 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking of Deep Learning Methods for Generic MRI Multi-OrganAbdominal Segmentation
Jul 23, 2025Recent advances in deep learning have led to robust automated tools for segmentation of abdominal computed tomography (CT). Meanwhile, segmentation of magnetic resonance imaging (MRI) is substantially more challenging due to the inherent signal variability and the increased effort required for annotating training datasets. Hence, existing approaches are trained on limited sets of MRI sequences, which might limit their generalizability. To characterize the landscape of MRI abdominal segmentation tools, we present here a comprehensive benchmarking of the three state-of-the-art and open-source models: MRSegmentator, MRISegmentator-Abdomen, and TotalSegmentator MRI. Since these models are trained using labor-intensive manual annotation cycles, we also introduce and evaluate ABDSynth, a SynthSeg-based model purely trained on widely available CT segmentations (no real images). More generally, we assess accuracy and generalizability by leveraging three public datasets (not seen by any of the evaluated methods during their training), which span all major manufacturers, five MRI sequences, as well as a variety of subject conditions, voxel resolutions, and fields-of-view. Our results reveal that MRSegmentator achieves the best performance and is most generalizable. In contrast, ABDSynth yields slightly less accurate results, but its relaxed requirements in training data make it an alternative when the annotation budget is limited. The evaluation code and datasets are given for future benchmarking at https://github.com/deepakri201/AbdoBench, along with inference code and weights for ABDSynth.
Spatial regularisation for improved accuracy and interpretability in keypoint-based registration
Mar 07, 2025Unsupervised registration strategies bypass requirements in ground truth transforms or segmentations by optimising similarity metrics between fixed and moved volumes. Among these methods, a recent subclass of approaches based on unsupervised keypoint detection stand out as very promising for interpretability. Specifically, these methods train a network to predict feature maps for fixed and moving images, from which explainable centres of mass are computed to obtain point clouds, that are then aligned in closed-form. However, the features returned by the network often yield spatially diffuse patterns that are hard to interpret, thus undermining the purpose of keypoint-based registration. Here, we propose a three-fold loss to regularise the spatial distribution of the features. First, we use the KL divergence to model features as point spread functions that we interpret as probabilistic keypoints. Then, we sharpen the spatial distributions of these features to increase the precision of the detected landmarks. Finally, we introduce a new repulsive loss across keypoints to encourage spatial diversity. Overall, our loss considerably improves the interpretability of the features, which now correspond to precise and anatomically meaningful landmarks. We demonstrate our three-fold loss in foetal rigid motion tracking and brain MRI affine registration tasks, where it not only outperforms state-of-the-art unsupervised strategies, but also bridges the gap with state-of-the-art supervised methods. Our code is available at https://github.com/BenBillot/spatial_regularisation.
A Constrast-Agnostic Method for Ultra-High Resolution Claustrum Segmentation
Nov 23, 2024



The claustrum is a band-like gray matter structure located between putamen and insula whose exact functions are still actively researched. Its sheet-like structure makes it barely visible in in vivo Magnetic Resonance Imaging (MRI) scans at typical resolutions and neuroimaging tools for its study, including methods for automatic segmentation, are currently very limited. In this paper, we propose a contrast- and resolution-agnostic method for claustrum segmentation at ultra-high resolution (0.35 mm isotropic); the method is based on the SynthSeg segmentation framework (Billot et al., 2023), which leverages the use of synthetic training intensity images to achieve excellent generalization. In particular, SynthSeg requires only label maps to be trained, since corresponding intensity images are synthesized on the fly with random contrast and resolution. We trained a deep learning network for automatic claustrum segmentation, using claustrum manual labels obtained from 18 ultra-high resolution MRI scans (mostly ex vivo). We demonstrated the method to work on these 18 high resolution cases (Dice score = 0.632, mean surface distance = 0.458 mm, and volumetric similarity = 0.867 using 6-fold Cross Validation (CV)), and also on in vivo T1-weighted MRI scans at typical resolutions (~1 mm isotropic). We also demonstrated that the method is robust in a test-retest setting and when applied to multimodal imaging (T2-weighted, Proton Density and quantitative T1 scans). To the best of our knowledge this is the first accurate method for automatic ultra-high resolution claustrum segmentation, which is robust against changes in contrast and resolution. The method is released at https://github.com/chiara-mauri/claustrum_segmentation and as part of the neuroimaging package Freesurfer (Fischl, 2012).
Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
Nov 04, 2024



Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network's features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.
Towards Automatic Abdominal MRI Organ Segmentation: Leveraging Synthesized Data Generated From CT Labels
Mar 22, 2024

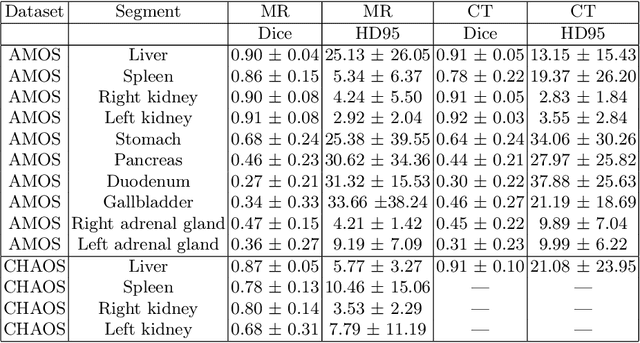
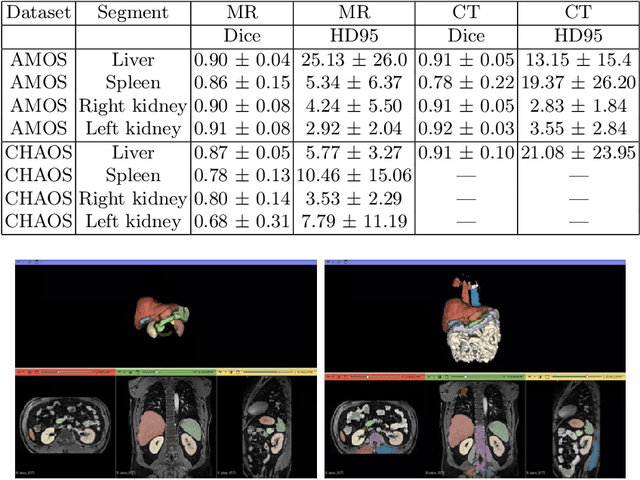
Deep learning has shown great promise in the ability to automatically annotate organs in magnetic resonance imaging (MRI) scans, for example, of the brain. However, despite advancements in the field, the ability to accurately segment abdominal organs remains difficult across MR. In part, this may be explained by the much greater variability in image appearance and severely limited availability of training labels. The inherent nature of computed tomography (CT) scans makes it easier to annotate, resulting in a larger availability of expert annotations for the latter. We leverage a modality-agnostic domain randomization approach, utilizing CT label maps to generate synthetic images on-the-fly during training, further used to train a U-Net segmentation network for abdominal organs segmentation. Our approach shows comparable results compared to fully-supervised segmentation methods trained on MR data. Our method results in Dice scores of 0.90 (0.08) and 0.91 (0.08) for the right and left kidney respectively, compared to a pretrained nnU-Net model yielding 0.87 (0.20) and 0.91 (0.03). We will make our code publicly available.
SE-Equivariant and Noise-Invariant 3D Motion Tracking in Medical Images
Dec 21, 2023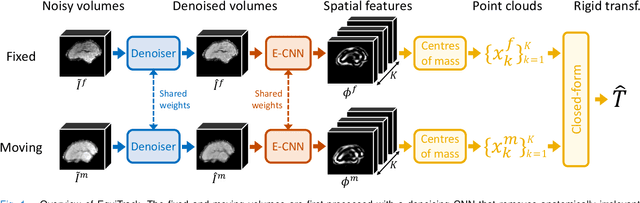
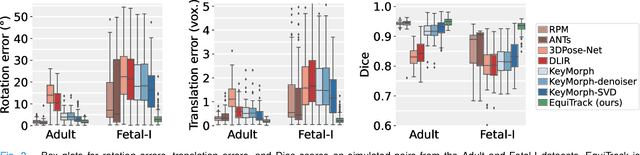
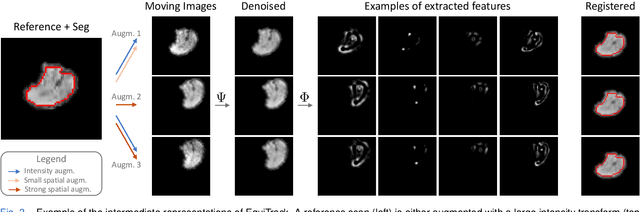
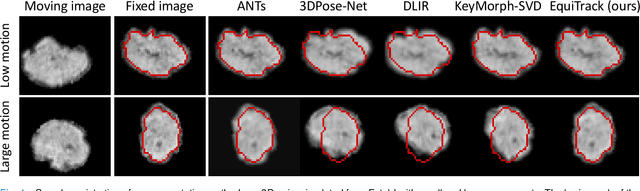
Rigid motion tracking is paramount in many medical imaging applications where movements need to be detected, corrected, or accounted for. Modern strategies rely on convolutional neural networks (CNN) and pose this problem as rigid registration. Yet, CNNs do not exploit natural symmetries in this task, as they are equivariant to translations (their outputs shift with their inputs) but not to rotations. Here we propose EquiTrack, the first method that uses recent steerable SE(3)-equivariant CNNs (E-CNN) for motion tracking. While steerable E-CNNs can extract corresponding features across different poses, testing them on noisy medical images reveals that they do not have enough learning capacity to learn noise invariance. Thus, we introduce a hybrid architecture that pairs a denoiser with an E-CNN to decouple the processing of anatomically irrelevant intensity features from the extraction of equivariant spatial features. Rigid transforms are then estimated in closed-form. EquiTrack outperforms state-of-the-art learning and optimisation methods for motion tracking in adult brain MRI and fetal MRI time series. Our code is available at github.com/BBillot/equitrack.
Quantifying white matter hyperintensity and brain volumes in heterogeneous clinical and low-field portable MRI
Dec 08, 2023
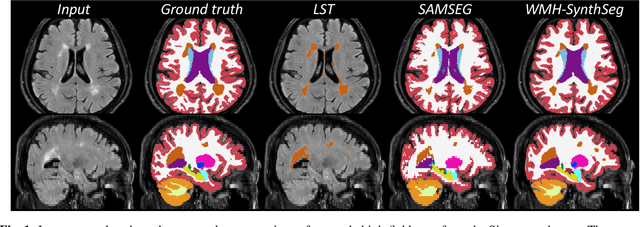
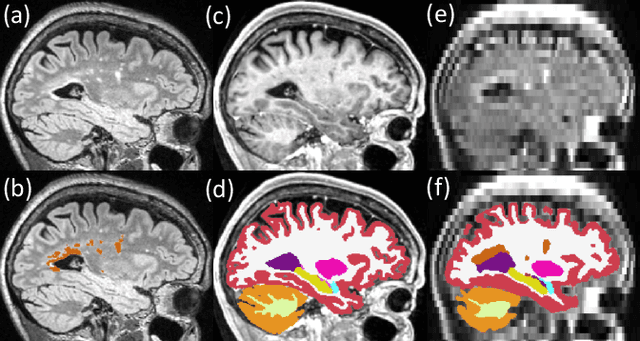

Brain atrophy and white matter hyperintensity (WMH) are critical neuroimaging features for ascertaining brain injury in cerebrovascular disease and multiple sclerosis. Automated segmentation and quantification is desirable but existing methods require high-resolution MRI with good signal-to-noise ratio (SNR). This precludes application to clinical and low-field portable MRI (pMRI) scans, thus hampering large-scale tracking of atrophy and WMH progression, especially in underserved areas where pMRI has huge potential. Here we present a method that segments white matter hyperintensity and 36 brain regions from scans of any resolution and contrast (including pMRI) without retraining. We show results on six public datasets and on a private dataset with paired high- and low-field scans (3T and 64mT), where we attain strong correlation between the WMH ($\rho$=.85) and hippocampal volumes (r=.89) estimated at both fields. Our method is publicly available as part of FreeSurfer, at: http://surfer.nmr.mgh.harvard.edu/fswiki/WMH-SynthSeg.
AnyStar: Domain randomized universal star-convex 3D instance segmentation
Jul 13, 2023Star-convex shapes arise across bio-microscopy and radiology in the form of nuclei, nodules, metastases, and other units. Existing instance segmentation networks for such structures train on densely labeled instances for each dataset, which requires substantial and often impractical manual annotation effort. Further, significant reengineering or finetuning is needed when presented with new datasets and imaging modalities due to changes in contrast, shape, orientation, resolution, and density. We present AnyStar, a domain-randomized generative model that simulates synthetic training data of blob-like objects with randomized appearance, environments, and imaging physics to train general-purpose star-convex instance segmentation networks. As a result, networks trained using our generative model do not require annotated images from unseen datasets. A single network trained on our synthesized data accurately 3D segments C. elegans and P. dumerilii nuclei in fluorescence microscopy, mouse cortical nuclei in micro-CT, zebrafish brain nuclei in EM, and placental cotyledons in human fetal MRI, all without any retraining, finetuning, transfer learning, or domain adaptation. Code is available at https://github.com/neel-dey/AnyStar.
Domain-agnostic segmentation of thalamic nuclei from joint structural and diffusion MRI
May 05, 2023The human thalamus is a highly connected subcortical grey-matter structure within the brain. It comprises dozens of nuclei with different function and connectivity, which are affected differently by disease. For this reason, there is growing interest in studying the thalamic nuclei in vivo with MRI. Tools are available to segment the thalamus from 1 mm T1 scans, but the contrast of the lateral and internal boundaries is too faint to produce reliable segmentations. Some tools have attempted to incorporate information from diffusion MRI in the segmentation to refine these boundaries, but do not generalise well across diffusion MRI acquisitions. Here we present the first CNN that can segment thalamic nuclei from T1 and diffusion data of any resolution without retraining or fine tuning. Our method builds on a public histological atlas of the thalamic nuclei and silver standard segmentations on high-quality diffusion data obtained with a recent Bayesian adaptive segmentation tool. We combine these with an approximate degradation model for fast domain randomisation during training. Our CNN produces a segmentation at 0.7 mm isotropic resolution, irrespective of the resolution of the input. Moreover, it uses a parsimonious model of the diffusion signal at each voxel (fractional anisotropy and principal eigenvector) that is compatible with virtually any set of directions and b-values, including huge amounts of legacy data. We show results of our proposed method on three heterogeneous datasets acquired on dozens of different scanners. An implementation of the method is publicly available at https://freesurfer.net/fswiki/ThalamicNucleiDTI.
Robust machine learning segmentation for large-scale analysis of heterogeneous clinical brain MRI datasets
Sep 05, 2022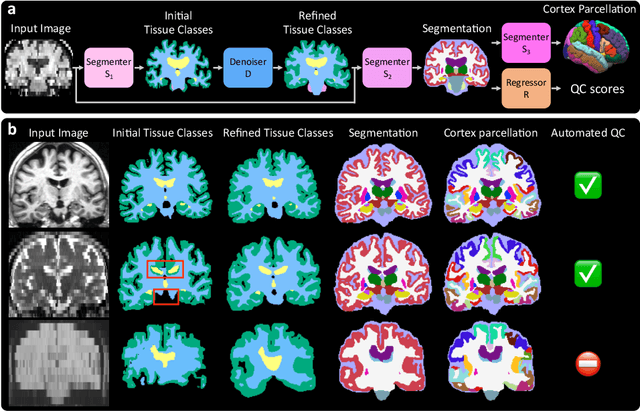
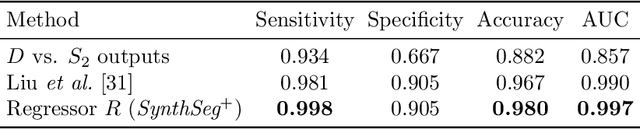
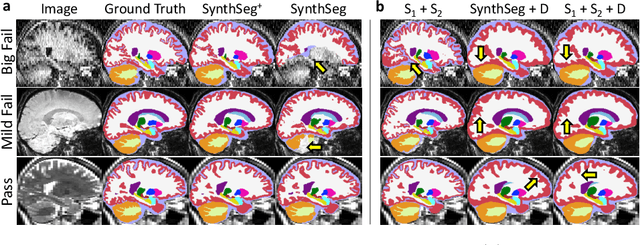

Every year, millions of brain MRI scans are acquired in hospitals, which is a figure considerably larger than the size of any research dataset. Therefore, the ability to analyse such scans could transform neuroimaging research. Yet, their potential remains untapped, since no automated algorithm can cope with the high variability in clinical acquisitions (MR contrast, resolution, orientation, etc.). Here we present SynthSeg+, an AI segmentation suite that enables, for the first time, robust analysis of heterogeneous clinical datasets. Specifically, in addition to whole-brain segmentation, SynthSeg+ also performs cortical parcellation, intracranial volume estimation, and automated detection of faulty segmentations (mainly caused by scans of very low quality). We demonstrate SynthSeg+ in seven experiments, including an ageing study on 14,000 scans, where it accurately replicates atrophy patterns observed on data of much higher quality. SynthSeg+ is publicly released as a ready-to-use tool to unlock the potential of quantitative morphometry in wide-ranging settings.