 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Knowledge Distillation with Cross-Modal Teacher Fusion
Nov 12, 2025Multi-teacher knowledge distillation (KD), a more effective technique than traditional single-teacher methods, transfers knowledge from expert teachers to a compact student model using logit or feature matching. However, most existing approaches lack knowledge diversity, as they rely solely on unimodal visual information, overlooking the potential of cross-modal representations. In this work, we explore the use of CLIP's vision-language knowledge as a complementary source of supervision for KD, an area that remains largely underexplored. We propose a simple yet effective framework that fuses the logits and features of a conventional teacher with those from CLIP. By incorporating CLIP's multi-prompt textual guidance, the fused supervision captures both dataset-specific and semantically enriched visual cues. Beyond accuracy, analysis shows that the fused teacher yields more confident and reliable predictions, significantly increasing confident-correct cases while reducing confidently wrong ones. Moreover, fusion with CLIP refines the entire logit distribution, producing semantically meaningful probabilities for non-target classes, thereby improving inter-class consistency and distillation quality. Despite its simplicity, the proposed method, Enriching Knowledge Distillation (RichKD), consistently outperforms most existing baselines across multiple benchmarks and exhibits stronger robustness under distribution shifts and input corruptions.
KNN-Defense: Defense against 3D Adversarial Point Clouds using Nearest-Neighbor Search
Jun 07, 2025Deep neural networks (DNNs) have demonstrated remarkable performance in analyzing 3D point cloud data. However, their vulnerability to adversarial attacks-such as point dropping, shifting, and adding-poses a critical challenge to the reliability of 3D vision systems. These attacks can compromise the semantic and structural integrity of point clouds, rendering many existing defense mechanisms ineffective. To address this issue, a defense strategy named KNN-Defense is proposed, grounded in the manifold assumption and nearest-neighbor search in feature space. Instead of reconstructing surface geometry or enforcing uniform point distributions, the method restores perturbed inputs by leveraging the semantic similarity of neighboring samples from the training set. KNN-Defense is lightweight and computationally efficient, enabling fast inference and making it suitable for real-time and practical applications. Empirical results on the ModelNet40 dataset demonstrated that KNN-Defense significantly improves robustness across various attack types. In particular, under point-dropping attacks-where many existing methods underperform due to the targeted removal of critical points-the proposed method achieves accuracy gains of 20.1%, 3.6%, 3.44%, and 7.74% on PointNet, PointNet++, DGCNN, and PCT, respectively. These findings suggest that KNN-Defense offers a scalable and effective solution for enhancing the adversarial resilience of 3D point cloud classifiers. (An open-source implementation of the method, including code and data, is available at https://github.com/nimajam41/3d-knn-defense).
Emotion Alignment: Discovering the Gap Between Social Media and Real-World Sentiments in Persian Tweets and Images
Apr 14, 2025In contemporary society, widespread social media usage is evident in people's daily lives. Nevertheless, disparities in emotional expressions between the real world and online platforms can manifest. We comprehensively analyzed Persian community on X to explore this phenomenon. An innovative pipeline was designed to measure the similarity between emotions in the real world compared to social media. Accordingly, recent tweets and images of participants were gathered and analyzed using Transformers-based text and image sentiment analysis modules. Each participant's friends also provided insights into the their real-world emotions. A distance criterion was used to compare real-world feelings with virtual experiences. Our study encompassed N=105 participants, 393 friends who contributed their perspectives, over 8,300 collected tweets, and 2,000 media images. Results indicated a 28.67% similarity between images and real-world emotions, while tweets exhibited a 75.88% alignment with real-world feelings. Additionally, the statistical significance confirmed that the observed disparities in sentiment proportions.
Eigen-Cluster VIS: Improving Weakly-supervised Video Instance Segmentation by Leveraging Spatio-temporal Consistency
Aug 29, 2024
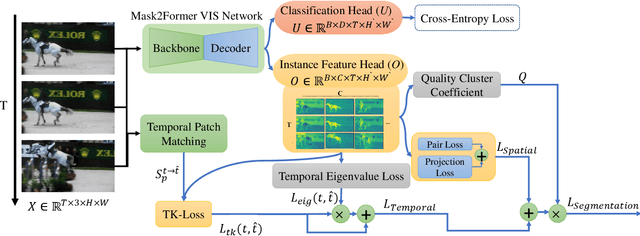
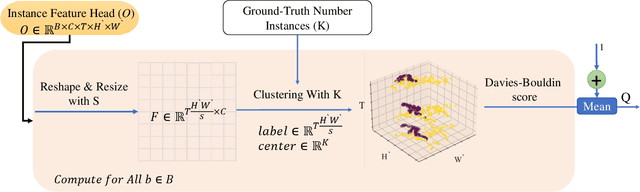
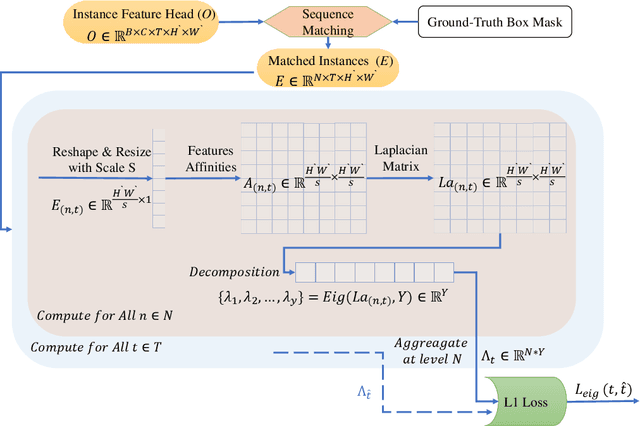
The performance of Video Instance Segmentation (VIS) methods has improved significantly with the advent of transformer networks. However, these networks often face challenges in training due to the high annotation cost. To address this, unsupervised and weakly-supervised methods have been developed to reduce the dependency on annotations. This work introduces a novel weakly-supervised method called Eigen-cluster VIS that, without requiring any mask annotations, achieves competitive accuracy compared to other VIS approaches. This method is based on two key innovations: a Temporal Eigenvalue Loss (TEL) and a clip-level Quality Cluster Coefficient (QCC). The TEL ensures temporal coherence by leveraging the eigenvalues of the Laplacian matrix derived from graph adjacency matrices. By minimizing the mean absolute error (MAE) between the eigenvalues of adjacent frames, this loss function promotes smooth transitions and stable segmentation boundaries over time, reducing temporal discontinuities and improving overall segmentation quality. The QCC employs the K-means method to ensure the quality of spatio-temporal clusters without relying on ground truth masks. Using the Davies-Bouldin score, the QCC provides an unsupervised measure of feature discrimination, allowing the model to self-evaluate and adapt to varying object distributions, enhancing robustness during the testing phase. These enhancements are computationally efficient and straightforward, offering significant performance gains without additional annotated data. The proposed Eigen-Cluster VIS method is evaluated on the YouTube-VIS 2019/2021 and OVIS datasets, demonstrating that it effectively narrows the performance gap between the fully-supervised and weakly-supervised VIS approaches. The code is available on: https://github.com/farnooshar/EigenClusterVIS
Attack on Scene Flow using Point Clouds
Apr 28, 2024



Deep neural networks have made significant advancements in accurately estimating scene flow using point clouds, which is vital for many applications like video analysis, action recognition, and navigation. Robustness of these techniques, however, remains a concern, particularly in the face of adversarial attacks that have been proven to deceive state-of-the-art deep neural networks in many domains. Surprisingly, the robustness of scene flow networks against such attacks has not been thoroughly investigated. To address this problem, the proposed approach aims to bridge this gap by introducing adversarial white-box attacks specifically tailored for scene flow networks. Experimental results show that the generated adversarial examples obtain up to 33.7 relative degradation in average end-point error on the KITTI and FlyingThings3D datasets. The study also reveals the significant impact that attacks targeting point clouds in only one dimension or color channel have on average end-point error. Analyzing the success and failure of these attacks on the scene flow networks and their 2D optical flow network variants show a higher vulnerability for the optical flow networks.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024



Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
Attention-guided Feature Distillation for Semantic Segmentation
Mar 08, 2024



In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, the pro-posed method showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, em-ploys the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. By only using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student,AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of mean Intersection over Union (mIoU) on the PascalVoc 2012 and Cityscapes datasets. The Code is available at https://github.com/AmirMansurian/AttnFD.
Deep Spectral Improvement for Unsupervised Image Instance Segmentation
Feb 06, 2024



Deep spectral methods reframe the image decomposition process as a graph partitioning task by extracting features using self-supervised learning and utilizing the Laplacian of the affinity matrix to obtain eigensegments. However, instance segmentation has received less attention compared to other tasks within the context of deep spectral methods. This paper addresses the fact that not all channels of the feature map extracted from a self-supervised backbone contain sufficient information for instance segmentation purposes. In fact, Some channels are noisy and hinder the accuracy of the task. To overcome this issue, this paper proposes two channel reduction modules: Noise Channel Reduction (NCR) and Deviation-based Channel Reduction (DCR). The NCR retains channels with lower entropy, as they are less likely to be noisy, while DCR prunes channels with low standard deviation, as they lack sufficient information for effective instance segmentation. Furthermore, the paper demonstrates that the dot product, commonly used in deep spectral methods, is not suitable for instance segmentation due to its sensitivity to feature map values, potentially leading to incorrect instance segments. A new similarity metric called Bray-Curtis over Chebyshev (BoC) is proposed to address this issue. It takes into account the distribution of features in addition to their values, providing a more robust similarity measure for instance segmentation. Quantitative and qualitative results on the Youtube-VIS2019 dataset highlight the improvements achieved by the proposed channel reduction methods and the use of BoC instead of the conventional dot product for creating the affinity matrix. These improvements are observed in terms of mean Intersection over Union and extracted instance segments, demonstrating enhanced instance segmentation performance. The code is available on: https://github.com/farnooshar/SpecUnIIS
Leveraging Swin Transformer for Local-to-Global Weakly Supervised Semantic Segmentation
Jan 31, 2024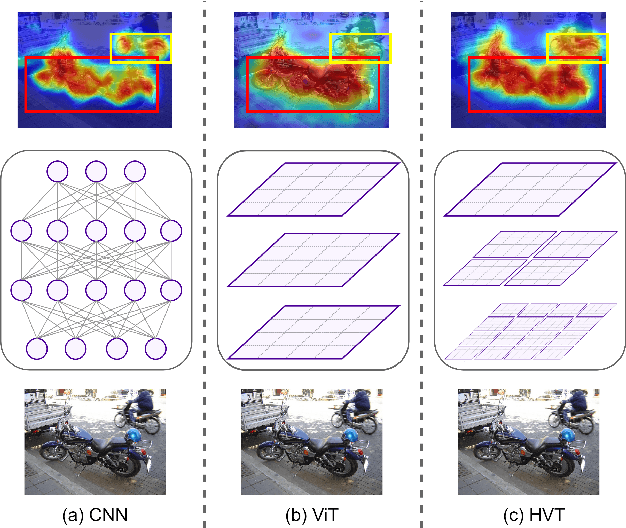



In recent years, weakly supervised semantic segmentation using image-level labels as supervision has received significant attention in the field of computer vision. Most existing methods have addressed the challenges arising from the lack of spatial information in these labels by focusing on facilitating supervised learning through the generation of pseudo-labels from class activation maps (CAMs). Due to the localized pattern detection of Convolutional Neural Networks (CNNs), CAMs often emphasize only the most discriminative parts of an object, making it challenging to accurately distinguish foreground objects from each other and the background. Recent studies have shown that Vision Transformer (ViT) features, due to their global view, are more effective in capturing the scene layout than CNNs. However, the use of hierarchical ViTs has not been extensively explored in this field. This work explores the use of Swin Transformer by proposing "SWTformer" to enhance the accuracy of the initial seed CAMs by bringing local and global views together. SWTformer-V1 generates class probabilities and CAMs using only the patch tokens as features. SWTformer-V2 incorporates a multi-scale feature fusion mechanism to extract additional information and utilizes a background-aware mechanism to generate more accurate localization maps with improved cross-object discrimination. Based on experiments on the PascalVOC 2012 dataset, SWTformer-V1 achieves a 0.98% mAP higher localization accuracy, outperforming state-of-the-art models. It also yields comparable performance by 0.82% mIoU on average higher than other methods in generating initial localization maps, depending only on the classification network. SWTformer-V2 further improves the accuracy of the generated seed CAMs by 5.32% mIoU, further proving the effectiveness of the local-to-global view provided by the Swin transformer.
Multi-task Learning for Joint Re-identification, Team Affiliation, and Role Classification for Sports Visual Tracking
Jan 18, 2024Effective tracking and re-identification of players is essential for analyzing soccer videos. But, it is a challenging task due to the non-linear motion of players, the similarity in appearance of players from the same team, and frequent occlusions. Therefore, the ability to extract meaningful embeddings to represent players is crucial in developing an effective tracking and re-identification system. In this paper, a multi-purpose part-based person representation method, called PRTreID, is proposed that performs three tasks of role classification, team affiliation, and re-identification, simultaneously. In contrast to available literature, a single network is trained with multi-task supervision to solve all three tasks, jointly. The proposed joint method is computationally efficient due to the shared backbone. Also, the multi-task learning leads to richer and more discriminative representations, as demonstrated by both quantitative and qualitative results. To demonstrate the effectiveness of PRTreID, it is integrated with a state-of-the-art tracking method, using a part-based post-processing module to handle long-term tracking. The proposed tracking method outperforms all existing tracking methods on the challenging SoccerNet tracking dataset.