 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
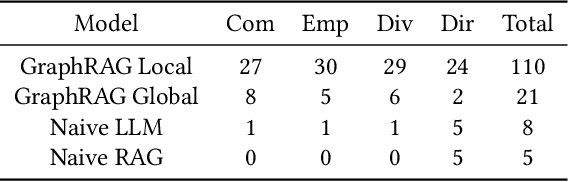

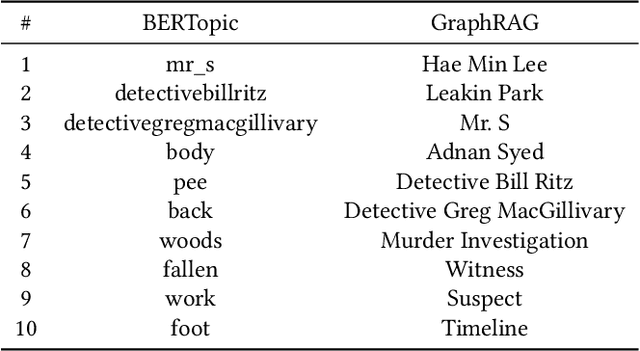
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling
Apr 07, 2024



Multimodal event argument role labeling (EARL), a task that assigns a role for each event participant (object) in an image is a complex challenge. It requires reasoning over the entire image, the depicted event, and the interactions between various objects participating in the event. Existing models heavily rely on high-quality event-annotated training data to understand the event semantics and structures, and they fail to generalize to new event types and domains. In this paper, we propose GenEARL, a training-free generative framework that harness the power of the modern generative models to understand event task descriptions given image contexts to perform the EARL task. Specifically, GenEARL comprises two stages of generative prompting with a frozen vision-language model (VLM) and a frozen large language model (LLM). First, a generative VLM learns the semantics of the event argument roles and generates event-centric object descriptions based on the image. Subsequently, a LLM is prompted with the generated object descriptions with a predefined template for EARL (i.e., assign an object with an event argument role). We show that GenEARL outperforms the contrastive pretraining (CLIP) baseline by 9.4% and 14.2% accuracy for zero-shot EARL on the M2E2 and SwiG datasets, respectively. In addition, we outperform CLIP-Event by 22% precision on M2E2 dataset. The framework also allows flexible adaptation and generalization to unseen domains.
Improving Event Definition Following For Zero-Shot Event Detection
Mar 05, 2024Existing approaches on zero-shot event detection usually train models on datasets annotated with known event types, and prompt them with unseen event definitions. These approaches yield sporadic successes, yet generally fall short of expectations. In this work, we aim to improve zero-shot event detection by training models to better follow event definitions. We hypothesize that a diverse set of event types and definitions are the key for models to learn to follow event definitions while existing event extraction datasets focus on annotating many high-quality examples for a few event types. To verify our hypothesis, we construct an automatically generated Diverse Event Definition (DivED) dataset and conduct comparative studies. Our experiments reveal that a large number of event types (200) and diverse event definitions can significantly boost event extraction performance; on the other hand, the performance does not scale with over ten examples per event type. Beyond scaling, we incorporate event ontology information and hard-negative samples during training, further boosting the performance. Based on these findings, we fine-tuned a LLaMA-2-7B model on our DivED dataset, yielding performance that surpasses SOTA large language models like GPT-3.5 across three open benchmarks on zero-shot event detection.
Professional Basketball Player Behavior Synthesis via Planning with Diffusion
Jun 10, 2023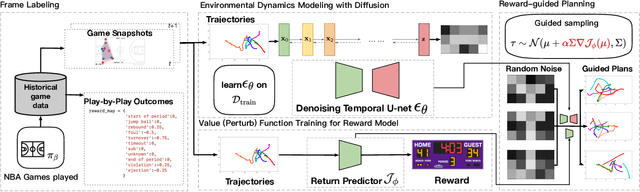
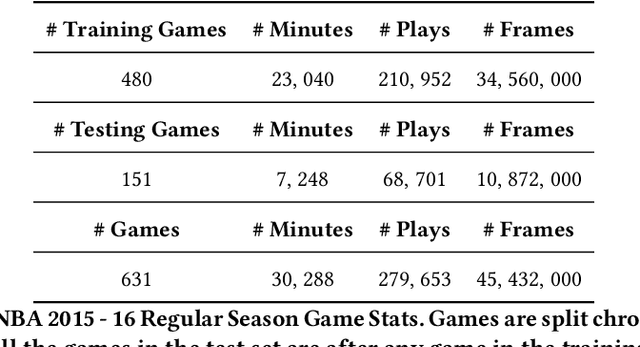
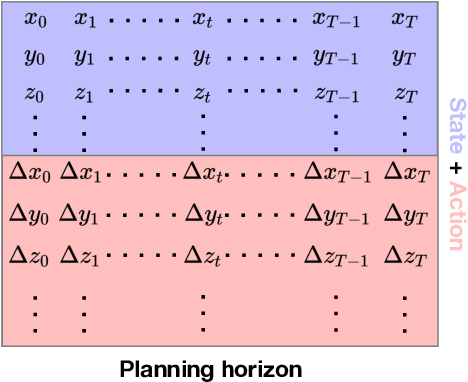

Dynamically planning in multi-agent systems has been explored to improve decision-making in various domains. Professional basketball serves as a compelling example of a dynamic spatio-temporal game, encompassing both concealed strategic policies and decision-making. However, processing the diverse on-court signals and navigating the vast space of potential actions and outcomes makes it difficult for existing approaches to swiftly identify optimal strategies in response to evolving circumstances. In this study, we first formulate the sequential decision-making process as a conditional trajectory generation process. We further introduce PLAYBEST (PLAYer BEhavior SynThesis), a method for enhancing player decision-making. We extend the state-of-the-art generative model, diffusion probabilistic model, to learn challenging multi-agent environmental dynamics from historical National Basketball Association (NBA) player motion tracking data. To incorporate data-driven strategies, an auxiliary value function is trained using the play-by-play data with corresponding rewards acting as the plan guidance. To accomplish reward-guided trajectory generation, conditional sampling is introduced to condition the diffusion model on the value function and conduct classifier-guided sampling. We validate the effectiveness of PLAYBEST via comprehensive simulation studies from real-world data, contrasting the generated trajectories and play strategies with those employed by professional basketball teams. Our results reveal that the model excels at generating high-quality basketball trajectories that yield efficient plays, surpassing conventional planning techniques in terms of adaptability, flexibility, and overall performance. Moreover, the synthesized play strategies exhibit a remarkable alignment with professional tactics, highlighting the model's capacity to capture the intricate dynamics of basketball games.
STAR: Boosting Low-Resource Event Extraction by Structure-to-Text Data Generation with Large Language Models
May 24, 2023
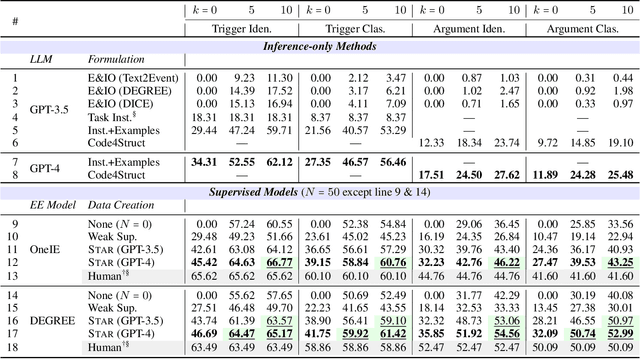

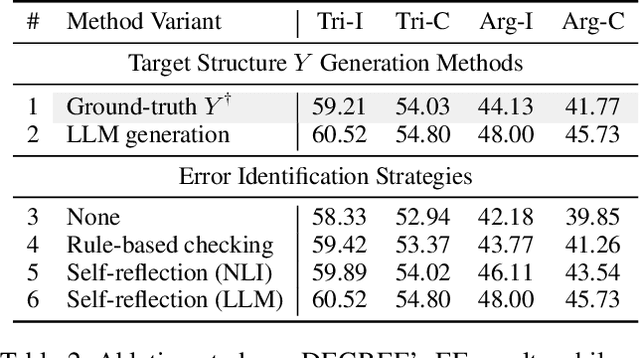
Structure prediction tasks such as event extraction require an in-depth understanding of the output structure and sub-task dependencies, thus they still heavily rely on task-specific training data to obtain reasonable performance. Due to the high cost of human annotation, low-resource event extraction, which requires minimal human cost, is urgently needed in real-world information extraction applications. We propose to synthesize data instances given limited seed demonstrations to boost low-resource event extraction performance. We propose STAR, a structure-to-text data generation method that first generates complicated event structures (Y) and then generates input passages (X), all with Large Language Models. We design fine-grained step-by-step instructions and the error cases and quality issues identified through self-reflection can be self-refined. Our experiments indicate that data generated by STAR can significantly improve the low-resource event extraction performance and they are even more effective than human-curated data points in some cases.
An Analysis of COVID-19 Knowledge Graph Construction and Applications
Oct 10, 2021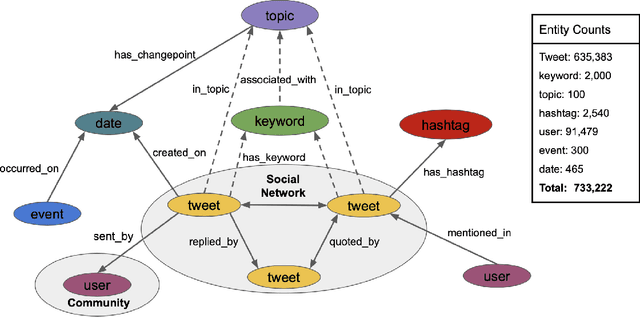
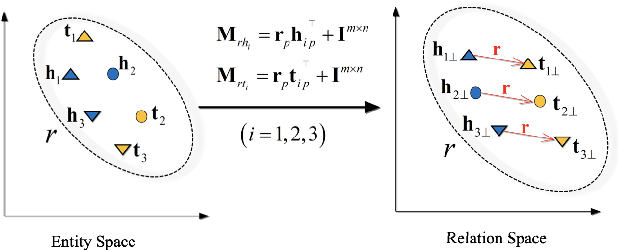
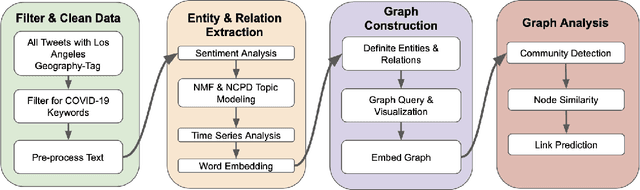
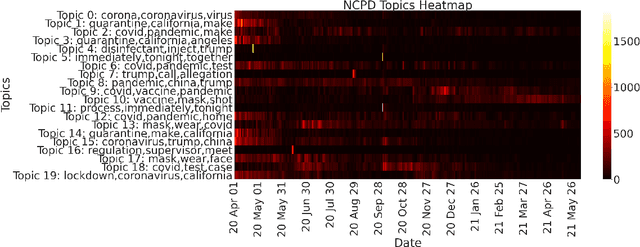
The construction and application of knowledge graphs have seen a rapid increase across many disciplines in recent years. Additionally, the problem of uncovering relationships between developments in the COVID-19 pandemic and social media behavior is of great interest to researchers hoping to curb the spread of the disease. In this paper we present a knowledge graph constructed from COVID-19 related tweets in the Los Angeles area, supplemented with federal and state policy announcements and disease spread statistics. By incorporating dates, topics, and events as entities, we construct a knowledge graph that describes the connections between these useful information. We use natural language processing and change point analysis to extract tweet-topic, tweet-date, and event-date relations. Further analysis on the constructed knowledge graph provides insight into how tweets reflect public sentiments towards COVID-19 related topics and how changes in these sentiments correlate with real-world events.
Computing Equilibria in Binary Networked Public Goods Games
Nov 13, 2019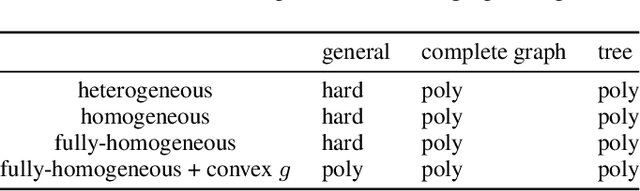
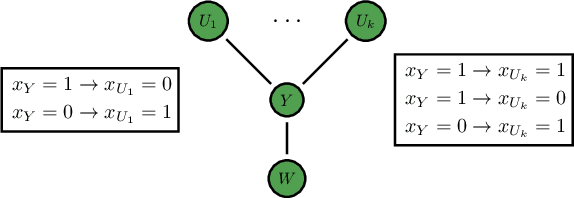
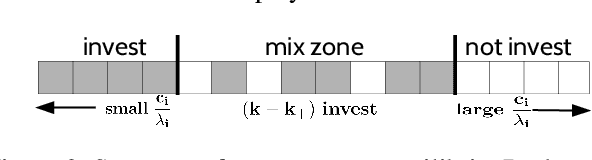
Public goods games study the incentives of individuals to contribute to a public good and their behaviors in equilibria. In this paper, we examine a specific type of public goods game where players are networked and each has binary actions, and focus on the algorithmic aspects of such games. First, we show that checking the existence of a pure-strategy Nash equilibrium is NP-Complete. We then identify tractable instances based on restrictions of either utility functions or of the underlying graphical structure. In certain cases, we also show that we can efficiently compute a socially optimal Nash equilibrium. Finally, we propose a heuristic approach for computing approximate equilibria in general binary networked public goods games, and experimentally demonstrate its effectiveness.
Semi-Supervised First-Person Activity Recognition in Body-Worn Video
Apr 19, 2019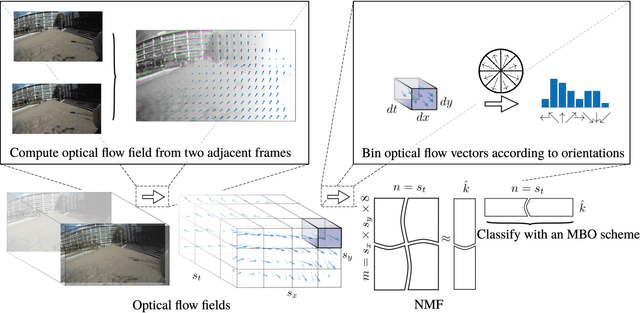
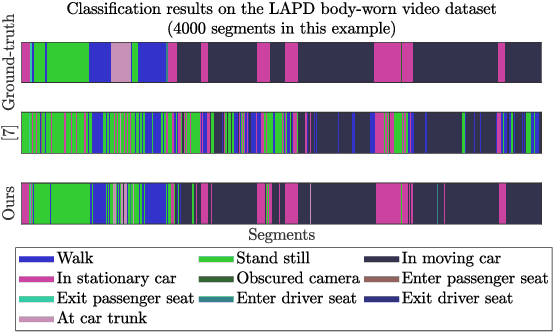
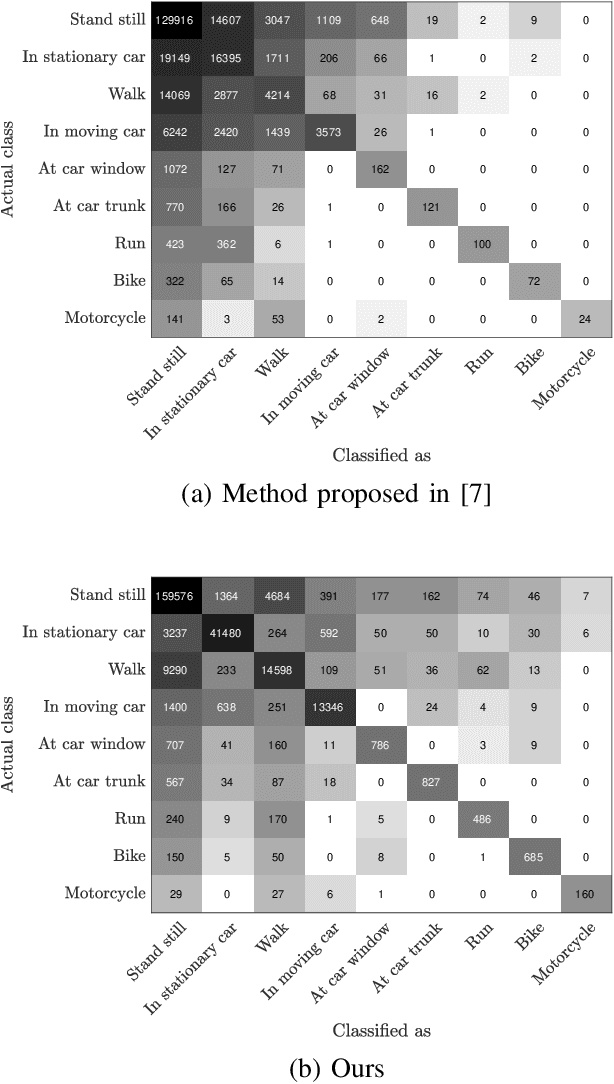
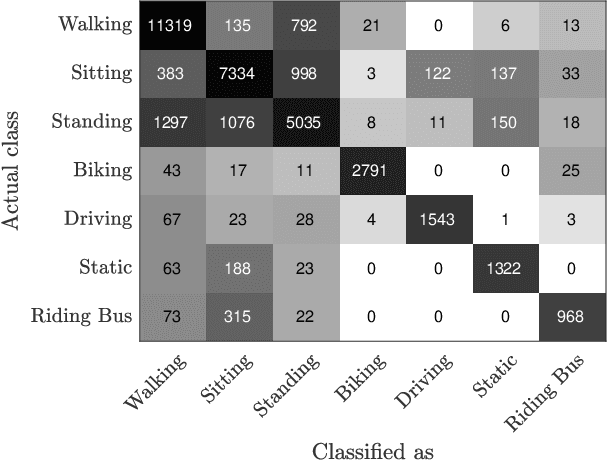
Body-worn cameras are now commonly used for logging daily life, sports, and law enforcement activities, creating a large volume of archived footage. This paper studies the problem of classifying frames of footage according to the activity of the camera-wearer with an emphasis on application to real-world police body-worn video. Real-world datasets pose a different set of challenges from existing egocentric vision datasets: the amount of footage of different activities is unbalanced, the data contains personally identifiable information, and in practice it is difficult to provide substantial training footage for a supervised approach. We address these challenges by extracting features based exclusively on motion information then segmenting the video footage using a semi-supervised classification algorithm. On publicly available datasets, our method achieves results comparable to, if not better than, supervised and/or deep learning methods using a fraction of the training data. It also shows promising results on real-world police body-worn video.
Multivariate Spatiotemporal Hawkes Processes and Network Reconstruction
Nov 15, 2018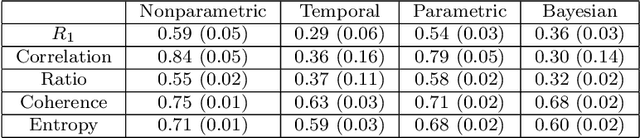
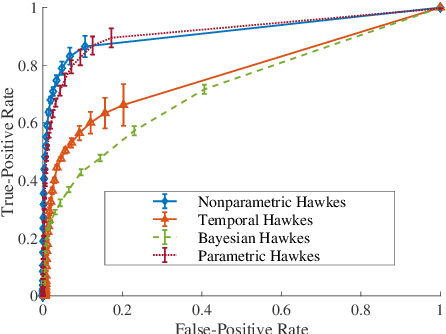
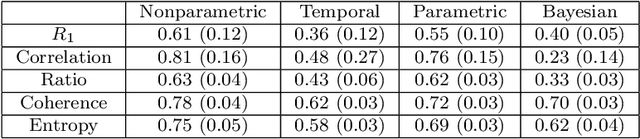
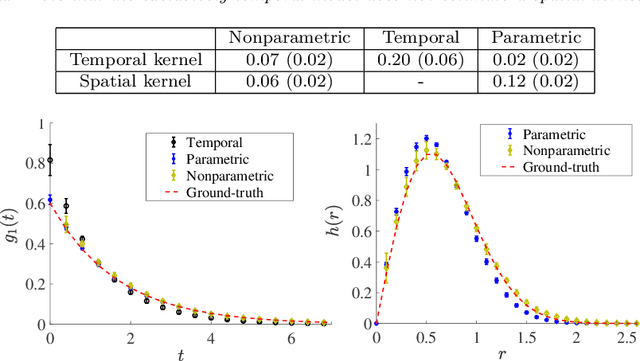
There is often latent network structure in spatial and temporal data and the tools of network analysis can yield fascinating insights into such data. In this paper, we develop a nonparametric method for network reconstruction from spatiotemporal data sets using multivariate Hawkes processes. In contrast to prior work on network reconstruction with point-process models, which has often focused on exclusively temporal information, our approach uses both temporal and spatial information and does not assume a specific parametric form of network dynamics. This leads to an effective way of recovering an underlying network. We illustrate our approach using both synthetic networks and networks constructed from real-world data sets (a location-based social media network, a narrative of crime events, and violent gang crimes). Our results demonstrate that, in comparison to using only temporal data, our spatiotemporal approach yields improved network reconstruction, providing a basis for meaningful subsequent analysis --- such as community structure and motif analysis --- of the reconstructed networks.
Crime Topic Modeling
Aug 06, 2018
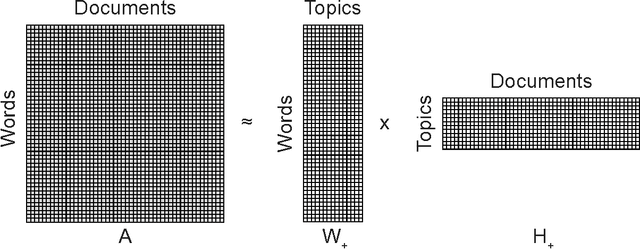
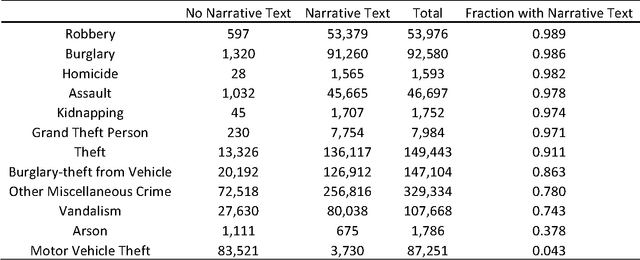
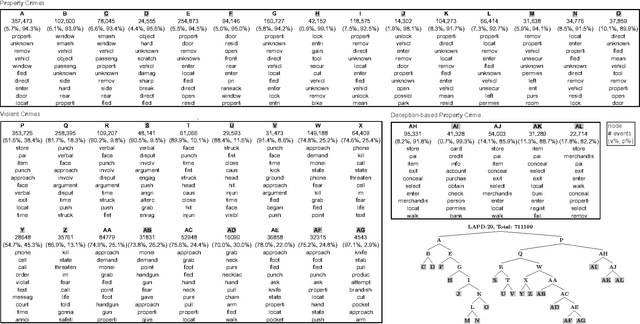
The classification of crime into discrete categories entails a massive loss of information. Crimes emerge out of a complex mix of behaviors and situations, yet most of these details cannot be captured by singular crime type labels. This information loss impacts our ability to not only understand the causes of crime, but also how to develop optimal crime prevention strategies. We apply machine learning methods to short narrative text descriptions accompanying crime records with the goal of discovering ecologically more meaningful latent crime classes. We term these latent classes "crime topics" in reference to text-based topic modeling methods that produce them. We use topic distributions to measure clustering among formally recognized crime types. Crime topics replicate broad distinctions between violent and property crime, but also reveal nuances linked to target characteristics, situational conditions and the tools and methods of attack. Formal crime types are not discrete in topic space. Rather, crime types are distributed across a range of crime topics. Similarly, individual crime topics are distributed across a range of formal crime types. Key ecological groups include identity theft, shoplifting, burglary and theft, car crimes and vandalism, criminal threats and confidence crimes, and violent crimes. Though not a replacement for formal legal crime classifications, crime topics provide a unique window into the heterogeneous causal processes underlying crime.
* 47 pages, 4 tables, 7 figures