 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-guided Feature Distillation for Semantic Segmentation
Mar 08, 2024



In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, the pro-posed method showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, em-ploys the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. By only using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student,AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of mean Intersection over Union (mIoU) on the PascalVoc 2012 and Cityscapes datasets. The Code is available at https://github.com/AmirMansurian/AttnFD.
Leveraging Swin Transformer for Local-to-Global Weakly Supervised Semantic Segmentation
Jan 31, 2024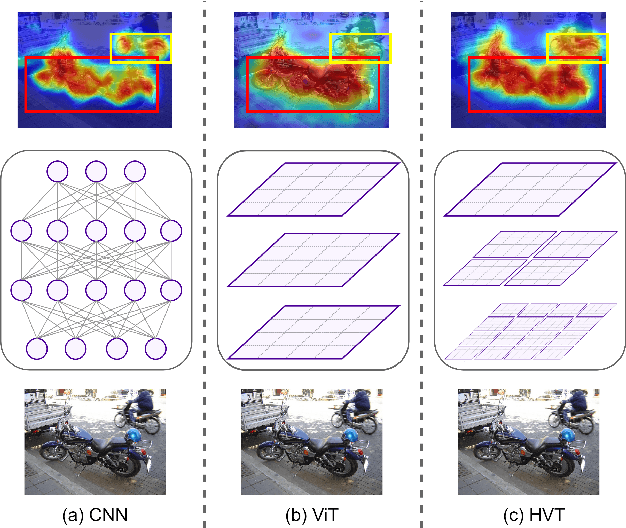



In recent years, weakly supervised semantic segmentation using image-level labels as supervision has received significant attention in the field of computer vision. Most existing methods have addressed the challenges arising from the lack of spatial information in these labels by focusing on facilitating supervised learning through the generation of pseudo-labels from class activation maps (CAMs). Due to the localized pattern detection of Convolutional Neural Networks (CNNs), CAMs often emphasize only the most discriminative parts of an object, making it challenging to accurately distinguish foreground objects from each other and the background. Recent studies have shown that Vision Transformer (ViT) features, due to their global view, are more effective in capturing the scene layout than CNNs. However, the use of hierarchical ViTs has not been extensively explored in this field. This work explores the use of Swin Transformer by proposing "SWTformer" to enhance the accuracy of the initial seed CAMs by bringing local and global views together. SWTformer-V1 generates class probabilities and CAMs using only the patch tokens as features. SWTformer-V2 incorporates a multi-scale feature fusion mechanism to extract additional information and utilizes a background-aware mechanism to generate more accurate localization maps with improved cross-object discrimination. Based on experiments on the PascalVOC 2012 dataset, SWTformer-V1 achieves a 0.98% mAP higher localization accuracy, outperforming state-of-the-art models. It also yields comparable performance by 0.82% mIoU on average higher than other methods in generating initial localization maps, depending only on the classification network. SWTformer-V2 further improves the accuracy of the generated seed CAMs by 5.32% mIoU, further proving the effectiveness of the local-to-global view provided by the Swin transformer.
AICSD: Adaptive Inter-Class Similarity Distillation for Semantic Segmentation
Aug 08, 2023



In recent years, deep neural networks have achieved remarkable accuracy in computer vision tasks. With inference time being a crucial factor, particularly in dense prediction tasks such as semantic segmentation, knowledge distillation has emerged as a successful technique for improving the accuracy of lightweight student networks. The existing methods often neglect the information in channels and among different classes. To overcome these limitations, this paper proposes a novel method called Inter-Class Similarity Distillation (ICSD) for the purpose of knowledge distillation. The proposed method transfers high-order relations from the teacher network to the student network by independently computing intra-class distributions for each class from network outputs. This is followed by calculating inter-class similarity matrices for distillation using KL divergence between distributions of each pair of classes. To further improve the effectiveness of the proposed method, an Adaptive Loss Weighting (ALW) training strategy is proposed. Unlike existing methods, the ALW strategy gradually reduces the influence of the teacher network towards the end of training process to account for errors in teacher's predictions. Extensive experiments conducted on two well-known datasets for semantic segmentation, Cityscapes and Pascal VOC 2012, validate the effectiveness of the proposed method in terms of mIoU and pixel accuracy. The proposed method outperforms most of existing knowledge distillation methods as demonstrated by both quantitative and qualitative evaluations. Code is available at: https://github.com/AmirMansurian/AICSD