 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
QUDSELECT: Selective Decoding for Questions Under Discussion Parsing
Aug 02, 2024
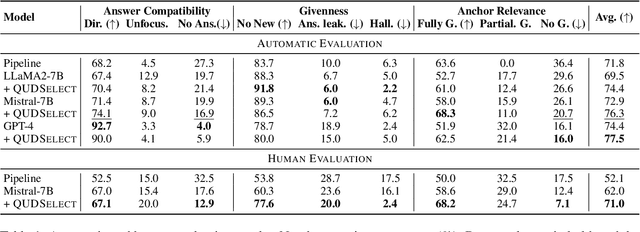
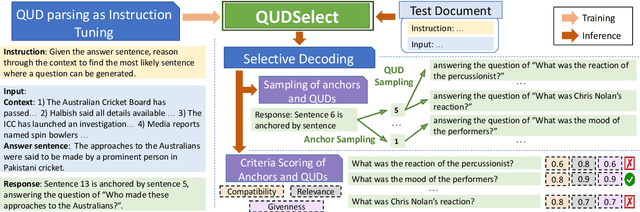

Question Under Discussion (QUD) is a discourse framework that uses implicit questions to reveal discourse relationships between sentences. In QUD parsing, each sentence is viewed as an answer to a question triggered by an anchor sentence in prior context. The resulting QUD structure is required to conform to several theoretical criteria like answer compatibility (how well the question is answered), making QUD parsing a challenging task. Previous works construct QUD parsers in a pipelined manner (i.e. detect the trigger sentence in context and then generate the question). However, these parsers lack a holistic view of the task and can hardly satisfy all the criteria. In this work, we introduce QUDSELECT, a joint-training framework that selectively decodes the QUD dependency structures considering the QUD criteria. Using instruction-tuning, we train models to simultaneously predict the anchor sentence and generate the associated question. To explicitly incorporate the criteria, we adopt a selective decoding strategy of sampling multiple QUD candidates during inference, followed by selecting the best one with criteria scorers. Our method outperforms the state-of-the-art baseline models by 9% in human evaluation and 4% in automatic evaluation, demonstrating the effectiveness of our framework.
PhonologyBench: Evaluating Phonological Skills of Large Language Models
Apr 05, 2024



Phonology, the study of speech's structure and pronunciation rules, is a critical yet often overlooked component in Large Language Model (LLM) research. LLMs are widely used in various downstream applications that leverage phonology such as educational tools and poetry generation. Moreover, LLMs can potentially learn imperfect associations between orthographic and phonological forms from the training data. Thus, it is imperative to benchmark the phonological skills of LLMs. To this end, we present PhonologyBench, a novel benchmark consisting of three diagnostic tasks designed to explicitly test the phonological skills of LLMs in English: grapheme-to-phoneme conversion, syllable counting, and rhyme word generation. Despite having no access to speech data, LLMs showcased notable performance on the PhonologyBench tasks. However, we observe a significant gap of 17% and 45% on Rhyme Word Generation and Syllable counting, respectively, when compared to humans. Our findings underscore the importance of studying LLM performance on phonological tasks that inadvertently impact real-world applications. Furthermore, we encourage researchers to choose LLMs that perform well on the phonological task that is closely related to the downstream application since we find that no single model consistently outperforms the others on all the tasks.
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Apr 02, 2024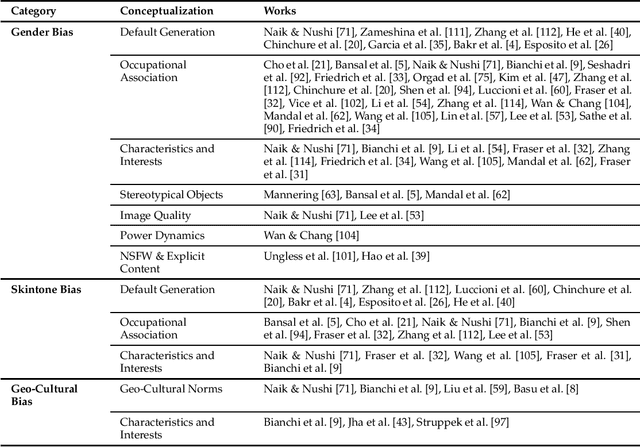
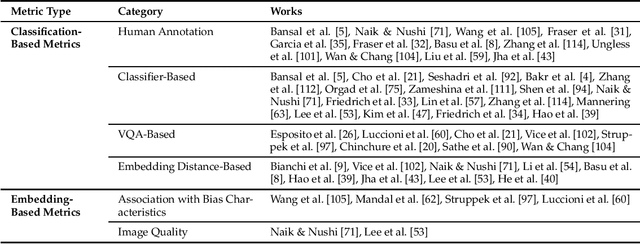

The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Comparing Bad Apples to Good Oranges: Aligning Large Language Models via Joint Preference Optimization
Mar 31, 2024A common technique for aligning large language models (LLMs) relies on acquiring human preferences by comparing multiple generations conditioned on a fixed context. This only leverages the pairwise comparisons when the generations are placed in an identical context. However, such conditional rankings often fail to capture the complex and multidimensional aspects of human preferences. In this work, we revisit the traditional paradigm of preference acquisition and propose a new axis that is based on eliciting preferences jointly over the instruction-response pairs. While prior preference optimizations are designed for conditional ranking protocols (e.g., DPO), our proposed preference acquisition protocol introduces DOVE, a new preference optimization objective that upweights the joint probability of the chosen instruction-response pair over the rejected instruction-response pair. Interestingly, we find that the LLM trained with joint instruction-response preference data using DOVE outperforms the LLM trained with DPO by 5.2% and 3.3% win-rate for the summarization and open-ended dialogue datasets, respectively. Our findings reveal that joint preferences over instruction and response pairs can significantly enhance the alignment of LLMs by tapping into a broader spectrum of human preference elicitation. The data and code is available at https://github.com/Hritikbansal/dove.
Improving Event Definition Following For Zero-Shot Event Detection
Mar 05, 2024Existing approaches on zero-shot event detection usually train models on datasets annotated with known event types, and prompt them with unseen event definitions. These approaches yield sporadic successes, yet generally fall short of expectations. In this work, we aim to improve zero-shot event detection by training models to better follow event definitions. We hypothesize that a diverse set of event types and definitions are the key for models to learn to follow event definitions while existing event extraction datasets focus on annotating many high-quality examples for a few event types. To verify our hypothesis, we construct an automatically generated Diverse Event Definition (DivED) dataset and conduct comparative studies. Our experiments reveal that a large number of event types (200) and diverse event definitions can significantly boost event extraction performance; on the other hand, the performance does not scale with over ten examples per event type. Beyond scaling, we incorporate event ontology information and hard-negative samples during training, further boosting the performance. Based on these findings, we fine-tuned a LLaMA-2-7B model on our DivED dataset, yielding performance that surpasses SOTA large language models like GPT-3.5 across three open benchmarks on zero-shot event detection.
Judging a Book by its Description : Analyzing Gender Stereotypes in the Man Bookers Prize Winning Fiction
Jul 25, 2018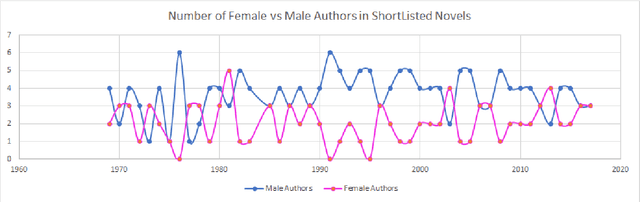
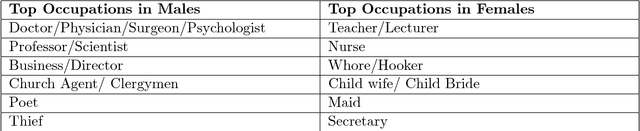
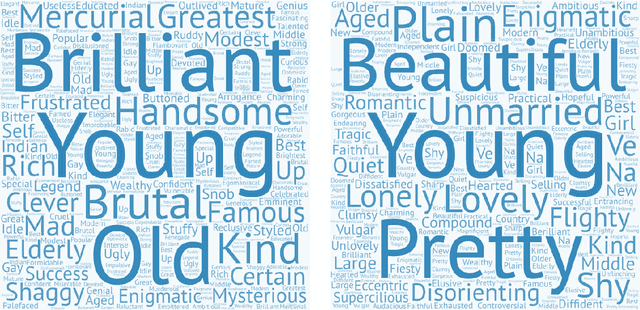

The presence of gender stereotypes in many aspects of society is a well-known phenomenon. In this paper, we focus on studying and quantifying such stereotypes and bias in the Man Bookers Prize winning fiction. We consider 275 books shortlisted for Man Bookers Prize between 1969 and 2017. The gender bias is analyzed by semantic modeling of book descriptions on Goodreads. This reveals the pervasiveness of gender bias and stereotype in the books on different features like occupation, introductions and actions associated to the characters in the book.