 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance
Dec 19, 2024Medical researchers and clinicians often need to perform novel segmentation tasks on a set of related images. Existing methods for segmenting a new dataset are either interactive, requiring substantial human effort for each image, or require an existing set of manually labeled images. We introduce a system, MultiverSeg, that enables practitioners to rapidly segment an entire new dataset without requiring access to any existing labeled data from that task or domain. Along with the image to segment, the model takes user interactions such as clicks, bounding boxes or scribbles as input, and predicts a segmentation. As the user segments more images, those images and segmentations become additional inputs to the model, providing context. As the context set of labeled images grows, the number of interactions required to segment each new image decreases. We demonstrate that MultiverSeg enables users to interactively segment new datasets efficiently, by amortizing the number of interactions per image to achieve an accurate segmentation. Compared to using a state-of-the-art interactive segmentation method, using MultiverSeg reduced the total number of scribble steps by 53% and clicks by 36% to achieve 90% Dice on sets of images from unseen tasks. We release code and model weights at https://multiverseg.csail.mit.edu
Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
Nov 04, 2024Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network's features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.
Tyche: Stochastic In-Context Learning for Medical Image Segmentation
Jan 24, 2024



Existing learning-based solutions to medical image segmentation have two important shortcomings. First, for most new segmentation task, a new model has to be trained or fine-tuned. This requires extensive resources and machine learning expertise, and is therefore often infeasible for medical researchers and clinicians. Second, most existing segmentation methods produce a single deterministic segmentation mask for a given image. In practice however, there is often considerable uncertainty about what constitutes the correct segmentation, and different expert annotators will often segment the same image differently. We tackle both of these problems with Tyche, a model that uses a context set to generate stochastic predictions for previously unseen tasks without the need to retrain. Tyche differs from other in-context segmentation methods in two important ways. (1) We introduce a novel convolution block architecture that enables interactions among predictions. (2) We introduce in-context test-time augmentation, a new mechanism to provide prediction stochasticity. When combined with appropriate model design and loss functions, Tyche can predict a set of plausible diverse segmentation candidates for new or unseen medical images and segmentation tasks without the need to retrain.
ScribblePrompt: Fast and Flexible Interactive Segmentation for Any Medical Image
Dec 12, 2023Semantic medical image segmentation is a crucial part of both scientific research and clinical care. With enough labelled data, deep learning models can be trained to accurately automate specific medical image segmentation tasks. However, manually segmenting images to create training data is highly labor intensive. In this paper, we present ScribblePrompt, an interactive segmentation framework for medical imaging that enables human annotators to segment unseen structures using scribbles, clicks, and bounding boxes. Scribbles are an intuitive and effective form of user interaction for complex tasks, however most existing methods focus on click-based interactions. We introduce algorithms for simulating realistic scribbles that enable training models that are amenable to multiple types of interaction. To achieve generalization to new tasks, we train on a diverse collection of 65 open-access biomedical datasets -- using both real and synthetic labels. We test ScribblePrompt on multiple network architectures and unseen datasets, and demonstrate that it can be used in real-time on a single CPU. We evaluate ScribblePrompt using manually-collected scribbles, simulated interactions, and a user study. ScribblePrompt outperforms existing methods in all our evaluations. In the user study, ScribblePrompt reduced annotation time by 28% while improving Dice by 15% compared to existing methods. We showcase ScribblePrompt in an online demo and provide code at https://scribbleprompt.csail.mit.edu
Categorical Co-Frequency Analysis: Clustering Diagnosis Codes to Predict Hospital Readmissions
Sep 01, 2019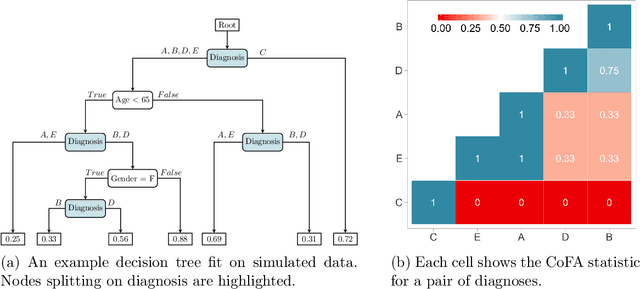

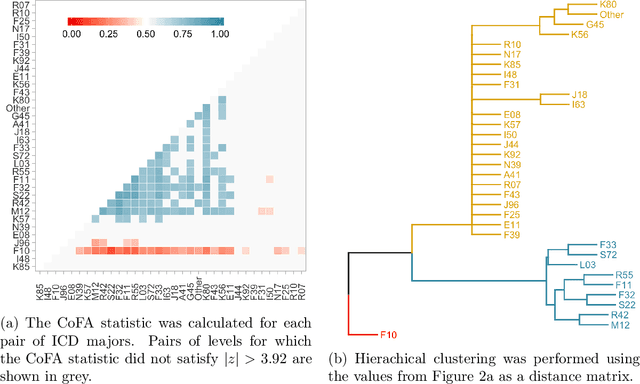
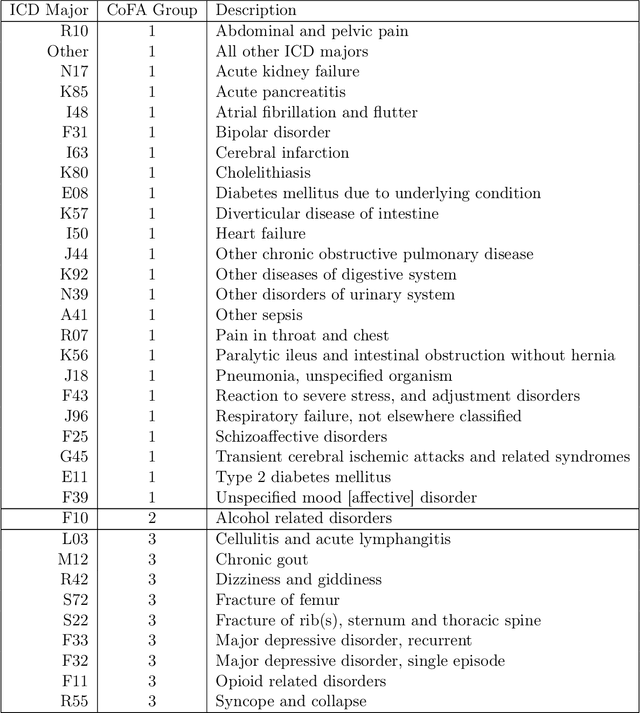
Accurately predicting patients' risk of 30-day hospital readmission would enable hospitals to efficiently allocate resource-intensive interventions. We develop a new method, Categorical Co-Frequency Analysis (CoFA), for clustering diagnosis codes from the International Classification of Diseases (ICD) according to the similarity in relationships between covariates and readmission risk. CoFA measures the similarity between diagnoses by the frequency with which two diagnoses are split in the same direction versus split apart in random forests to predict readmission risk. Applying CoFA to de-identified data from Berkshire Medical Center, we identified three groups of diagnoses that vary in readmission risk. To evaluate CoFA, we compared readmission risk models using ICD majors and CoFA groups to a baseline model without diagnosis variables. We found substituting ICD majors for the CoFA-identified clusters simplified the model without compromising the accuracy of predictions. Fitting separate models for each ICD major and CoFA group did not improve predictions, suggesting that readmission risk may be more homogeneous that heterogeneous across diagnosis groups.
Markerless Augmented Advertising for Sports Videos
Jul 22, 2019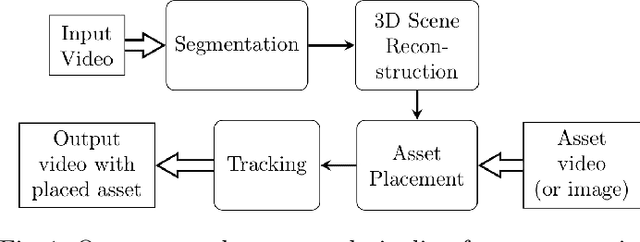

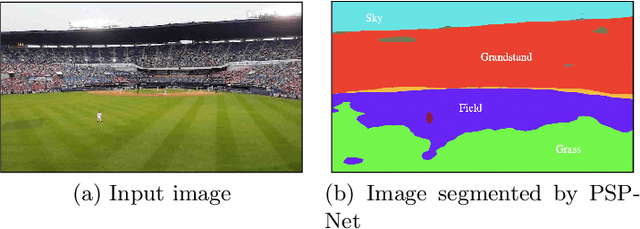

Markerless augmented reality can be a challenging computer vision task, especially in live broadcast settings and in the absence of information related to the video capture such as the intrinsic camera parameters. This typically requires the assistance of a skilled artist, along with the use of advanced video editing tools in a post-production environment. We present an automated video augmentation pipeline that identifies textures of interest and overlays an advertisement onto these regions. We constrain the advertisement to be placed in a way that is aesthetic and natural. The aim is to augment the scene such that there is no longer a need for commercial breaks. In order to achieve seamless integration of the advertisement with the original video we build a 3D representation of the scene, place the advertisement in 3D, and then project it back onto the image plane. After successful placement in a single frame, we use homography-based, shape-preserving tracking such that the advertisement appears perspective correct for the duration of a video clip. The tracker is designed to handle smooth camera motion and shot boundaries.