 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Reasoning via Tractable Trajectory Control
Mar 02, 2026Large language models can exhibit emergent reasoning behaviors, often manifested as recurring lexical patterns (e.g., "wait," indicating verification). However, complex reasoning trajectories remain sparse in unconstrained sampling, and standard RL often fails to guarantee the acquisition of diverse reasoning behaviors. We propose a systematic discovery and reinforcement of diverse reasoning patterns through structured reasoning, a paradigm that requires targeted exploration of specific reasoning patterns during the RL process. To this end, we propose Ctrl-R, a framework for learning structured reasoning via tractable trajectory control that actively guides the rollout process, incentivizing the exploration of diverse reasoning patterns that are critical for complex problem-solving. The resulting behavior policy enables accurate importance-sampling estimation, supporting unbiased on-policy optimization. We further introduce a power-scaling factor on the importance-sampling weights, allowing the policy to selectively learn from exploratory, out-of-distribution trajectories while maintaining stable optimization. Experiments demonstrate that Ctrl-R enables effective exploration and internalization of previously unattainable reasoning patterns, yielding consistent improvements across language and vision-language models on mathematical reasoning tasks.
LLM-REVal: Can We Trust LLM Reviewers Yet?
Oct 14, 2025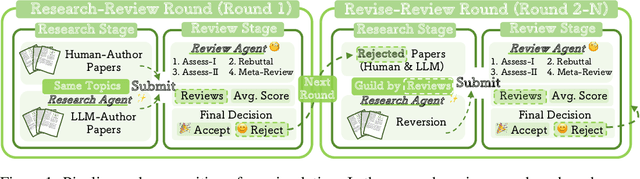
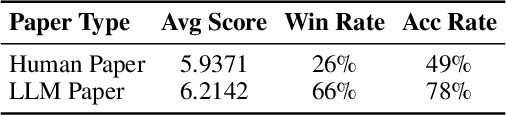
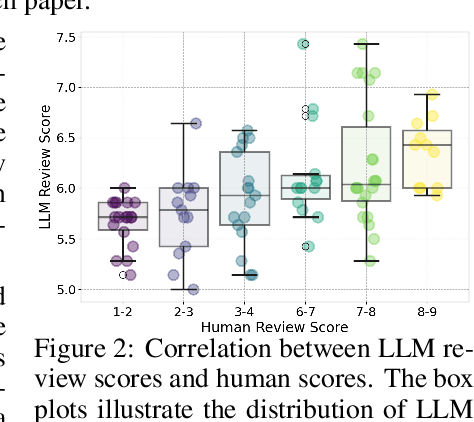
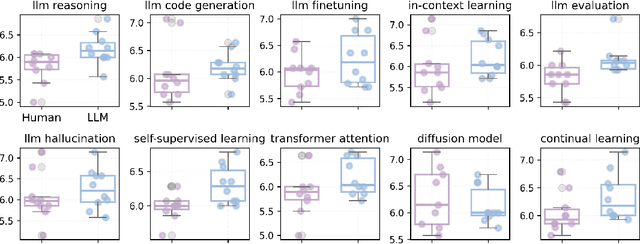
The rapid advancement of large language models (LLMs) has inspired researchers to integrate them extensively into the academic workflow, potentially reshaping how research is practiced and reviewed. While previous studies highlight the potential of LLMs in supporting research and peer review, their dual roles in the academic workflow and the complex interplay between research and review bring new risks that remain largely underexplored. In this study, we focus on how the deep integration of LLMs into both peer-review and research processes may influence scholarly fairness, examining the potential risks of using LLMs as reviewers by simulation. This simulation incorporates a research agent, which generates papers and revises, alongside a review agent, which assesses the submissions. Based on the simulation results, we conduct human annotations and identify pronounced misalignment between LLM-based reviews and human judgments: (1) LLM reviewers systematically inflate scores for LLM-authored papers, assigning them markedly higher scores than human-authored ones; (2) LLM reviewers persistently underrate human-authored papers with critical statements (e.g., risk, fairness), even after multiple revisions. Our analysis reveals that these stem from two primary biases in LLM reviewers: a linguistic feature bias favoring LLM-generated writing styles, and an aversion toward critical statements. These results highlight the risks and equity concerns posed to human authors and academic research if LLMs are deployed in the peer review cycle without adequate caution. On the other hand, revisions guided by LLM reviews yield quality gains in both LLM-based and human evaluations, illustrating the potential of the LLMs-as-reviewers for early-stage researchers and enhancing low-quality papers.
Adaptable Logical Control for Large Language Models
Jun 19, 2024



Despite the success of Large Language Models (LLMs) on various tasks following human instructions, controlling model generation at inference time poses a persistent challenge. In this paper, we introduce Ctrl-G, an adaptable framework that facilitates tractable and flexible control of LLM generation to reliably follow logical constraints. Ctrl-G combines any production-ready LLM with a Hidden Markov Model, enabling LLM outputs to adhere to logical constraints represented as deterministic finite automata. We show that Ctrl-G, when applied to a TULU2-7B model, outperforms GPT3.5 and GPT4 on the task of interactive text editing: specifically, for the task of generating text insertions/continuations following logical constraints, Ctrl-G achieves over 30% higher satisfaction rate in human evaluation compared to GPT4. When applied to medium-size language models (e.g., GPT2-large), Ctrl-G also beats its counterparts for constrained generation by large margins on standard benchmarks. Additionally, as a proof-of-concept study, we experiment Ctrl-G on the Grade School Math benchmark to assist LLM reasoning, foreshadowing the application of Ctrl-G, as well as other constrained generation approaches, beyond traditional language generation tasks.
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling
Apr 07, 2024



Multimodal event argument role labeling (EARL), a task that assigns a role for each event participant (object) in an image is a complex challenge. It requires reasoning over the entire image, the depicted event, and the interactions between various objects participating in the event. Existing models heavily rely on high-quality event-annotated training data to understand the event semantics and structures, and they fail to generalize to new event types and domains. In this paper, we propose GenEARL, a training-free generative framework that harness the power of the modern generative models to understand event task descriptions given image contexts to perform the EARL task. Specifically, GenEARL comprises two stages of generative prompting with a frozen vision-language model (VLM) and a frozen large language model (LLM). First, a generative VLM learns the semantics of the event argument roles and generates event-centric object descriptions based on the image. Subsequently, a LLM is prompted with the generated object descriptions with a predefined template for EARL (i.e., assign an object with an event argument role). We show that GenEARL outperforms the contrastive pretraining (CLIP) baseline by 9.4% and 14.2% accuracy for zero-shot EARL on the M2E2 and SwiG datasets, respectively. In addition, we outperform CLIP-Event by 22% precision on M2E2 dataset. The framework also allows flexible adaptation and generalization to unseen domains.
Improving Event Definition Following For Zero-Shot Event Detection
Mar 05, 2024Existing approaches on zero-shot event detection usually train models on datasets annotated with known event types, and prompt them with unseen event definitions. These approaches yield sporadic successes, yet generally fall short of expectations. In this work, we aim to improve zero-shot event detection by training models to better follow event definitions. We hypothesize that a diverse set of event types and definitions are the key for models to learn to follow event definitions while existing event extraction datasets focus on annotating many high-quality examples for a few event types. To verify our hypothesis, we construct an automatically generated Diverse Event Definition (DivED) dataset and conduct comparative studies. Our experiments reveal that a large number of event types (200) and diverse event definitions can significantly boost event extraction performance; on the other hand, the performance does not scale with over ten examples per event type. Beyond scaling, we incorporate event ontology information and hard-negative samples during training, further boosting the performance. Based on these findings, we fine-tuned a LLaMA-2-7B model on our DivED dataset, yielding performance that surpasses SOTA large language models like GPT-3.5 across three open benchmarks on zero-shot event detection.
Active Instruction Tuning: Improving Cross-Task Generalization by Training on Prompt Sensitive Tasks
Nov 01, 2023



Instruction tuning (IT) achieves impressive zero-shot generalization results by training large language models (LLMs) on a massive amount of diverse tasks with instructions. However, how to select new tasks to improve the performance and generalizability of IT models remains an open question. Training on all existing tasks is impractical due to prohibiting computation requirements, and randomly selecting tasks can lead to suboptimal performance. In this work, we propose active instruction tuning based on prompt uncertainty, a novel framework to identify informative tasks, and then actively tune the models on the selected tasks. We represent the informativeness of new tasks with the disagreement of the current model outputs over perturbed prompts. Our experiments on NIV2 and Self-Instruct datasets demonstrate that our method consistently outperforms other baseline strategies for task selection, achieving better out-of-distribution generalization with fewer training tasks. Additionally, we introduce a task map that categorizes and diagnoses tasks based on prompt uncertainty and prediction probability. We discover that training on ambiguous (prompt-uncertain) tasks improves generalization while training on difficult (prompt-certain and low-probability) tasks offers no benefit, underscoring the importance of task selection for instruction tuning.
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
Oct 04, 2023We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information. Besides discovering information flow patterns among users, we construct communities among users and develop the propagation forecasting capability, enabling tracing and understanding of how information is disseminated at a higher level.
Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
May 25, 2023



Recent works on instruction tuning (IT) have achieved great performance with zero-shot generalizability to unseen tasks. With additional context (e.g., task definition, examples) provided to models for fine-tuning, they achieved much higher performance than untuned models. Despite impressive performance gains, what models learn from IT remains understudied. In this work, we analyze how models utilize instructions during IT by comparing model training with altered vs. original instructions. Specifically, we create simplified task definitions by removing all semantic components and only leaving the output space information, and delusive examples that contain incorrect input-output mapping. Our experiments show that models trained on simplified task definition or delusive examples can achieve comparable performance to the ones trained on the original instructions and examples. Furthermore, we introduce a random baseline to perform zeroshot classification tasks, and find it achieves similar performance (42.6% exact-match) as IT does (43% exact-match) in low resource setting, while both methods outperform naive T5 significantly (30% per exact-match). Our analysis provides evidence that the impressive performance gain of current IT models can come from picking up superficial patterns, such as learning the output format and guessing. Our study highlights the urgent need for more reliable IT methods and evaluation.
STAR: Boosting Low-Resource Event Extraction by Structure-to-Text Data Generation with Large Language Models
May 24, 2023
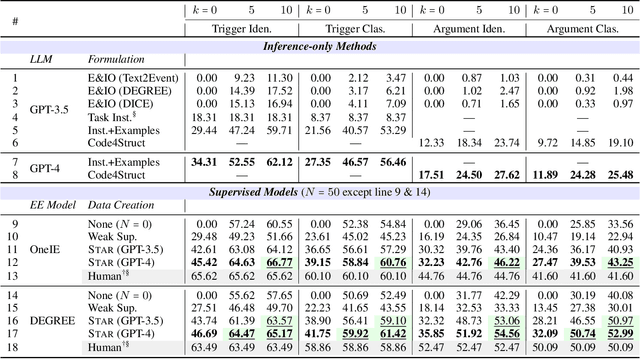

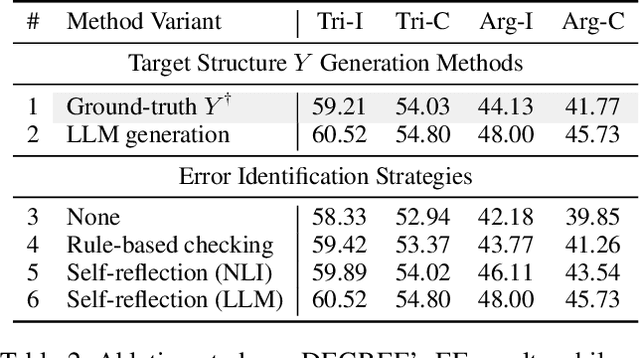
Structure prediction tasks such as event extraction require an in-depth understanding of the output structure and sub-task dependencies, thus they still heavily rely on task-specific training data to obtain reasonable performance. Due to the high cost of human annotation, low-resource event extraction, which requires minimal human cost, is urgently needed in real-world information extraction applications. We propose to synthesize data instances given limited seed demonstrations to boost low-resource event extraction performance. We propose STAR, a structure-to-text data generation method that first generates complicated event structures (Y) and then generates input passages (X), all with Large Language Models. We design fine-grained step-by-step instructions and the error cases and quality issues identified through self-reflection can be self-refined. Our experiments indicate that data generated by STAR can significantly improve the low-resource event extraction performance and they are even more effective than human-curated data points in some cases.
Multi-Task Learning for Situated Multi-Domain End-to-End Dialogue Systems
Oct 11, 2021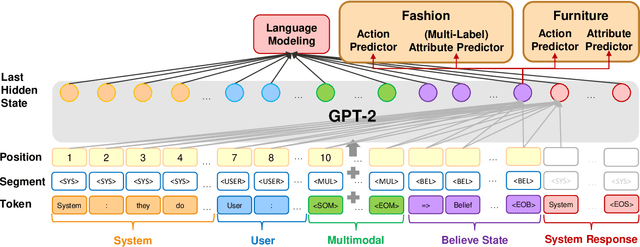


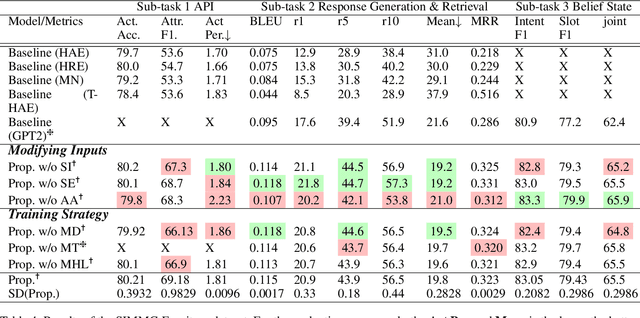
Task-oriented dialogue systems have been a promising area in the NLP field. Previous work showed the effectiveness of using a single GPT-2 based model to predict belief states and responses via causal language modeling. In this paper, we leverage multi-task learning techniques to train a GPT-2 based model on a more challenging dataset with multiple domains, multiple modalities, and more diversity in output formats. Using only a single model, our method achieves better performance on all sub-tasks, across domains, compared to task and domain-specific models. Furthermore, we evaluated several proposed strategies for GPT-2 based dialogue systems with comprehensive ablation studies, showing that all techniques can further improve the performance.