 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJParc: Joint cortical surface parcellation with registration
Dec 27, 2025Cortical surface parcellation is a fundamental task in both basic neuroscience research and clinical applications, enabling more accurate mapping of brain regions. Model-based and learning-based approaches for automated parcellation alleviate the need for manual labeling. Despite the advancement in parcellation performance, learning-based methods shift away from registration and atlas propagation without exploring the reason for the improvement compared to traditional methods. In this study, we present JParc, a joint cortical registration and parcellation framework, that outperforms existing state-of-the-art parcellation methods. In rigorous experiments, we demonstrate that the enhanced performance of JParc is primarily attributable to accurate cortical registration and a learned parcellation atlas. By leveraging a shallow subnetwork to fine-tune the propagated atlas labels, JParc achieves a Dice score greater than 90% on the Mindboggle dataset, using only basic geometric features (sulcal depth, curvature) that describe cortical folding patterns. The superior accuracy of JParc can significantly increase the statistical power in brain mapping studies as well as support applications in surgical planning and many other downstream neuroscientific and clinical tasks.
Pancakes: Consistent Multi-Protocol Image Segmentation Across Biomedical Domains
Dec 15, 2025A single biomedical image can be meaningfully segmented in multiple ways, depending on the desired application. For instance, a brain MRI can be segmented according to tissue types, vascular territories, broad anatomical regions, fine-grained anatomy, or pathology, etc. Existing automatic segmentation models typically either (1) support only a single protocol, the one they were trained on, or (2) require labor-intensive manual prompting to specify the desired segmentation. We introduce Pancakes, a framework that, given a new image from a previously unseen domain, automatically generates multi-label segmentation maps for multiple plausible protocols, while maintaining semantic consistency across related images. Pancakes introduces a new problem formulation that is not currently attainable by existing foundation models. In a series of experiments on seven held-out datasets, we demonstrate that our model can significantly outperform existing foundation models in producing several plausible whole-image segmentations, that are semantically coherent across images.
AtlasMorph: Learning conditional deformable templates for brain MRI
Nov 17, 2025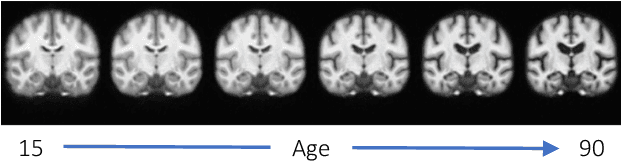
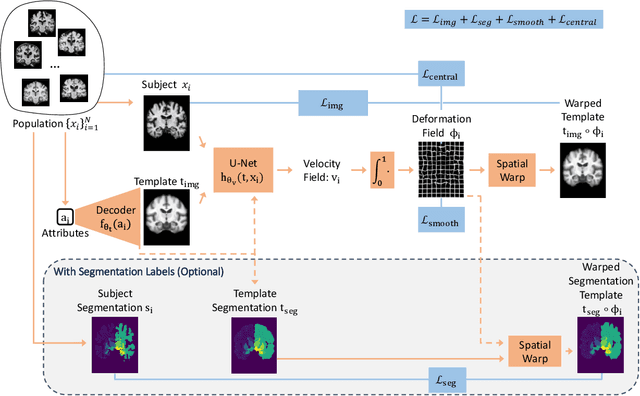
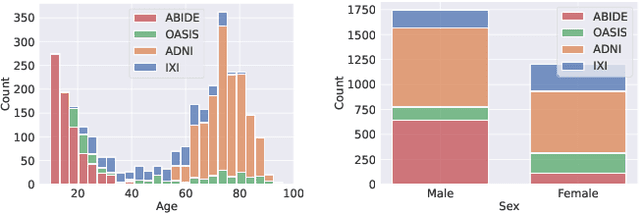
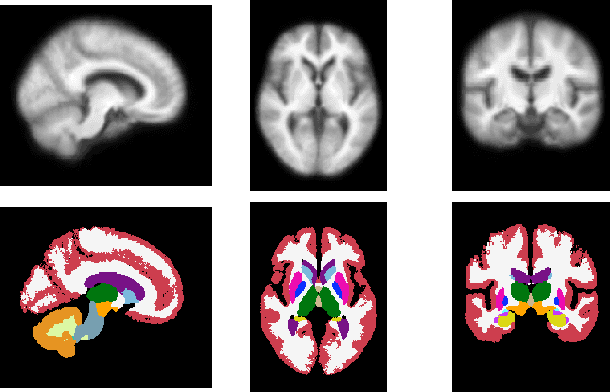
Deformable templates, or atlases, are images that represent a prototypical anatomy for a population, and are often enhanced with probabilistic anatomical label maps. They are commonly used in medical image analysis for population studies and computational anatomy tasks such as registration and segmentation. Because developing a template is a computationally expensive process, relatively few templates are available. As a result, analysis is often conducted with sub-optimal templates that are not truly representative of the study population, especially when there are large variations within this population. We propose a machine learning framework that uses convolutional registration neural networks to efficiently learn a function that outputs templates conditioned on subject-specific attributes, such as age and sex. We also leverage segmentations, when available, to produce anatomical segmentation maps for the resulting templates. The learned network can also be used to register subject images to the templates. We demonstrate our method on a compilation of 3D brain MRI datasets, and show that it can learn high-quality templates that are representative of populations. We find that annotated conditional templates enable better registration than their unlabeled unconditional counterparts, and outperform other templates construction methods.
MultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance
Dec 19, 2024Medical researchers and clinicians often need to perform novel segmentation tasks on a set of related images. Existing methods for segmenting a new dataset are either interactive, requiring substantial human effort for each image, or require an existing set of manually labeled images. We introduce a system, MultiverSeg, that enables practitioners to rapidly segment an entire new dataset without requiring access to any existing labeled data from that task or domain. Along with the image to segment, the model takes user interactions such as clicks, bounding boxes or scribbles as input, and predicts a segmentation. As the user segments more images, those images and segmentations become additional inputs to the model, providing context. As the context set of labeled images grows, the number of interactions required to segment each new image decreases. We demonstrate that MultiverSeg enables users to interactively segment new datasets efficiently, by amortizing the number of interactions per image to achieve an accurate segmentation. Compared to using a state-of-the-art interactive segmentation method, using MultiverSeg reduced the total number of scribble steps by 53% and clicks by 36% to achieve 90% Dice on sets of images from unseen tasks. We release code and model weights at https://multiverseg.csail.mit.edu
Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
Nov 04, 2024



Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network's features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.
VoxelPrompt: A Vision-Language Agent for Grounded Medical Image Analysis
Oct 10, 2024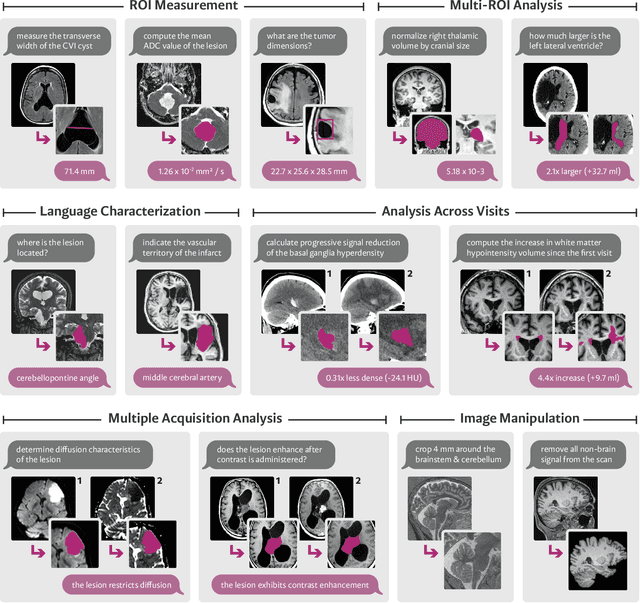
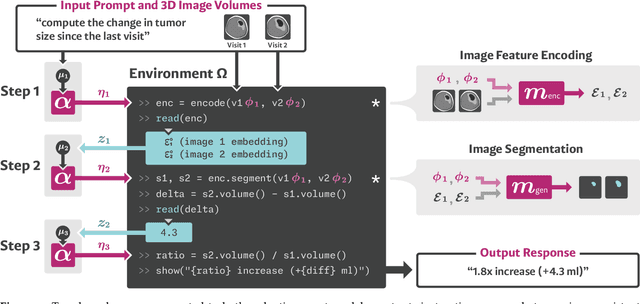
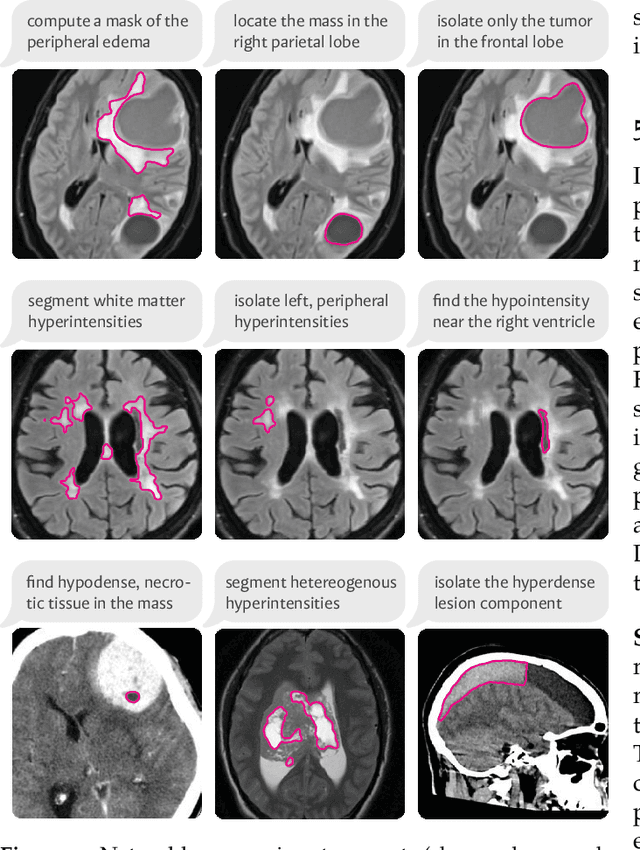
We present VoxelPrompt, an agent-driven vision-language framework that tackles diverse radiological tasks through joint modeling of natural language, image volumes, and analytical metrics. VoxelPrompt is multi-modal and versatile, leveraging the flexibility of language interaction while providing quantitatively grounded image analysis. Given a variable number of 3D medical volumes, such as MRI and CT scans, VoxelPrompt employs a language agent that iteratively predicts executable instructions to solve a task specified by an input prompt. These instructions communicate with a vision network to encode image features and generate volumetric outputs (e.g., segmentations). VoxelPrompt interprets the results of intermediate instructions and plans further actions to compute discrete measures (e.g., tumor growth across a series of scans) and present relevant outputs to the user. We evaluate this framework in a sandbox of diverse neuroimaging tasks, and we show that the single VoxelPrompt model can delineate hundreds of anatomical and pathological features, measure many complex morphological properties, and perform open-language analysis of lesion characteristics. VoxelPrompt carries out these objectives with accuracy similar to that of fine-tuned, single-task models for segmentation and visual question-answering, while facilitating a much larger range of tasks. Therefore, by supporting accurate image processing with language interaction, VoxelPrompt provides comprehensive utility for numerous imaging tasks that traditionally require specialized models to address.
Boosting Skull-Stripping Performance for Pediatric Brain Images
Feb 26, 2024



Skull-stripping is the removal of background and non-brain anatomical features from brain images. While many skull-stripping tools exist, few target pediatric populations. With the emergence of multi-institutional pediatric data acquisition efforts to broaden the understanding of perinatal brain development, it is essential to develop robust and well-tested tools ready for the relevant data processing. However, the broad range of neuroanatomical variation in the developing brain, combined with additional challenges such as high motion levels, as well as shoulder and chest signal in the images, leaves many adult-specific tools ill-suited for pediatric skull-stripping. Building on an existing framework for robust and accurate skull-stripping, we propose developmental SynthStrip (d-SynthStrip), a skull-stripping model tailored to pediatric images. This framework exposes networks to highly variable images synthesized from label maps. Our model substantially outperforms pediatric baselines across scan types and age cohorts. In addition, the <1-minute runtime of our tool compares favorably to the fastest baselines. We distribute our model at https://w3id.org/synthstrip.
Tyche: Stochastic In-Context Learning for Medical Image Segmentation
Jan 24, 2024



Existing learning-based solutions to medical image segmentation have two important shortcomings. First, for most new segmentation task, a new model has to be trained or fine-tuned. This requires extensive resources and machine learning expertise, and is therefore often infeasible for medical researchers and clinicians. Second, most existing segmentation methods produce a single deterministic segmentation mask for a given image. In practice however, there is often considerable uncertainty about what constitutes the correct segmentation, and different expert annotators will often segment the same image differently. We tackle both of these problems with Tyche, a model that uses a context set to generate stochastic predictions for previously unseen tasks without the need to retrain. Tyche differs from other in-context segmentation methods in two important ways. (1) We introduce a novel convolution block architecture that enables interactions among predictions. (2) We introduce in-context test-time augmentation, a new mechanism to provide prediction stochasticity. When combined with appropriate model design and loss functions, Tyche can predict a set of plausible diverse segmentation candidates for new or unseen medical images and segmentation tasks without the need to retrain.
ScribblePrompt: Fast and Flexible Interactive Segmentation for Any Medical Image
Dec 12, 2023Semantic medical image segmentation is a crucial part of both scientific research and clinical care. With enough labelled data, deep learning models can be trained to accurately automate specific medical image segmentation tasks. However, manually segmenting images to create training data is highly labor intensive. In this paper, we present ScribblePrompt, an interactive segmentation framework for medical imaging that enables human annotators to segment unseen structures using scribbles, clicks, and bounding boxes. Scribbles are an intuitive and effective form of user interaction for complex tasks, however most existing methods focus on click-based interactions. We introduce algorithms for simulating realistic scribbles that enable training models that are amenable to multiple types of interaction. To achieve generalization to new tasks, we train on a diverse collection of 65 open-access biomedical datasets -- using both real and synthetic labels. We test ScribblePrompt on multiple network architectures and unseen datasets, and demonstrate that it can be used in real-time on a single CPU. We evaluate ScribblePrompt using manually-collected scribbles, simulated interactions, and a user study. ScribblePrompt outperforms existing methods in all our evaluations. In the user study, ScribblePrompt reduced annotation time by 28% while improving Dice by 15% compared to existing methods. We showcase ScribblePrompt in an online demo and provide code at https://scribbleprompt.csail.mit.edu
GIST: Generating Image-Specific Text for Fine-grained Object Classification
Aug 04, 2023



Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.