 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLoP: Multi-Modal Low-Rank Prompting for Efficient Vision-Language Adaptation
Feb 24, 2026Prompt learning has become a dominant paradigm for adapting vision-language models (VLMs) such as CLIP to downstream tasks without modifying pretrained weights. While extending prompts to both vision and text encoders across multiple transformer layers significantly boosts performance, it dramatically increases the number of trainable parameters, with state-of-the-art methods requiring millions of parameters and abandoning the parameter efficiency that makes prompt tuning attractive. In this work, we propose \textbf{MMLoP} (\textbf{M}ulti-\textbf{M}odal \textbf{Lo}w-Rank \textbf{P}rompting), a framework that achieves deep multi-modal prompting with only \textbf{11.5K trainable parameters}, comparable to early text-only methods like CoOp. MMLoP parameterizes vision and text prompts at each transformer layer through a low-rank factorization, which serves as an implicit regularizer against overfitting on few-shot training data. To further close the accuracy gap with state-of-the-art methods, we introduce three complementary components: a self-regulating consistency loss that anchors prompted representations to frozen zero-shot CLIP features at both the feature and logit levels, a uniform drift correction that removes the global embedding shift induced by prompt tuning to preserve class-discriminative structure, and a shared up-projection that couples vision and text prompts through a common low-rank factor to enforce cross-modal alignment. Extensive experiments across three benchmarks and 11 diverse datasets demonstrate that MMLoP achieves a highly favorable accuracy-efficiency tradeoff, outperforming the majority of existing methods including those with orders of magnitude more parameters, while achieving a harmonic mean of 79.70\% on base-to-novel generalization.
MI-to-Mid Distilled Compression (M2M-DC): An Hybrid-Information-Guided-Block Pruning with Progressive Inner Slicing Approach to Model Compression
Nov 18, 2025We introduce MI-to-Mid Distilled Compression (M2M-DC), a two-scale, shape-safe compression framework that interleaves information-guided block pruning with progressive inner slicing and staged knowledge distillation (KD). First, M2M-DC ranks residual (or inverted-residual) blocks by a label-aware mutual information (MI) signal and removes the least informative units (structured prune-after-training). It then alternates short KD phases with stage-coherent, residual-safe channel slicing: (i) stage "planes" (co-slicing conv2 out-channels with the downsample path and next-stage inputs), and (ii) an optional mid-channel trim (conv1 out / bn1 / conv2 in). This targets complementary redundancy, whole computational motifs and within-stage width while preserving residual shape invariants. On CIFAR-100, M2M-DC yields a clean accuracy-compute frontier. For ResNet-18, we obtain 85.46% Top-1 with 3.09M parameters and 0.0139 GMacs (72% params, 63% GMacs vs. teacher; mean final 85.29% over three seeds). For ResNet-34, we reach 85.02% Top-1 with 5.46M params and 0.0195 GMacs (74% / 74% vs. teacher; mean final 84.62%). Extending to inverted-residuals, MobileNetV2 achieves a mean final 68.54% Top-1 at 1.71M params (27%) and 0.0186 conv GMacs (24%), improving over the teacher's 66.03% by +2.5 points across three seeds. Because M2M-DC exposes only a thin, architecture-aware interface (blocks, stages, and down sample/skip wiring), it generalizes across residual CNNs and extends to inverted-residual families with minor legalization rules. The result is a compact, practical recipe for deployment-ready models that match or surpass teacher accuracy at a fraction of the compute.
Few-Shot Adversarial Low-Rank Fine-Tuning of Vision-Language Models
May 21, 2025Vision-Language Models (VLMs) such as CLIP have shown remarkable performance in cross-modal tasks through large-scale contrastive pre-training. To adapt these large transformer-based models efficiently for downstream tasks, Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA have emerged as scalable alternatives to full fine-tuning, especially in few-shot scenarios. However, like traditional deep neural networks, VLMs are highly vulnerable to adversarial attacks, where imperceptible perturbations can significantly degrade model performance. Adversarial training remains the most effective strategy for improving model robustness in PEFT. In this work, we propose AdvCLIP-LoRA, the first algorithm designed to enhance the adversarial robustness of CLIP models fine-tuned with LoRA in few-shot settings. Our method formulates adversarial fine-tuning as a minimax optimization problem and provides theoretical guarantees for convergence under smoothness and nonconvex-strong-concavity assumptions. Empirical results across eight datasets using ViT-B/16 and ViT-B/32 models show that AdvCLIP-LoRA significantly improves robustness against common adversarial attacks (e.g., FGSM, PGD), without sacrificing much clean accuracy. These findings highlight AdvCLIP-LoRA as a practical and theoretically grounded approach for robust adaptation of VLMs in resource-constrained settings.
Exploring a Datasets Statistical Effect Size Impact on Model Performance, and Data Sample-Size Sufficiency
Jan 05, 2025Having a sufficient quantity of quality data is a critical enabler of training effective machine learning models. Being able to effectively determine the adequacy of a dataset prior to training and evaluating a model's performance would be an essential tool for anyone engaged in experimental design or data collection. However, despite the need for it, the ability to prospectively assess data sufficiency remains an elusive capability. We report here on two experiments undertaken in an attempt to better ascertain whether or not basic descriptive statistical measures can be indicative of how effective a dataset will be at training a resulting model. Leveraging the effect size of our features, this work first explores whether or not a correlation exists between effect size, and resulting model performance (theorizing that the magnitude of the distinction between classes could correlate to a classifier's resulting success). We then explore whether or not the magnitude of the effect size will impact the rate of convergence of our learning rate, (theorizing again that a greater effect size may indicate that the model will converge more rapidly, and with a smaller sample size needed). Our results appear to indicate that this is not an effective heuristic for determining adequate sample size or projecting model performance, and therefore that additional work is still needed to better prospectively assess adequacy of data.
Leveraging Large Language Models and Topic Modeling for Toxicity Classification
Nov 26, 2024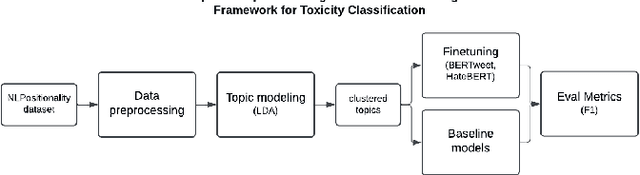
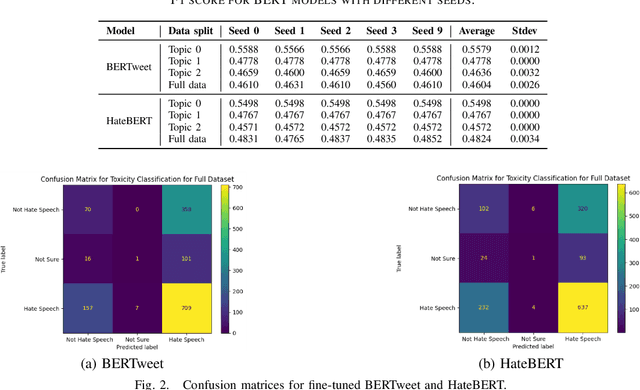

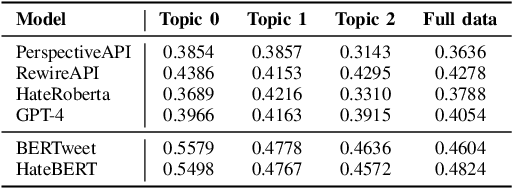
Content moderation and toxicity classification represent critical tasks with significant social implications. However, studies have shown that major classification models exhibit tendencies to magnify or reduce biases and potentially overlook or disadvantage certain marginalized groups within their classification processes. Researchers suggest that the positionality of annotators influences the gold standard labels in which the models learned from propagate annotators' bias. To further investigate the impact of annotator positionality, we delve into fine-tuning BERTweet and HateBERT on the dataset while using topic-modeling strategies for content moderation. The results indicate that fine-tuning the models on specific topics results in a notable improvement in the F1 score of the models when compared to the predictions generated by other prominent classification models such as GPT-4, PerspectiveAPI, and RewireAPI. These findings further reveal that the state-of-the-art large language models exhibit significant limitations in accurately detecting and interpreting text toxicity contrasted with earlier methodologies. Code is available at https://github.com/aheldis/Toxicity-Classification.git.
Exploring Cross-model Neuronal Correlations in the Context of Predicting Model Performance and Generalizability
Aug 15, 2024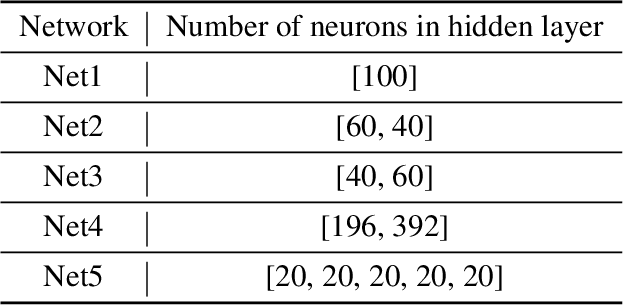
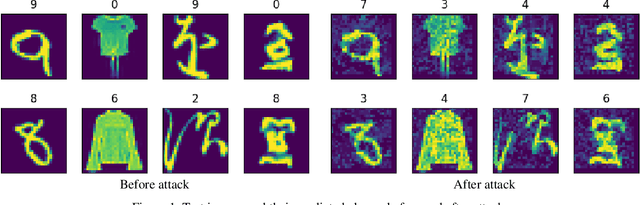
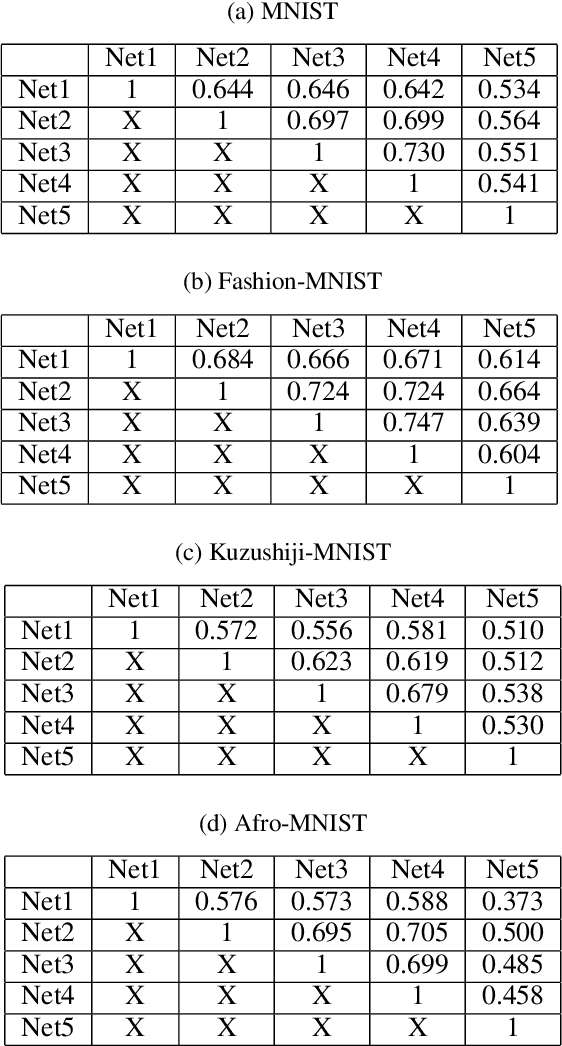
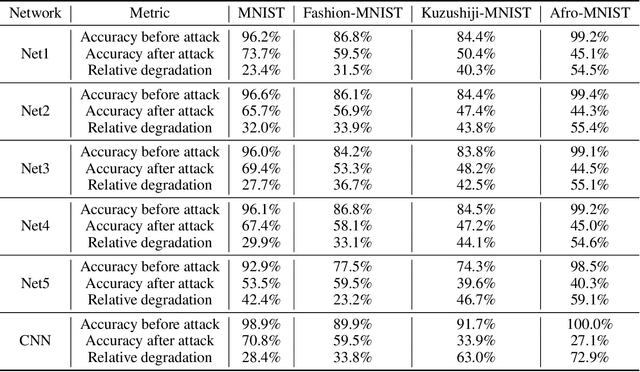
As Artificial Intelligence (AI) models are increasingly integrated into critical systems, the need for a robust framework to establish the trustworthiness of AI is increasingly paramount. While collaborative efforts have established conceptual foundations for such a framework, there remains a significant gap in developing concrete, technically robust methods for assessing AI model quality and performance. A critical drawback in the traditional methods for assessing the validity and generalizability of models is their dependence on internal developer datasets, rendering it challenging to independently assess and verify their performance claims. This paper introduces a novel approach for assessing a newly trained model's performance based on another known model by calculating correlation between neural networks. The proposed method evaluates correlations by determining if, for each neuron in one network, there exists a neuron in the other network that produces similar output. This approach has implications for memory efficiency, allowing for the use of smaller networks when high correlation exists between networks of different sizes. Additionally, the method provides insights into robustness, suggesting that if two highly correlated networks are compared and one demonstrates robustness when operating in production environments, the other is likely to exhibit similar robustness. This contribution advances the technical toolkit for responsible AI, supporting more comprehensive and nuanced evaluations of AI models to ensure their safe and effective deployment.
Attack on Scene Flow using Point Clouds
Apr 28, 2024



Deep neural networks have made significant advancements in accurately estimating scene flow using point clouds, which is vital for many applications like video analysis, action recognition, and navigation. Robustness of these techniques, however, remains a concern, particularly in the face of adversarial attacks that have been proven to deceive state-of-the-art deep neural networks in many domains. Surprisingly, the robustness of scene flow networks against such attacks has not been thoroughly investigated. To address this problem, the proposed approach aims to bridge this gap by introducing adversarial white-box attacks specifically tailored for scene flow networks. Experimental results show that the generated adversarial examples obtain up to 33.7 relative degradation in average end-point error on the KITTI and FlyingThings3D datasets. The study also reveals the significant impact that attacks targeting point clouds in only one dimension or color channel have on average end-point error. Analyzing the success and failure of these attacks on the scene flow networks and their 2D optical flow network variants show a higher vulnerability for the optical flow networks.
Interpretation of Neural Networks is Susceptible to Universal Adversarial Perturbations
Nov 30, 2022



Interpreting neural network classifiers using gradient-based saliency maps has been extensively studied in the deep learning literature. While the existing algorithms manage to achieve satisfactory performance in application to standard image recognition datasets, recent works demonstrate the vulnerability of widely-used gradient-based interpretation schemes to norm-bounded perturbations adversarially designed for every individual input sample. However, such adversarial perturbations are commonly designed using the knowledge of an input sample, and hence perform sub-optimally in application to an unknown or constantly changing data point. In this paper, we show the existence of a Universal Perturbation for Interpretation (UPI) for standard image datasets, which can alter a gradient-based feature map of neural networks over a significant fraction of test samples. To design such a UPI, we propose a gradient-based optimization method as well as a principal component analysis (PCA)-based approach to compute a UPI which can effectively alter a neural network's gradient-based interpretation on different samples. We support the proposed UPI approaches by presenting several numerical results of their successful applications to standard image datasets.