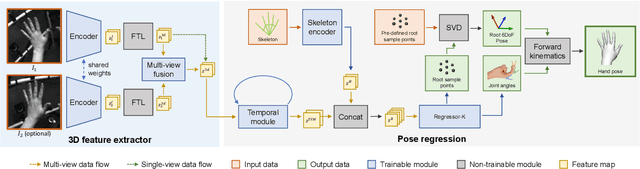
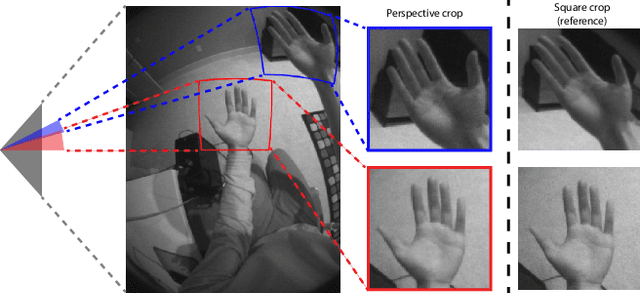
Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022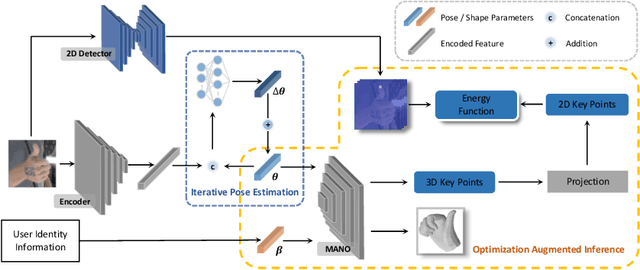
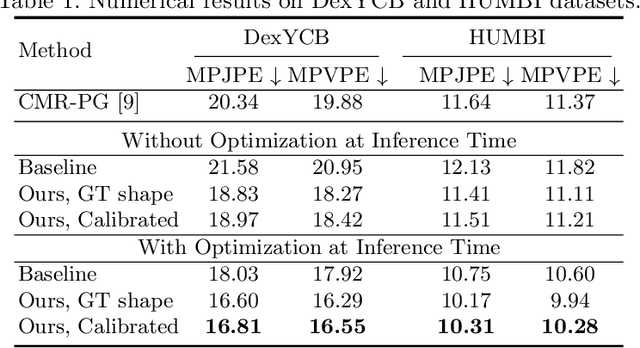
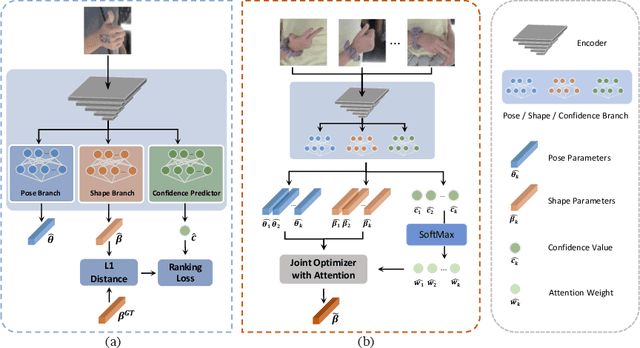
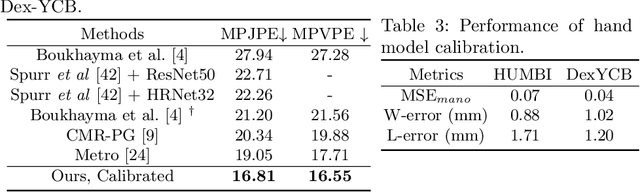
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
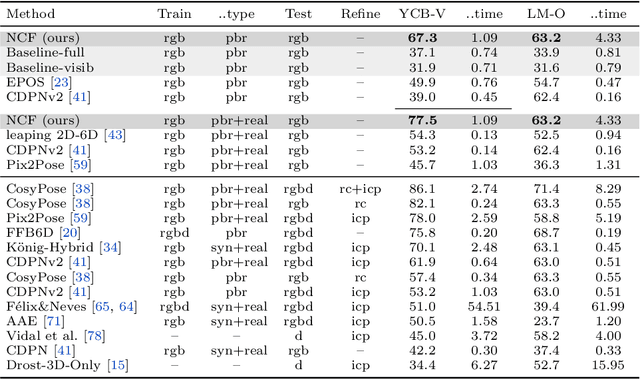
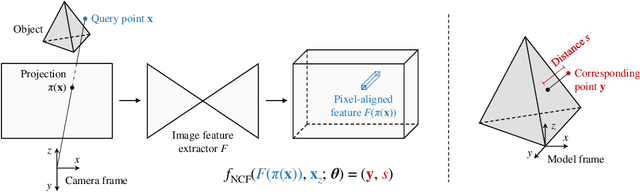
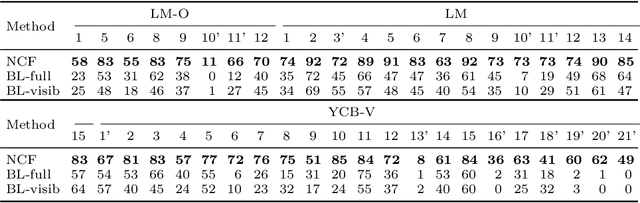
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
Accelerating Large-Kernel Convolution Using Summed-Area Tables
Jun 26, 2019
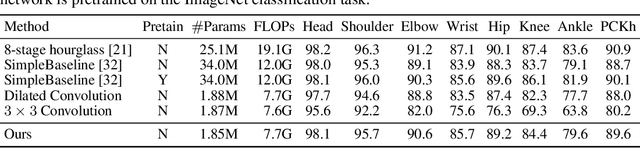
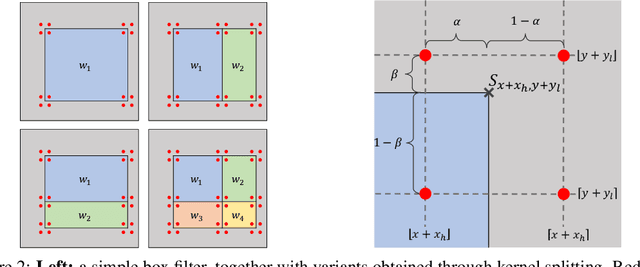
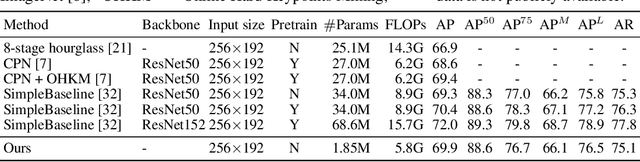
Expanding the receptive field to capture large-scale context is key to obtaining good performance in dense prediction tasks, such as human pose estimation. While many state-of-the-art fully-convolutional architectures enlarge the receptive field by reducing resolution using strided convolution or pooling layers, the most straightforward strategy is adopting large filters. This, however, is costly because of the quadratic increase in the number of parameters and multiply-add operations. In this work, we explore using learnable box filters to allow for convolution with arbitrarily large kernel size, while keeping the number of parameters per filter constant. In addition, we use precomputed summed-area tables to make the computational cost of convolution independent of the filter size. We adapt and incorporate the box filter as a differentiable module in a fully-convolutional neural network, and demonstrate its competitive performance on popular benchmarks for the task of human pose estimation.
High-Precision Localization Using Ground Texture
Sep 18, 2018


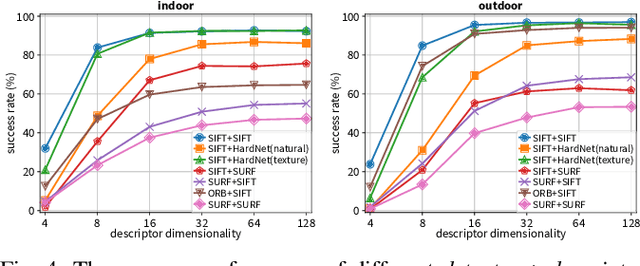
Location-aware applications play an increasingly critical role in everyday life. However, satellite-based localization (e.g., GPS) has limited accuracy and can be unusable in dense urban areas and indoors. We introduce an image-based global localization system that is accurate to a few millimeters and performs reliable localization both indoors and outside. The key idea is to capture and index distinctive local keypoints in ground textures. This is based on the observation that ground textures including wood, carpet, tile, concrete, and asphalt may look random and homogeneous, but all contain cracks, scratches, or unique arrangements of fibers. These imperfections are persistent, and can serve as local features. Our system incorporates a downward-facing camera to capture the fine texture of the ground, together with an image processing pipeline that locates the captured texture patch in a compact database constructed offline. We demonstrate the capability of our system to robustly, accurately, and quickly locate test images on various types of outdoor and indoor ground surfaces.