 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Signed Distance Functions for Kinematic Collision Bodies
Nov 11, 2024



We present learning-based implicit shape representations designed for real-time avatar collision queries arising in the simulation of clothing. Signed distance functions (SDFs) have been used for such queries for many years due to their computational efficiency. Recently deep neural networks have been used for implicit shape representations (DeepSDFs) due to their ability to represent multiple shapes with modest memory requirements compared to traditional representations over dense grids. However, the computational expense of DeepSDFs prevents their use in real-time clothing simulation applications. We design a learning-based representation of SDFs for human avatars whoes bodies change shape kinematically due to joint-based skinning. Rather than using a single DeepSDF for the entire avatar, we use a collection of extremely computationally efficient (shallow) neural networks that represent localized deformations arising from changes in body shape induced by the variation of a single joint. This requires a stitching process to combine each shallow SDF in the collection together into one SDF representing the signed closest distance to the boundary of the entire body. To achieve this we augment each shallow SDF with an additional output that resolves whether or not the individual shallow SDF value is referring to a closest point on the boundary of the body, or to a point on the interior of the body (but on the boundary of the individual shallow SDF). Our model is extremely fast and accurate and we demonstrate its applicability with real-time simulation of garments driven by animated characters.
A Deep Gradient Correction Method for Iteratively Solving Linear Systems
May 22, 2022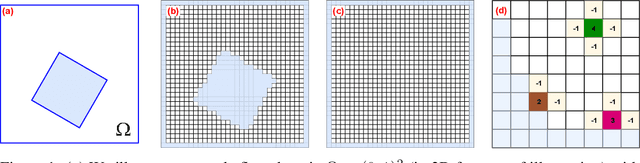

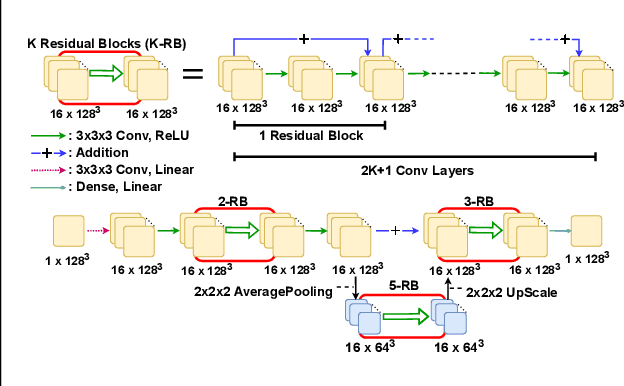

We present a novel deep learning approach to approximate the solution of large, sparse, symmetric, positive-definite linear systems of equations. These systems arise from many problems in applied science, e.g., in numerical methods for partial differential equations. Algorithms for approximating the solution to these systems are often the bottleneck in problems that require their solution, particularly for modern applications that require many millions of unknowns. Indeed, numerical linear algebra techniques have been investigated for many decades to alleviate this computational burden. Recently, data-driven techniques have also shown promise for these problems. Motivated by the conjugate gradients algorithm that iteratively selects search directions for minimizing the matrix norm of the approximation error, we design an approach that utilizes a deep neural network to accelerate convergence via data-driven improvement of the search directions. Our method leverages a carefully chosen convolutional network to approximate the action of the inverse of the linear operator up to an arbitrary constant. We train the network using unsupervised learning with a loss function equal to the $L^2$ difference between an input and the system matrix times the network evaluation, where the unspecified constant in the approximate inverse is accounted for. We demonstrate the efficacy of our approach on spatially discretized Poisson equations with millions of degrees of freedom arising in computational fluid dynamics applications. Unlike state-of-the-art learning approaches, our algorithm is capable of reducing the linear system residual to a given tolerance in a small number of iterations, independent of the problem size. Moreover, our method generalizes effectively to various systems beyond those encountered during training.
Markerless Augmented Advertising for Sports Videos
Jul 22, 2019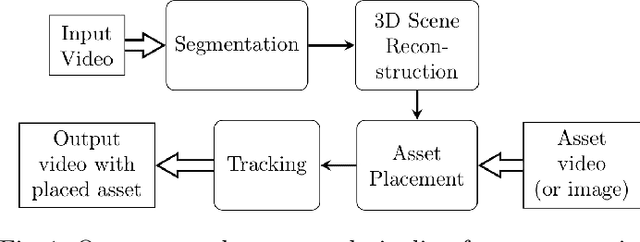

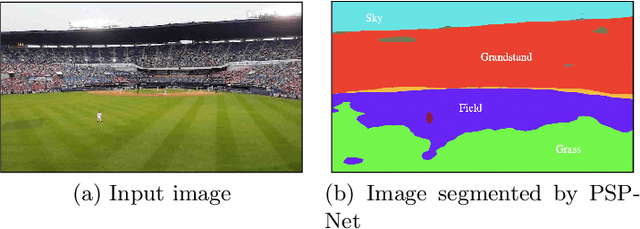

Markerless augmented reality can be a challenging computer vision task, especially in live broadcast settings and in the absence of information related to the video capture such as the intrinsic camera parameters. This typically requires the assistance of a skilled artist, along with the use of advanced video editing tools in a post-production environment. We present an automated video augmentation pipeline that identifies textures of interest and overlays an advertisement onto these regions. We constrain the advertisement to be placed in a way that is aesthetic and natural. The aim is to augment the scene such that there is no longer a need for commercial breaks. In order to achieve seamless integration of the advertisement with the original video we build a 3D representation of the scene, place the advertisement in 3D, and then project it back onto the image plane. After successful placement in a single frame, we use homography-based, shape-preserving tracking such that the advertisement appears perspective correct for the duration of a video clip. The tracker is designed to handle smooth camera motion and shot boundaries.
Semi-Supervised First-Person Activity Recognition in Body-Worn Video
Apr 19, 2019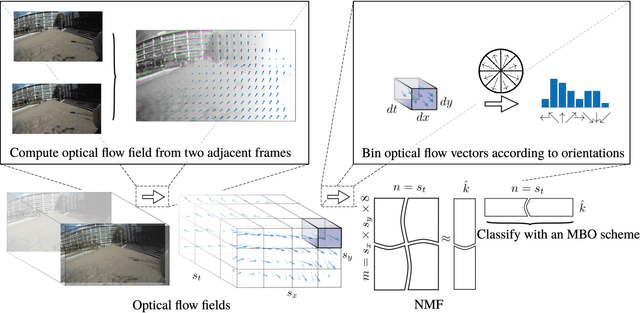
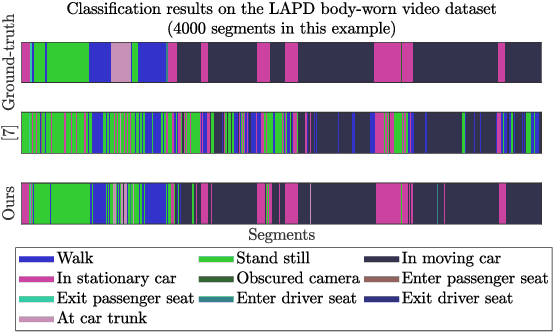
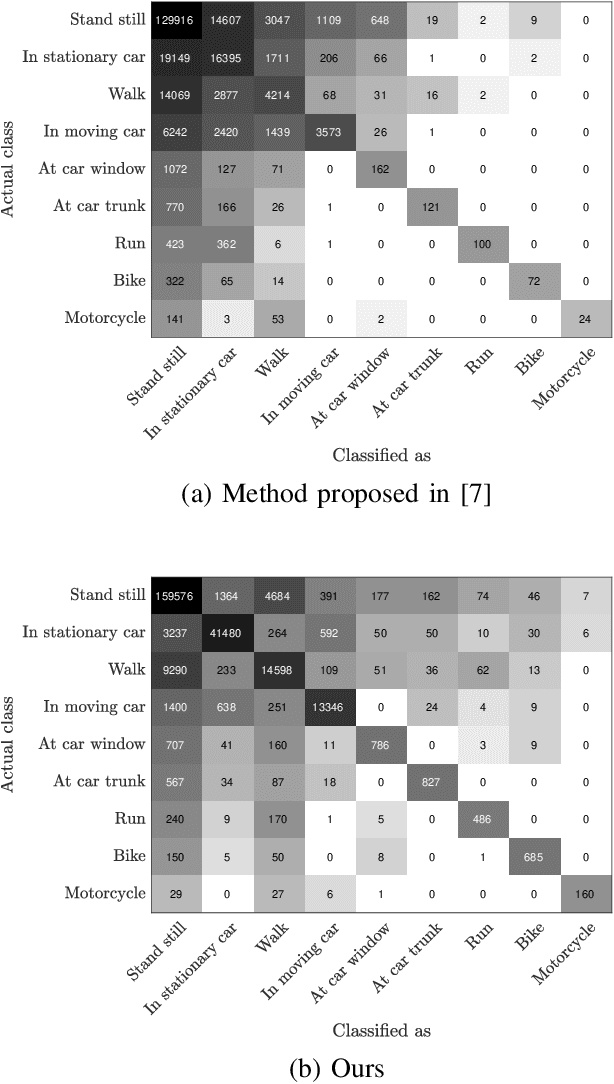
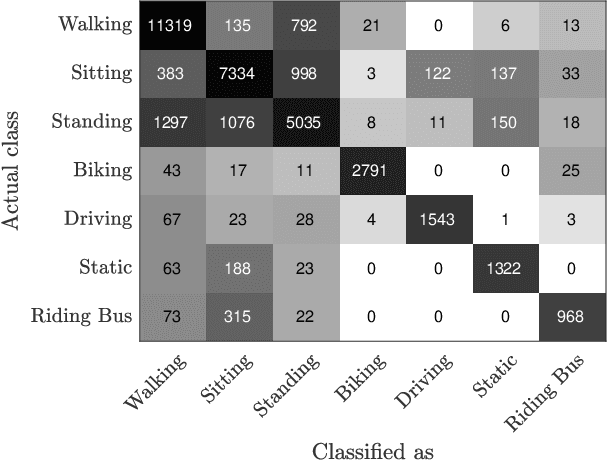
Body-worn cameras are now commonly used for logging daily life, sports, and law enforcement activities, creating a large volume of archived footage. This paper studies the problem of classifying frames of footage according to the activity of the camera-wearer with an emphasis on application to real-world police body-worn video. Real-world datasets pose a different set of challenges from existing egocentric vision datasets: the amount of footage of different activities is unbalanced, the data contains personally identifiable information, and in practice it is difficult to provide substantial training footage for a supervised approach. We address these challenges by extracting features based exclusively on motion information then segmenting the video footage using a semi-supervised classification algorithm. On publicly available datasets, our method achieves results comparable to, if not better than, supervised and/or deep learning methods using a fraction of the training data. It also shows promising results on real-world police body-worn video.