 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigen-Cluster VIS: Improving Weakly-supervised Video Instance Segmentation by Leveraging Spatio-temporal Consistency
Aug 29, 2024
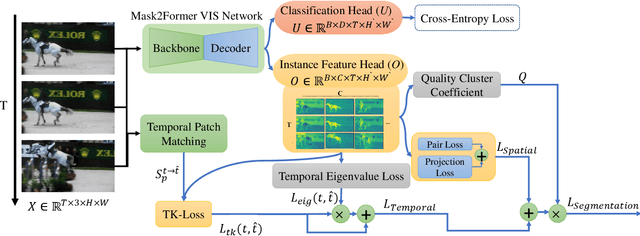
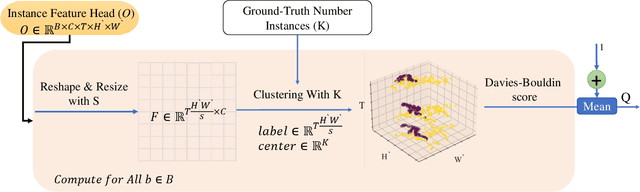
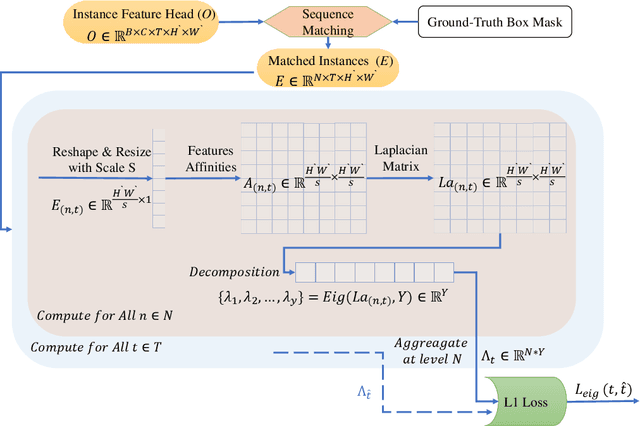
The performance of Video Instance Segmentation (VIS) methods has improved significantly with the advent of transformer networks. However, these networks often face challenges in training due to the high annotation cost. To address this, unsupervised and weakly-supervised methods have been developed to reduce the dependency on annotations. This work introduces a novel weakly-supervised method called Eigen-cluster VIS that, without requiring any mask annotations, achieves competitive accuracy compared to other VIS approaches. This method is based on two key innovations: a Temporal Eigenvalue Loss (TEL) and a clip-level Quality Cluster Coefficient (QCC). The TEL ensures temporal coherence by leveraging the eigenvalues of the Laplacian matrix derived from graph adjacency matrices. By minimizing the mean absolute error (MAE) between the eigenvalues of adjacent frames, this loss function promotes smooth transitions and stable segmentation boundaries over time, reducing temporal discontinuities and improving overall segmentation quality. The QCC employs the K-means method to ensure the quality of spatio-temporal clusters without relying on ground truth masks. Using the Davies-Bouldin score, the QCC provides an unsupervised measure of feature discrimination, allowing the model to self-evaluate and adapt to varying object distributions, enhancing robustness during the testing phase. These enhancements are computationally efficient and straightforward, offering significant performance gains without additional annotated data. The proposed Eigen-Cluster VIS method is evaluated on the YouTube-VIS 2019/2021 and OVIS datasets, demonstrating that it effectively narrows the performance gap between the fully-supervised and weakly-supervised VIS approaches. The code is available on: https://github.com/farnooshar/EigenClusterVIS
Deep Spectral Improvement for Unsupervised Image Instance Segmentation
Feb 06, 2024



Deep spectral methods reframe the image decomposition process as a graph partitioning task by extracting features using self-supervised learning and utilizing the Laplacian of the affinity matrix to obtain eigensegments. However, instance segmentation has received less attention compared to other tasks within the context of deep spectral methods. This paper addresses the fact that not all channels of the feature map extracted from a self-supervised backbone contain sufficient information for instance segmentation purposes. In fact, Some channels are noisy and hinder the accuracy of the task. To overcome this issue, this paper proposes two channel reduction modules: Noise Channel Reduction (NCR) and Deviation-based Channel Reduction (DCR). The NCR retains channels with lower entropy, as they are less likely to be noisy, while DCR prunes channels with low standard deviation, as they lack sufficient information for effective instance segmentation. Furthermore, the paper demonstrates that the dot product, commonly used in deep spectral methods, is not suitable for instance segmentation due to its sensitivity to feature map values, potentially leading to incorrect instance segments. A new similarity metric called Bray-Curtis over Chebyshev (BoC) is proposed to address this issue. It takes into account the distribution of features in addition to their values, providing a more robust similarity measure for instance segmentation. Quantitative and qualitative results on the Youtube-VIS2019 dataset highlight the improvements achieved by the proposed channel reduction methods and the use of BoC instead of the conventional dot product for creating the affinity matrix. These improvements are observed in terms of mean Intersection over Union and extracted instance segments, demonstrating enhanced instance segmentation performance. The code is available on: https://github.com/farnooshar/SpecUnIIS
Rethinking RAFT for Efficient Optical Flow
Jan 01, 2024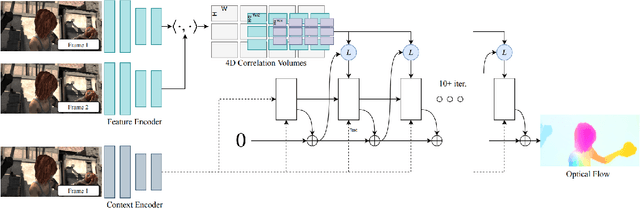
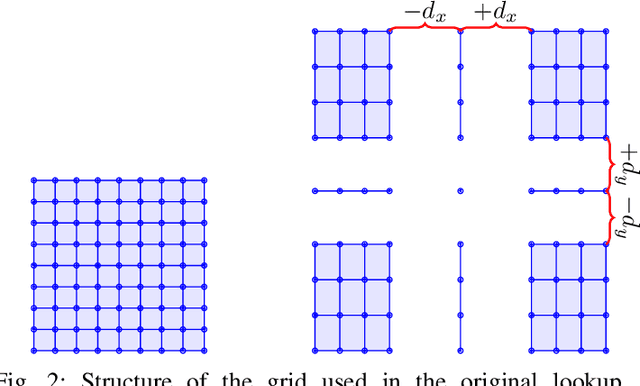
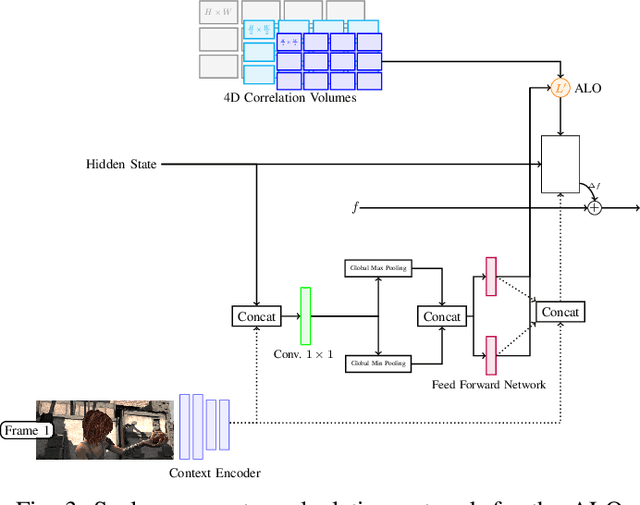
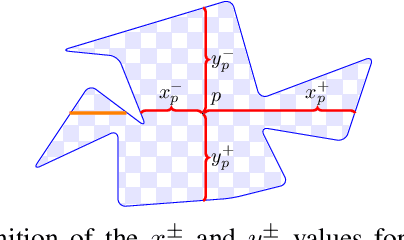
Despite significant progress in deep learning-based optical flow methods, accurately estimating large displacements and repetitive patterns remains a challenge. The limitations of local features and similarity search patterns used in these algorithms contribute to this issue. Additionally, some existing methods suffer from slow runtime and excessive graphic memory consumption. To address these problems, this paper proposes a novel approach based on the RAFT framework. The proposed Attention-based Feature Localization (AFL) approach incorporates the attention mechanism to handle global feature extraction and address repetitive patterns. It introduces an operator for matching pixels with corresponding counterparts in the second frame and assigning accurate flow values. Furthermore, an Amorphous Lookup Operator (ALO) is proposed to enhance convergence speed and improve RAFTs ability to handle large displacements by reducing data redundancy in its search operator and expanding the search space for similarity extraction. The proposed method, Efficient RAFT (Ef-RAFT),achieves significant improvements of 10% on the Sintel dataset and 5% on the KITTI dataset over RAFT. Remarkably, these enhancements are attained with a modest 33% reduction in speed and a mere 13% increase in memory usage. The code is available at: https://github.com/n3slami/Ef-RAFT