 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaper Agents, Paper Gains: An Empirical Analysis of DeFi Investment Agents
May 27, 2026DeFi investment agents, systems that use AI for autonomous on-chain trading, have attained over USD 3 billion in combined token valuations since late 2024. We survey over 1,900 AI-tagged crypto projects, filter to investment-focused agents, and curate 10 representative projects spanning strategy and observability dimensions. We then conduct a deep-dive architectural analysis of two prominent agent frameworks, ElizaOS and Virtuals Protocol, and a quantitative on-chain performance analysis of 11 Solana-based agent treasuries with publicly attributable trading activity, covering 925,323 token holders. We find that current deployments remain early and heterogeneous: (1) in our sample, many projects do not yet provide clear evidence of autonomous trade execution, and developer interviews suggest that many visible deployments remain basic API integrations; (2) agent treasuries retain over USD 30M in paper gains while token holders collectively lost USD 191.7M, with the top 1% of wallets capturing 81.4% of all gains (USD 1.81B); (3) token valuations are weakly connected to treasury fundamentals, with market-cap-to-AUM ratios exceeding 10,000x versus below 1x for established DeFi protocols; and (4) aggregate user gains peaked at USD 2.4B before declining to net losses, with median returns negative on every platform and tokens declining 93% on average from all-time highs. We interpret these outcomes as characteristic of a permissionless, first-generation market in which open infrastructure enables rapid experimentation but also allows naive or speculative agents to launch before robust standards for autonomy, performance, and stakeholder alignment emerge. We therefore propose a maturity framework along three dimensions: autonomous execution, risk-adjusted profitability, and stakeholder alignment, to characterize the gap between current deployments and future investment-grade agent systems.
EgoPoseFormer v2: Accurate Egocentric Human Motion Estimation for AR/VR
Mar 04, 2026Egocentric human motion estimation is essential for AR/VR experiences, yet remains challenging due to limited body coverage from the egocentric viewpoint, frequent occlusions, and scarce labeled data. We present EgoPoseFormer v2, a method that addresses these challenges through two key contributions: (1) a transformer-based model for temporally consistent and spatially grounded body pose estimation, and (2) an auto-labeling system that enables the use of large unlabeled datasets for training. Our model is fully differentiable, introduces identity-conditioned queries, multi-view spatial refinement, causal temporal attention, and supports both keypoints and parametric body representations under a constant compute budget. The auto-labeling system scales learning to tens of millions of unlabeled frames via uncertainty-aware semi-supervised training. The system follows a teacher-student schema to generate pseudo-labels and guide training with uncertainty distillation, enabling the model to generalize to different environments. On the EgoBody3M benchmark, with a 0.8 ms latency on GPU, our model outperforms two state-of-the-art methods by 12.2% and 19.4% in accuracy, and reduces temporal jitter by 22.2% and 51.7%. Furthermore, our auto-labeling system further improves the wrist MPJPE by 13.1%.
LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Geometric Neural Distance Fields for Learning Human Motion Priors
Sep 11, 2025We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
Painting Many Pasts: Synthesizing Time Lapse Videos of Paintings
Jan 04, 2020
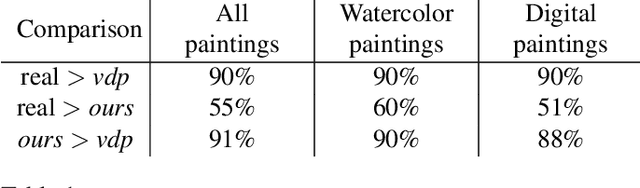
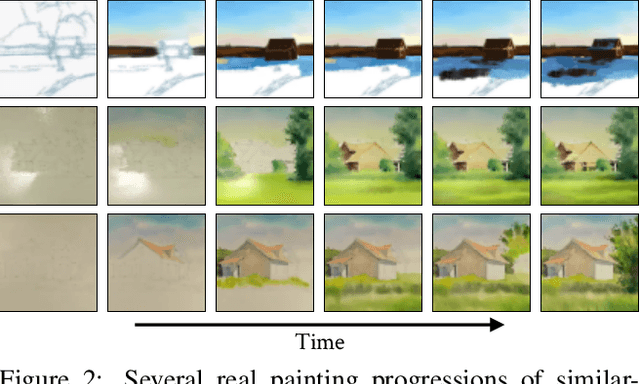
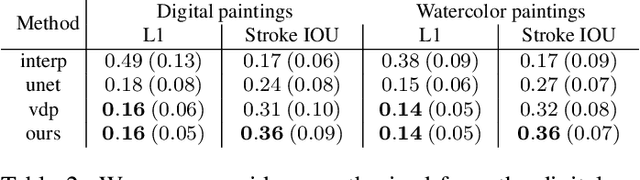
We introduce a new video synthesis task: synthesizing time lapse videos depicting how a given painting might have been created. Artists paint using unique combinations of brushes, strokes, colors, and layers. There are often many possible ways to create a given painting. Our goal is to learn to capture this rich range of possibilities. Creating distributions of long-term videos is a challenge for learning-based video synthesis methods. We present a probabilistic model that, given a single image of a completed painting, recurrently synthesizes steps of the painting process. We implement this model as a convolutional neural network, and introduce a training scheme to facilitate learning from a limited dataset of painting time lapses. We demonstrate that this model can be used to sample many time steps, enabling long-term stochastic video synthesis. We evaluate our method on digital and watercolor paintings collected from video websites, and show that human raters find our synthesized videos to be similar to time lapses produced by real artists.
Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions
Sep 01, 2019
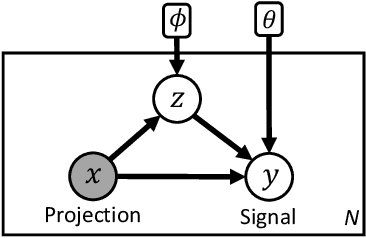
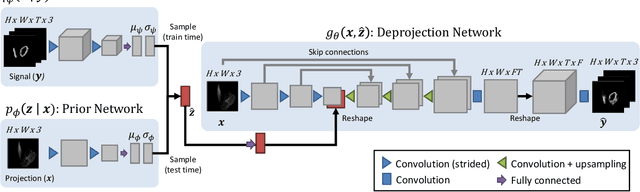

We introduce visual deprojection: the task of recovering an image or video that has been collapsed along a dimension. Projections arise in various contexts, such as long-exposure photography, where a dynamic scene is collapsed in time to produce a motion-blurred image, and corner cameras, where reflected light from a scene is collapsed along a spatial dimension because of an edge occluder to yield a 1D video. Deprojection is ill-posed-- often there are many plausible solutions for a given input. We first propose a probabilistic model capturing the ambiguity of the task. We then present a variational inference strategy using convolutional neural networks as functional approximators. Sampling from the inference network at test time yields plausible candidates from the distribution of original signals that are consistent with a given input projection. We evaluate the method on several datasets for both spatial and temporal deprojection tasks. We first demonstrate the method can recover human gait videos and face images from spatial projections, and then show that it can recover videos of moving digits from dramatically motion-blurred images obtained via temporal projection.
Data augmentation using learned transformations for one-shot medical image segmentation
Apr 06, 2019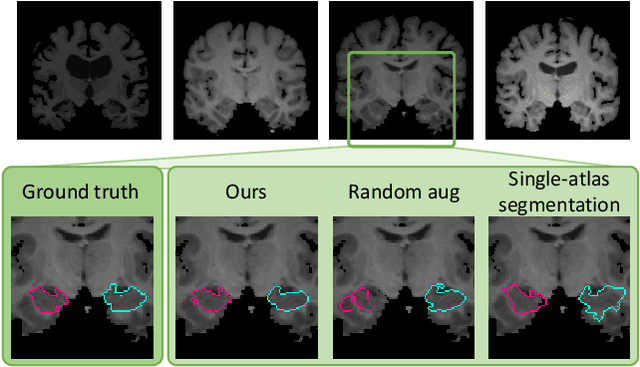
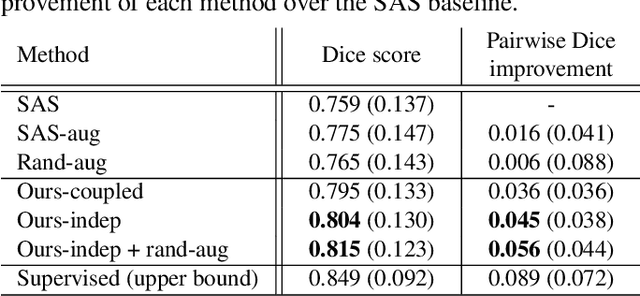
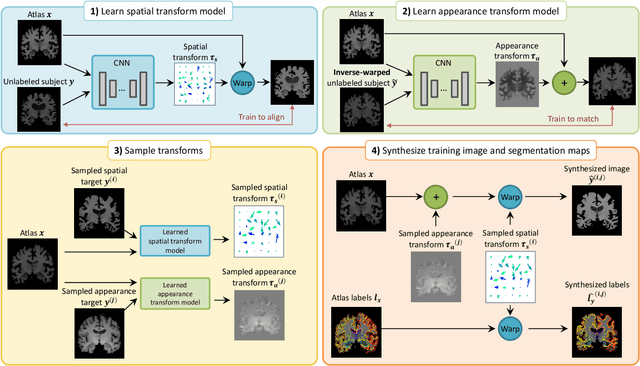
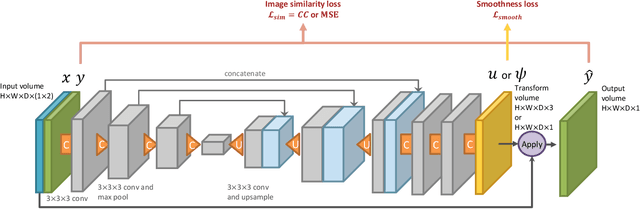
Image segmentation is an important task in many medical applications. Methods based on convolutional neural networks attain state-of-the-art accuracy; however, they typically rely on supervised training with large labeled datasets. Labeling medical images requires significant expertise and time, and typical hand-tuned approaches for data augmentation fail to capture the complex variations in such images. We present an automated data augmentation method for synthesizing labeled medical images. We demonstrate our method on the task of segmenting magnetic resonance imaging (MRI) brain scans. Our method requires only a single segmented scan, and leverages other unlabeled scans in a semi-supervised approach. We learn a model of transformations from the images, and use the model along with the labeled example to synthesize additional labeled examples. Each transformation is comprised of a spatial deformation field and an intensity change, enabling the synthesis of complex effects such as variations in anatomy and image acquisition procedures. We show that training a supervised segmenter with these new examples provides significant improvements over state-of-the-art methods for one-shot biomedical image segmentation. Our code is available at https://github.com/xamyzhao/brainstorm.
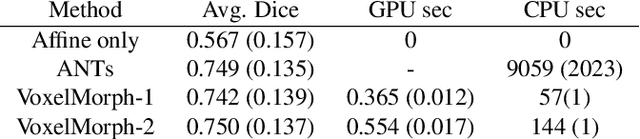
VoxelMorph: A Learning Framework for Deformable Medical Image Registration
Sep 14, 2018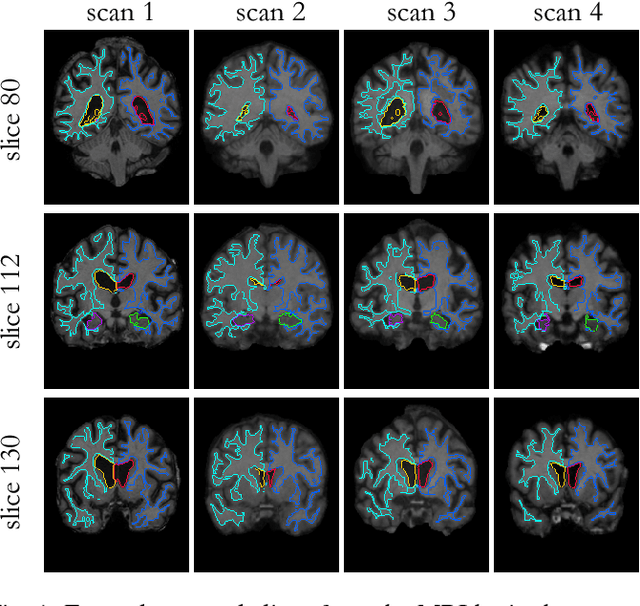
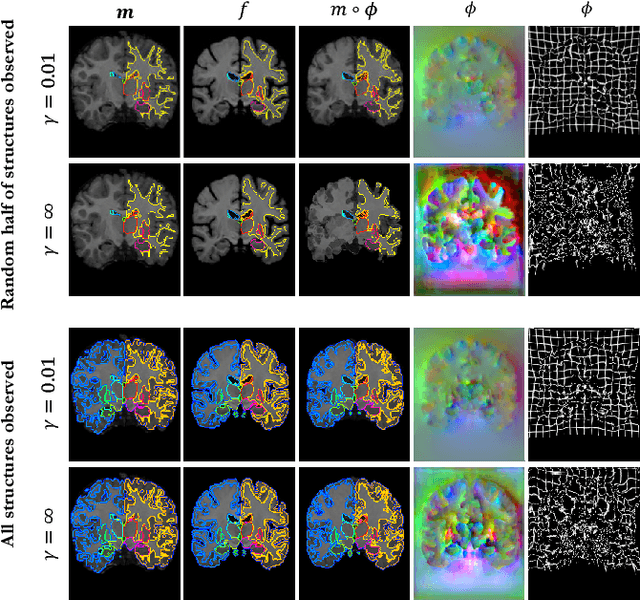
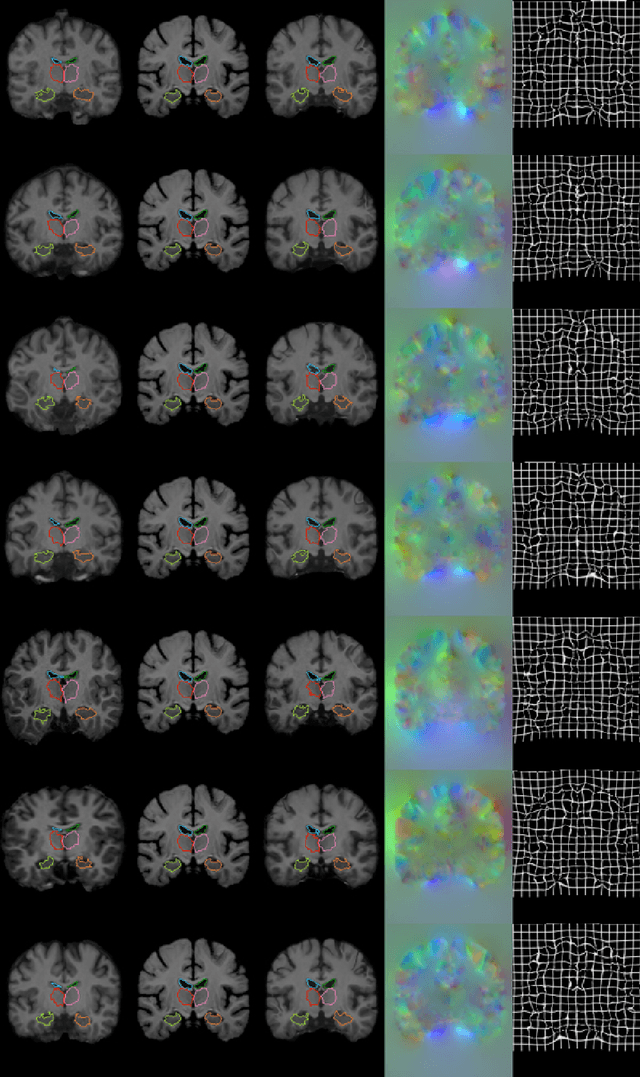
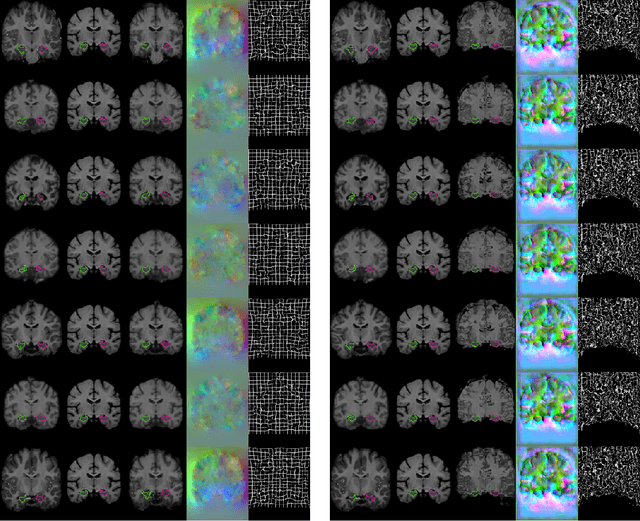
We present VoxelMorph, a fast, unsupervised, learning-based algorithm for deformable pairwise medical image registration. Traditional registration methods optimize an objective function independently for each pair of images, which is time-consuming for large datasets. We define registration as a parametric function, implemented as a convolutional neural network (CNN). We optimize its global parameters given a set of images from a collection of interest. Given a new pair of scans, VoxelMorph rapidly computes a deformation field by directly evaluating the function. Our model is flexible, enabling the use of any differentiable objective function to optimize these parameters. In this work, we propose and extensively evaluate a standard image matching objective function as well as an objective function that can use auxiliary data such as anatomical segmentations available only at training time. We demonstrate that the unsupervised model's accuracy is comparable to state-of-the-art methods, while operating orders of magnitude faster. We also show that VoxelMorph trained with auxiliary data significantly improves registration accuracy at test time. Our method promises to significantly speed up medical image analysis and processing pipelines, while facilitating novel directions in learning-based registration and its applications. Our code is freely available at voxelmorph.csail.mit.edu.
An Unsupervised Learning Model for Deformable Medical Image Registration
Apr 20, 2018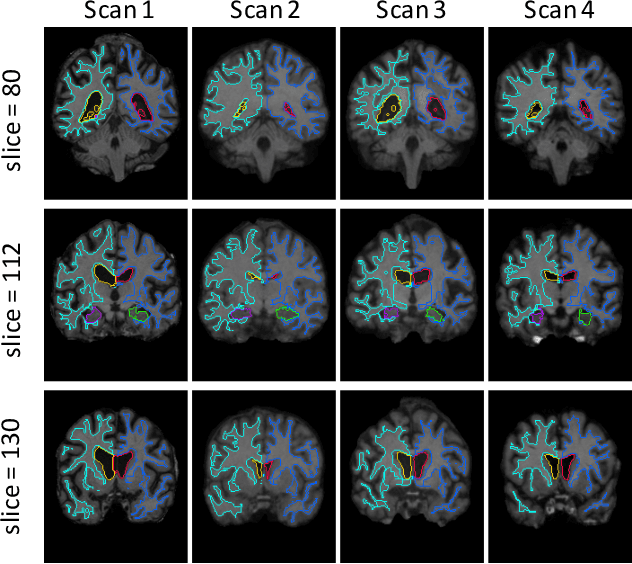
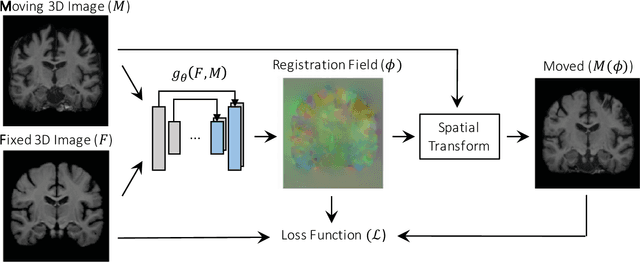
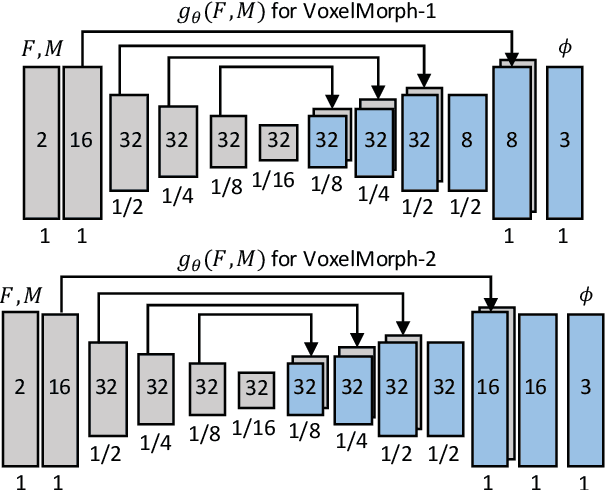
We present a fast learning-based algorithm for deformable, pairwise 3D medical image registration. Current registration methods optimize an objective function independently for each pair of images, which can be time-consuming for large data. We define registration as a parametric function, and optimize its parameters given a set of images from a collection of interest. Given a new pair of scans, we can quickly compute a registration field by directly evaluating the function using the learned parameters. We model this function using a convolutional neural network (CNN), and use a spatial transform layer to reconstruct one image from another while imposing smoothness constraints on the registration field. The proposed method does not require supervised information such as ground truth registration fields or anatomical landmarks. We demonstrate registration accuracy comparable to state-of-the-art 3D image registration, while operating orders of magnitude faster in practice. Our method promises to significantly speed up medical image analysis and processing pipelines, while facilitating novel directions in learning-based registration and its applications. Our code is available at https://github.com/balakg/voxelmorph .