 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Alignment of Language Models for Personalized Psychotherapy
Feb 17, 2026Mental health disorders affect over 1 billion people worldwide, yet access to care remains limited by workforce shortages and cost constraints. While AI systems show therapeutic promise, current alignment approaches optimize objectives independently, failing to balance patient preferences with clinical safety. We survey 335 individuals with lived mental health experience to collect preference rankings across therapeutic dimensions, then develop a multi-objective alignment framework using direct preference optimization. We train reward models for six criteria -- empathy, safety, active listening, self-motivated change, trust/rapport, and patient autonomy -- and systematically compare multi-objective approaches against single-objective optimization, supervised fine-tuning, and parameter merging. Multi-objective DPO (MODPO) achieves superior balance (77.6% empathy, 62.6% safety) compared to single-objective optimization (93.6% empathy, 47.8% safety), and therapeutic criteria outperform general communication principles by 17.2%. Blinded clinician evaluation confirms MODPO is consistently preferred, with LLM-evaluator agreement comparable to inter-clinician reliability.
Leveraging ChatGPT and Other NLP Methods for Identifying Risk and Protective Behaviors in MSM: Social Media and Dating apps Text Analysis
Jan 20, 2026Men who have sex with men (MSM) are at elevated risk for sexually transmitted infections and harmful drinking compared to heterosexual men. Text data collected from social media and dating applications may provide new opportunities for personalized public health interventions by enabling automatic identification of risk and protective behaviors. In this study, we evaluated whether text from social media and dating apps can be used to predict sexual risk behaviors, alcohol use, and pre-exposure prophylaxis (PrEP) uptake among MSM. With participant consent, we collected textual data and trained machine learning models using features derived from ChatGPT embeddings, BERT embeddings, LIWC, and a dictionary-based risk term approach. The models achieved strong performance in predicting monthly binge drinking and having more than five sexual partners, with F1 scores of 0.78, and moderate performance in predicting PrEP use and heavy drinking, with F1 scores of 0.64 and 0.63. These findings demonstrate that social media and dating app text data can provide valuable insights into risk and protective behaviors and highlight the potential of large language model-based methods to support scalable and personalized public health interventions for MSM.
MI-to-Mid Distilled Compression (M2M-DC): An Hybrid-Information-Guided-Block Pruning with Progressive Inner Slicing Approach to Model Compression
Nov 18, 2025We introduce MI-to-Mid Distilled Compression (M2M-DC), a two-scale, shape-safe compression framework that interleaves information-guided block pruning with progressive inner slicing and staged knowledge distillation (KD). First, M2M-DC ranks residual (or inverted-residual) blocks by a label-aware mutual information (MI) signal and removes the least informative units (structured prune-after-training). It then alternates short KD phases with stage-coherent, residual-safe channel slicing: (i) stage "planes" (co-slicing conv2 out-channels with the downsample path and next-stage inputs), and (ii) an optional mid-channel trim (conv1 out / bn1 / conv2 in). This targets complementary redundancy, whole computational motifs and within-stage width while preserving residual shape invariants. On CIFAR-100, M2M-DC yields a clean accuracy-compute frontier. For ResNet-18, we obtain 85.46% Top-1 with 3.09M parameters and 0.0139 GMacs (72% params, 63% GMacs vs. teacher; mean final 85.29% over three seeds). For ResNet-34, we reach 85.02% Top-1 with 5.46M params and 0.0195 GMacs (74% / 74% vs. teacher; mean final 84.62%). Extending to inverted-residuals, MobileNetV2 achieves a mean final 68.54% Top-1 at 1.71M params (27%) and 0.0186 conv GMacs (24%), improving over the teacher's 66.03% by +2.5 points across three seeds. Because M2M-DC exposes only a thin, architecture-aware interface (blocks, stages, and down sample/skip wiring), it generalizes across residual CNNs and extends to inverted-residual families with minor legalization rules. The result is a compact, practical recipe for deployment-ready models that match or surpass teacher accuracy at a fraction of the compute.
Exploring a Datasets Statistical Effect Size Impact on Model Performance, and Data Sample-Size Sufficiency
Jan 05, 2025Having a sufficient quantity of quality data is a critical enabler of training effective machine learning models. Being able to effectively determine the adequacy of a dataset prior to training and evaluating a model's performance would be an essential tool for anyone engaged in experimental design or data collection. However, despite the need for it, the ability to prospectively assess data sufficiency remains an elusive capability. We report here on two experiments undertaken in an attempt to better ascertain whether or not basic descriptive statistical measures can be indicative of how effective a dataset will be at training a resulting model. Leveraging the effect size of our features, this work first explores whether or not a correlation exists between effect size, and resulting model performance (theorizing that the magnitude of the distinction between classes could correlate to a classifier's resulting success). We then explore whether or not the magnitude of the effect size will impact the rate of convergence of our learning rate, (theorizing again that a greater effect size may indicate that the model will converge more rapidly, and with a smaller sample size needed). Our results appear to indicate that this is not an effective heuristic for determining adequate sample size or projecting model performance, and therefore that additional work is still needed to better prospectively assess adequacy of data.
Leveraging Large Language Models and Topic Modeling for Toxicity Classification
Nov 26, 2024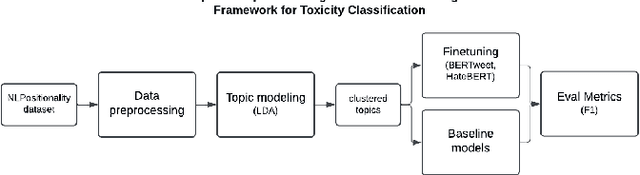
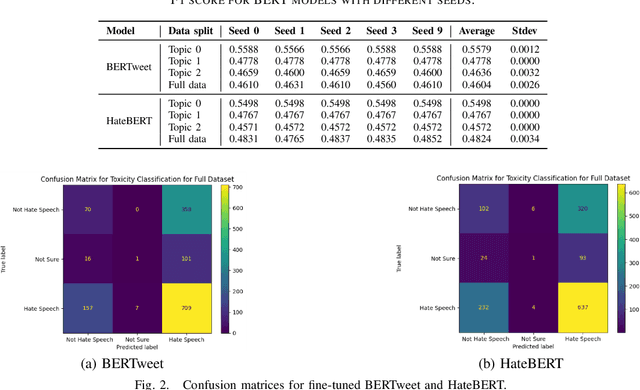

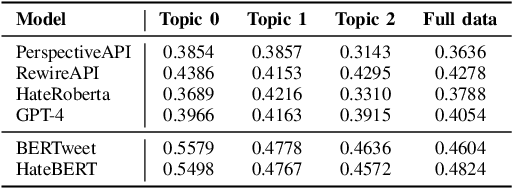
Content moderation and toxicity classification represent critical tasks with significant social implications. However, studies have shown that major classification models exhibit tendencies to magnify or reduce biases and potentially overlook or disadvantage certain marginalized groups within their classification processes. Researchers suggest that the positionality of annotators influences the gold standard labels in which the models learned from propagate annotators' bias. To further investigate the impact of annotator positionality, we delve into fine-tuning BERTweet and HateBERT on the dataset while using topic-modeling strategies for content moderation. The results indicate that fine-tuning the models on specific topics results in a notable improvement in the F1 score of the models when compared to the predictions generated by other prominent classification models such as GPT-4, PerspectiveAPI, and RewireAPI. These findings further reveal that the state-of-the-art large language models exhibit significant limitations in accurately detecting and interpreting text toxicity contrasted with earlier methodologies. Code is available at https://github.com/aheldis/Toxicity-Classification.git.
Exploring Cross-model Neuronal Correlations in the Context of Predicting Model Performance and Generalizability
Aug 15, 2024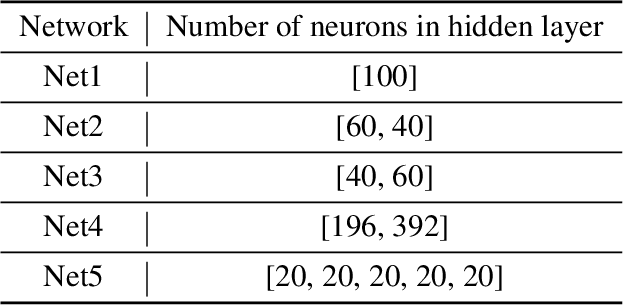
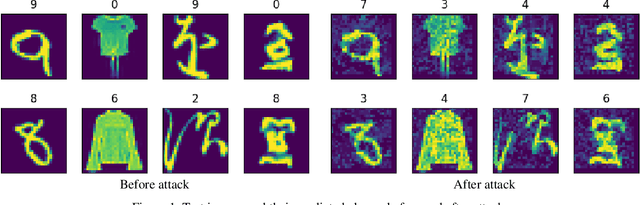
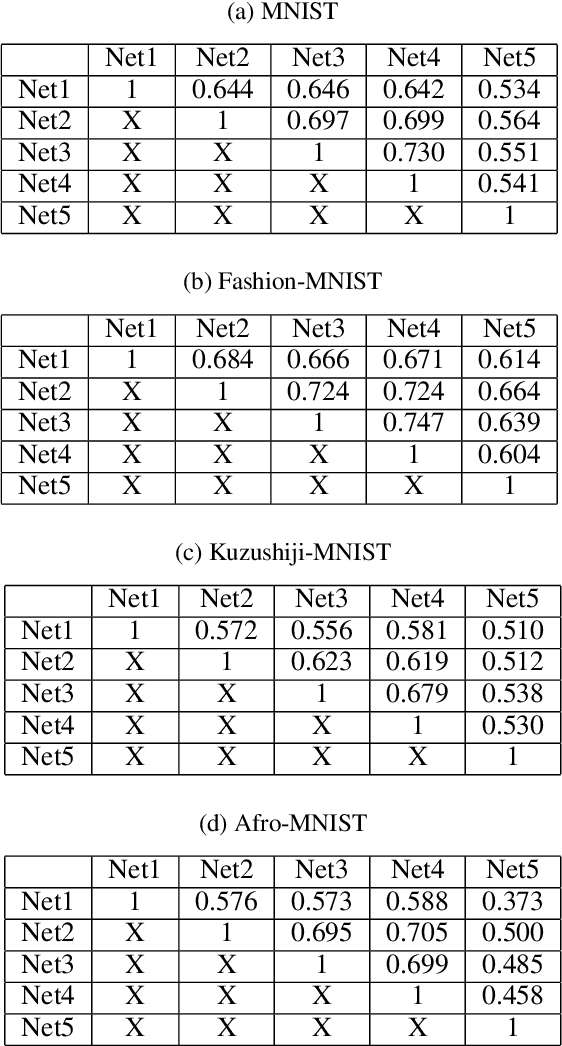
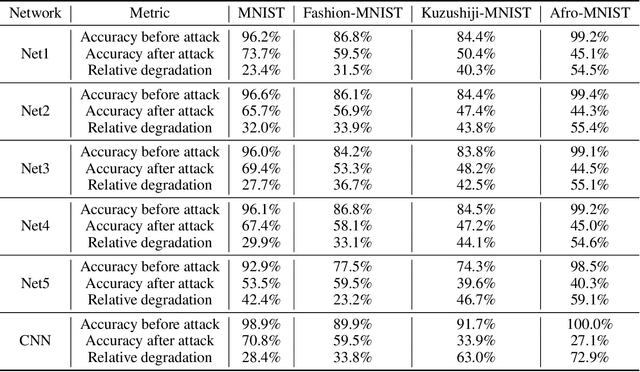
As Artificial Intelligence (AI) models are increasingly integrated into critical systems, the need for a robust framework to establish the trustworthiness of AI is increasingly paramount. While collaborative efforts have established conceptual foundations for such a framework, there remains a significant gap in developing concrete, technically robust methods for assessing AI model quality and performance. A critical drawback in the traditional methods for assessing the validity and generalizability of models is their dependence on internal developer datasets, rendering it challenging to independently assess and verify their performance claims. This paper introduces a novel approach for assessing a newly trained model's performance based on another known model by calculating correlation between neural networks. The proposed method evaluates correlations by determining if, for each neuron in one network, there exists a neuron in the other network that produces similar output. This approach has implications for memory efficiency, allowing for the use of smaller networks when high correlation exists between networks of different sizes. Additionally, the method provides insights into robustness, suggesting that if two highly correlated networks are compared and one demonstrates robustness when operating in production environments, the other is likely to exhibit similar robustness. This contribution advances the technical toolkit for responsible AI, supporting more comprehensive and nuanced evaluations of AI models to ensure their safe and effective deployment.
A Self-supervised Framework for Improved Data-Driven Monitoring of Stress via Multi-modal Passive Sensing
Mar 24, 2023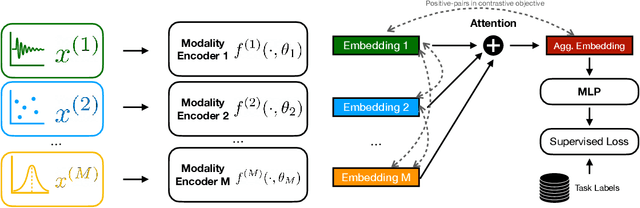

Recent advances in remote health monitoring systems have significantly benefited patients and played a crucial role in improving their quality of life. However, while physiological health-focused solutions have demonstrated increasing success and maturity, mental health-focused applications have seen comparatively limited success in spite of the fact that stress and anxiety disorders are among the most common issues people deal with in their daily lives. In the hopes of furthering progress in this domain through the development of a more robust analytic framework for the measurement of indicators of mental health, we propose a multi-modal semi-supervised framework for tracking physiological precursors of the stress response. Our methodology enables utilizing multi-modal data of differing domains and resolutions from wearable devices and leveraging them to map short-term episodes to semantically efficient embeddings for a given task. Additionally, we leverage an inter-modality contrastive objective, with the advantages of rendering our framework both modular and scalable. The focus on optimizing both local and global aspects of our embeddings via a hierarchical structure renders transferring knowledge and compatibility with other devices easier to achieve. In our pipeline, a task-specific pooling based on an attention mechanism, which estimates the contribution of each modality on an instance level, computes the final embeddings for observations. This additionally provides a thorough diagnostic insight into the data characteristics and highlights the importance of signals in the broader view of predicting episodes annotated per mental health status. We perform training experiments using a corpus of real-world data on perceived stress, and our results demonstrate the efficacy of the proposed approach in performance improvements.
Auditing Algorithmic Fairness in Machine Learning for Health with Severity-Based LOGAN
Nov 16, 2022



Auditing machine learning-based (ML) healthcare tools for bias is critical to preventing patient harm, especially in communities that disproportionately face health inequities. General frameworks are becoming increasingly available to measure ML fairness gaps between groups. However, ML for health (ML4H) auditing principles call for a contextual, patient-centered approach to model assessment. Therefore, ML auditing tools must be (1) better aligned with ML4H auditing principles and (2) able to illuminate and characterize communities vulnerable to the most harm. To address this gap, we propose supplementing ML4H auditing frameworks with SLOGAN (patient Severity-based LOcal Group biAs detectioN), an automatic tool for capturing local biases in a clinical prediction task. SLOGAN adapts an existing tool, LOGAN (LOcal Group biAs detectioN), by contextualizing group bias detection in patient illness severity and past medical history. We investigate and compare SLOGAN's bias detection capabilities to LOGAN and other clustering techniques across patient subgroups in the MIMIC-III dataset. On average, SLOGAN identifies larger fairness disparities in over 75% of patient groups than LOGAN while maintaining clustering quality. Furthermore, in a diabetes case study, health disparity literature corroborates the characterizations of the most biased clusters identified by SLOGAN. Our results contribute to the broader discussion of how machine learning biases may perpetuate existing healthcare disparities.
Beyond Labels: Visual Representations for Bone Marrow Cell Morphology Recognition
May 19, 2022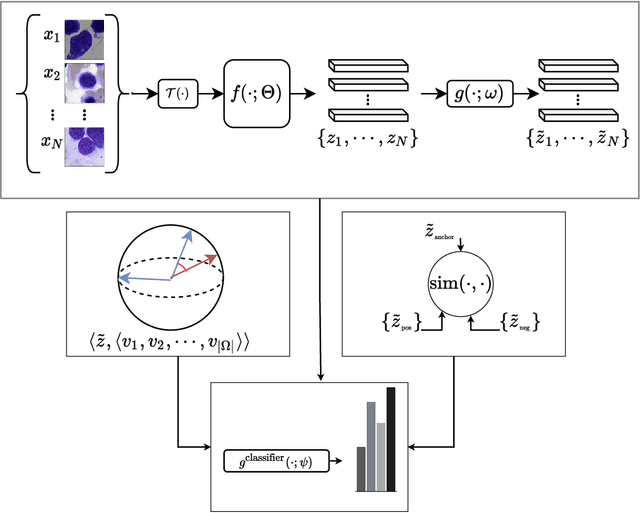
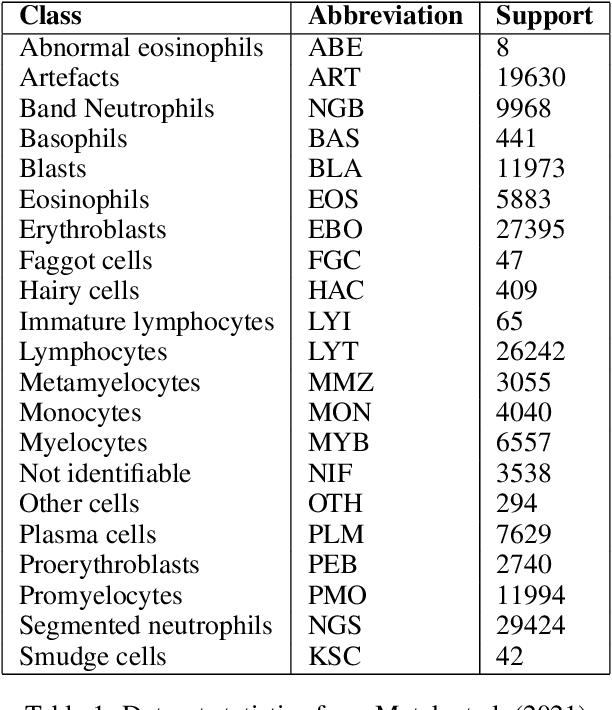
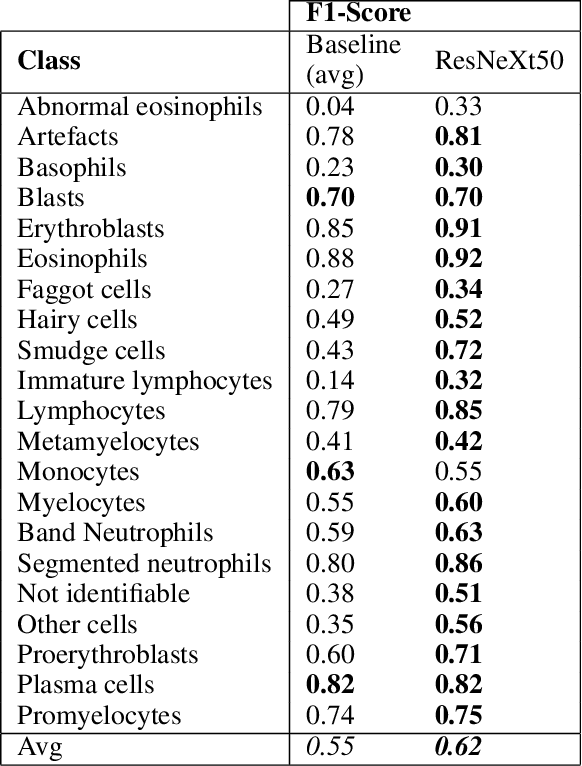
Analyzing and inspecting bone marrow cell cytomorphology is a critical but highly complex and time-consuming component of hematopathology diagnosis. Recent advancements in artificial intelligence have paved the way for the application of deep learning algorithms to complex medical tasks. Nevertheless, there are many challenges in applying effective learning algorithms to medical image analysis, such as the lack of sufficient and reliably annotated training datasets and the highly class-imbalanced nature of most medical data. Here, we improve on the state-of-the-art methodologies of bone marrow cell recognition by deviating from sole reliance on labeled data and leveraging self-supervision in training our learning models. We investigate our approach's effectiveness in identifying bone marrow cell types. Our experiments demonstrate significant performance improvements in conducting different bone marrow cell recognition tasks compared to the current state-of-the-art methodologies.
Contrastive Mixup: Self- and Semi-Supervised learning for Tabular Domain
Sep 01, 2021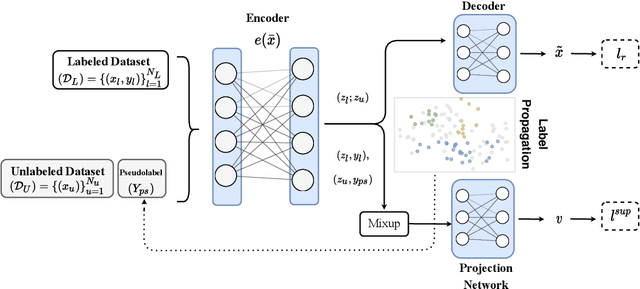
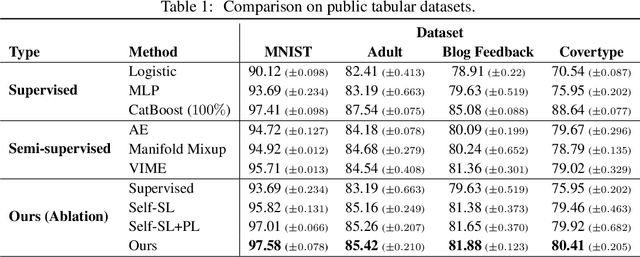
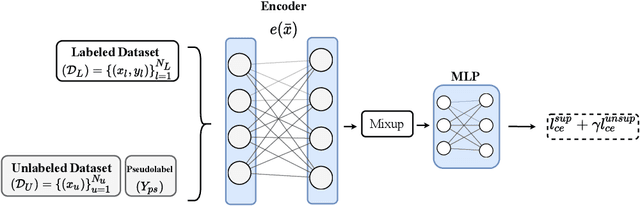
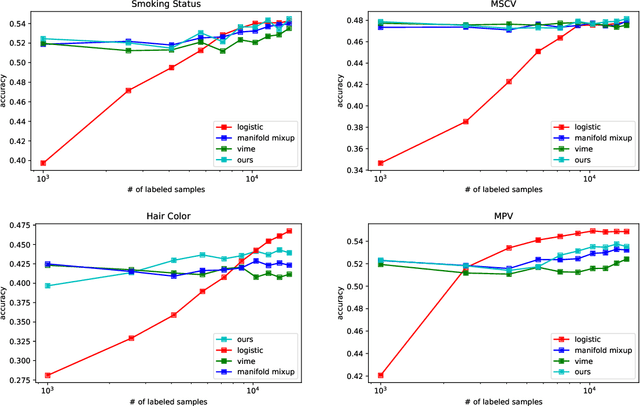
Recent literature in self-supervised has demonstrated significant progress in closing the gap between supervised and unsupervised methods in the image and text domains. These methods rely on domain-specific augmentations that are not directly amenable to the tabular domain. Instead, we introduce Contrastive Mixup, a semi-supervised learning framework for tabular data and demonstrate its effectiveness in limited annotated data settings. Our proposed method leverages Mixup-based augmentation under the manifold assumption by mapping samples to a low dimensional latent space and encourage interpolated samples to have high a similarity within the same labeled class. Unlabeled samples are additionally employed via a transductive label propagation method to further enrich the set of similar and dissimilar pairs that can be used in the contrastive loss term. We demonstrate the effectiveness of the proposed framework on public tabular datasets and real-world clinical datasets.