 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigen-Cluster VIS: Improving Weakly-supervised Video Instance Segmentation by Leveraging Spatio-temporal Consistency
Paper and Code

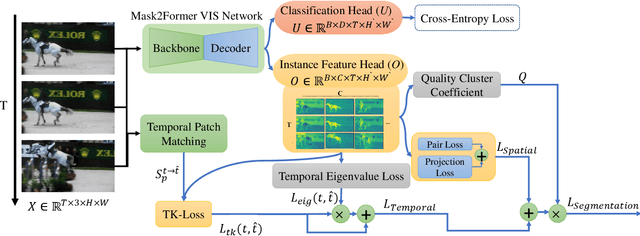
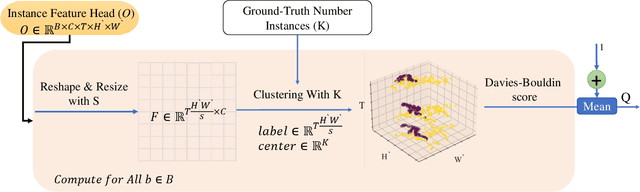
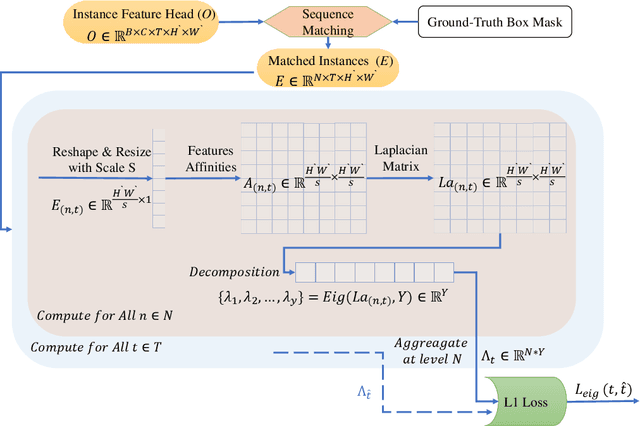
The performance of Video Instance Segmentation (VIS) methods has improved significantly with the advent of transformer networks. However, these networks often face challenges in training due to the high annotation cost. To address this, unsupervised and weakly-supervised methods have been developed to reduce the dependency on annotations. This work introduces a novel weakly-supervised method called Eigen-cluster VIS that, without requiring any mask annotations, achieves competitive accuracy compared to other VIS approaches. This method is based on two key innovations: a Temporal Eigenvalue Loss (TEL) and a clip-level Quality Cluster Coefficient (QCC). The TEL ensures temporal coherence by leveraging the eigenvalues of the Laplacian matrix derived from graph adjacency matrices. By minimizing the mean absolute error (MAE) between the eigenvalues of adjacent frames, this loss function promotes smooth transitions and stable segmentation boundaries over time, reducing temporal discontinuities and improving overall segmentation quality. The QCC employs the K-means method to ensure the quality of spatio-temporal clusters without relying on ground truth masks. Using the Davies-Bouldin score, the QCC provides an unsupervised measure of feature discrimination, allowing the model to self-evaluate and adapt to varying object distributions, enhancing robustness during the testing phase. These enhancements are computationally efficient and straightforward, offering significant performance gains without additional annotated data. The proposed Eigen-Cluster VIS method is evaluated on the YouTube-VIS 2019/2021 and OVIS datasets, demonstrating that it effectively narrows the performance gap between the fully-supervised and weakly-supervised VIS approaches. The code is available on: https://github.com/farnooshar/EigenClusterVIS