 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025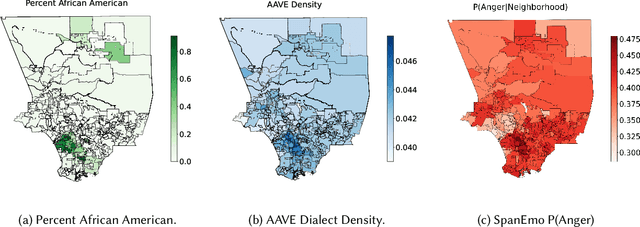
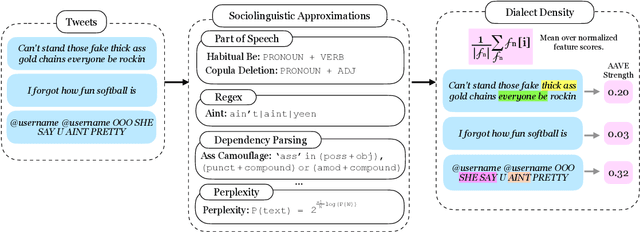
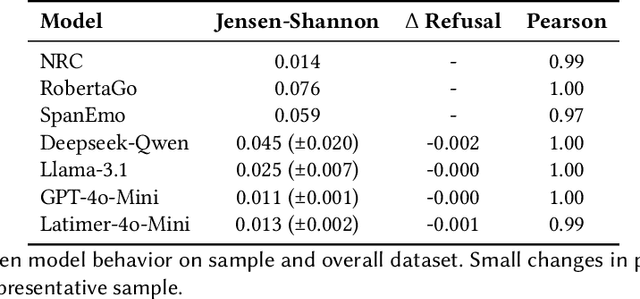

Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
Leveraging Large Language Models and Topic Modeling for Toxicity Classification
Nov 26, 2024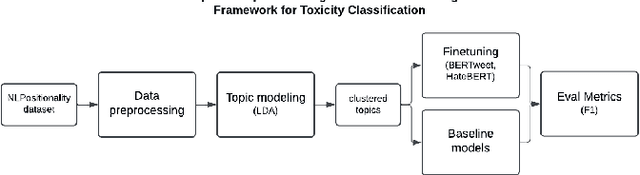
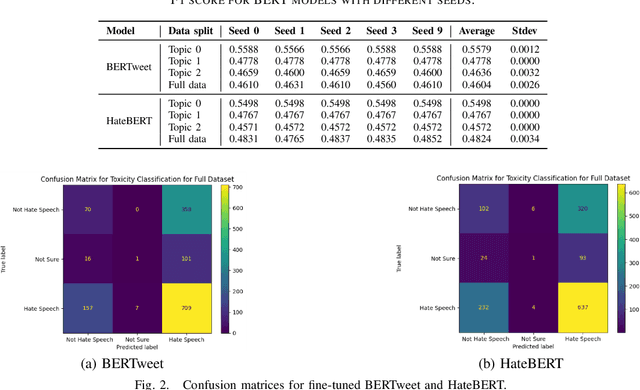

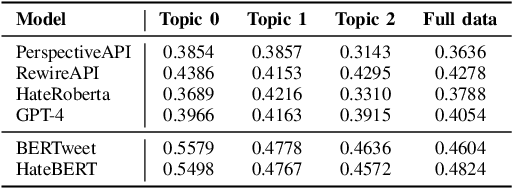
Content moderation and toxicity classification represent critical tasks with significant social implications. However, studies have shown that major classification models exhibit tendencies to magnify or reduce biases and potentially overlook or disadvantage certain marginalized groups within their classification processes. Researchers suggest that the positionality of annotators influences the gold standard labels in which the models learned from propagate annotators' bias. To further investigate the impact of annotator positionality, we delve into fine-tuning BERTweet and HateBERT on the dataset while using topic-modeling strategies for content moderation. The results indicate that fine-tuning the models on specific topics results in a notable improvement in the F1 score of the models when compared to the predictions generated by other prominent classification models such as GPT-4, PerspectiveAPI, and RewireAPI. These findings further reveal that the state-of-the-art large language models exhibit significant limitations in accurately detecting and interpreting text toxicity contrasted with earlier methodologies. Code is available at https://github.com/aheldis/Toxicity-Classification.git.
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Apr 02, 2024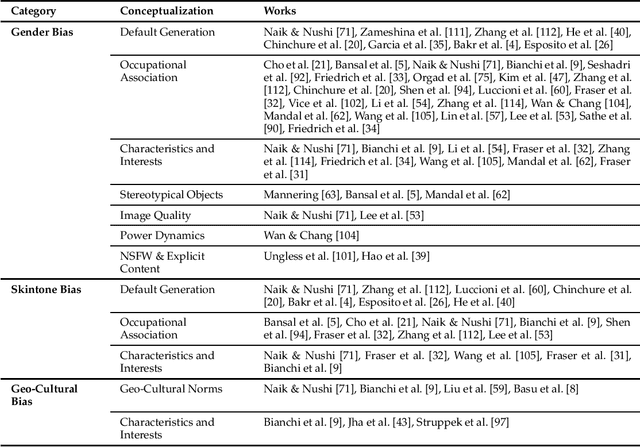
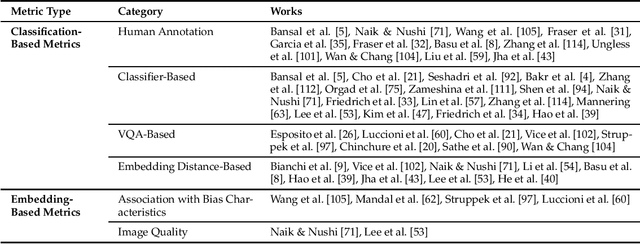

The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Leveraging Language Models to Detect Greenwashing
Oct 30, 2023In recent years, climate change repercussions have increasingly captured public interest. Consequently, corporations are emphasizing their environmental efforts in sustainability reports to bolster their public image. Yet, the absence of stringent regulations in review of such reports allows potential greenwashing. In this study, we introduce a novel methodology to train a language model on generated labels for greenwashing risk. Our primary contributions encompass: developing a mathematical formulation to quantify greenwashing risk, a fine-tuned ClimateBERT model for this problem, and a comparative analysis of results. On a test set comprising of sustainability reports, our best model achieved an average accuracy score of 86.34% and F1 score of 0.67, demonstrating that our methods show a promising direction of exploration for this task.
Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts
Oct 16, 2023



Recent studies show that traditional fairytales are rife with harmful gender biases. To help mitigate these gender biases in fairytales, this work aims to assess learned biases of language models by evaluating their robustness against gender perturbations. Specifically, we focus on Question Answering (QA) tasks in fairytales. Using counterfactual data augmentation to the FairytaleQA dataset, we evaluate model robustness against swapped gender character information, and then mitigate learned biases by introducing counterfactual gender stereotypes during training time. We additionally introduce a novel approach that utilizes the massive vocabulary of language models to support text genres beyond fairytales. Our experimental results suggest that models are sensitive to gender perturbations, with significant performance drops compared to the original testing set. However, when first fine-tuned on a counterfactual training dataset, models are less sensitive to the later introduced anti-gender stereotyped text.