 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-based Spacecraft Reconstruction from Monocular Imagery Under Illumination Variability and Pose Uncertainty
May 20, 2026Autonomous rendezvous and proximity operations around uncooperative, unknown spacecraft are critical for active debris removal and on-orbit servicing missions. A key component of such operations is the offline reconstruction of a 3D model of the target from a set of 2D images. This task is challenging due to two main factors. First, in-orbit illumination conditions exhibit considerable variability, and change rapidly over time. Second, the inaccuracy of pose information in the images, results in 3D reconstruction uncertainty. To overcome these challenges, we propose to extend Neural Radiance Fields with per-image degrees of freedom: a learnable appearance embedding that captures the illumination conditions specific to each image, and an image-specific pose correction term that refines its noisy pose label to increase 3D consistency across images. These parameters add minimal complexity, as they are learned jointly with the NeRF, yet they substantially improve robustness to illumination variability and pose inaccuracies. We validate our approach on three image sets representative of in-orbit operations, demonstrating its effectiveness for offline reconstruction and highlighting its suitability for online reconstruction, an open problem in the field.
CAD-Free Learning of Spacecraft Pose Estimators via NeRF-Based Augmentations
May 20, 2026Spacecraft pose estimation networks require tens of thousands of CAD-rendered images to be trained. This reliance on synthetic CAD data (i) limits applicability to targets with reliable geometry prior, excluding uncooperative or poorly documented spacecraft, and (ii) causes poor generalization to real on-orbit conditions due to unrealistic illumination and material appearance. This paper introduces a NeRF-based image augmentation method that enables the learning of spacecraft pose estimators from only a few tens to a few hundreds of images. The method learns a Neural Radiance Field of the target and generates a large, diverse dataset through geometrically-consistent viewpoint and appearance augmentation. This augmented dataset enables the training of accurate target-specific pose estimators without requiring a CAD model or large synthetic datasets. Experiments show that our approach supports the training of accurate pose estimators from only 25 to 400 realistic images, even under severe illumination variations. When applied on large CAD-based synthetic datasets, the NeRF-based augmentation also enhances out-of-domain generalization, yielding improved robustness to real on-orbit conditions.
Conditional Random Fields for Interactive Refinement of Histopathological Predictions
Jan 17, 2026Assisting pathologists in the analysis of histopathological images has high clinical value, as it supports cancer detection and staging. In this context, histology foundation models have recently emerged. Among them, Vision-Language Models (VLMs) provide strong yet imperfect zero-shot predictions. We propose to refine these predictions by adapting Conditional Random Fields (CRFs) to histopathological applications, requiring no additional model training. We present HistoCRF, a CRF-based framework, with a novel definition of the pairwise potential that promotes label diversity and leverages expert annotations. We consider three experiments: without annotations, with expert annotations, and with iterative human-in-the-loop annotations that progressively correct misclassified patches. Experiments on five patch-level classification datasets covering different organs and diseases demonstrate average accuracy gains of 16.0% without annotations and 27.5% with only 100 annotations, compared to zero-shot predictions. Moreover, integrating a human in the loop reaches a further gain of 32.6% with the same number of annotations. The code will be made available on https://github.com/tgodelaine/HistoCRF.
Leveraging Prediction Entropy for Automatic Prompt Weighting in Zero-Shot Audio-Language Classification
Jan 08, 2026Audio-language models have recently demonstrated strong zero-shot capabilities by leveraging natural-language supervision to classify audio events without labeled training data. Yet, their performance is highly sensitive to the wording of text prompts, with small variations leading to large fluctuations in accuracy. Prior work has mitigated this issue through prompt learning or prompt ensembling. However, these strategies either require annotated data or fail to account for the fact that some prompts may negatively impact performance. In this work, we present an entropy-guided prompt weighting approach that aims to find a robust combination of prompt contributions to maximize prediction confidence. To this end, we formulate a tailored objective function that minimizes prediction entropy to yield new prompt weights, utilizing low-entropy as a proxy for high confidence. Our approach can be applied to individual samples or a batch of audio samples, requiring no additional labels and incurring negligible computational overhead. Experiments on five audio classification datasets covering environmental, urban, and vocal sounds, demonstrate consistent gains compared to classical prompt ensembling methods in a zero-shot setting, with accuracy improvements 5-times larger across the whole benchmark.
RUMPL: Ray-Based Transformers for Universal Multi-View 2D to 3D Human Pose Lifting
Dec 17, 2025Estimating 3D human poses from 2D images remains challenging due to occlusions and projective ambiguity. Multi-view learning-based approaches mitigate these issues but often fail to generalize to real-world scenarios, as large-scale multi-view datasets with 3D ground truth are scarce and captured under constrained conditions. To overcome this limitation, recent methods rely on 2D pose estimation combined with 2D-to-3D pose lifting trained on synthetic data. Building on our previous MPL framework, we propose RUMPL, a transformer-based 3D pose lifter that introduces a 3D ray-based representation of 2D keypoints. This formulation makes the model independent of camera calibration and the number of views, enabling universal deployment across arbitrary multi-view configurations without retraining or fine-tuning. A new View Fusion Transformer leverages learned fused-ray tokens to aggregate information along rays, further improving multi-view consistency. Extensive experiments demonstrate that RUMPL reduces MPJPE by up to 53% compared to triangulation and over 60% compared to transformer-based image-representation baselines. Results on new benchmarks, including in-the-wild multi-view and multi-person datasets, confirm its robustness and scalability. The framework's source code is available at https://github.com/aghasemzadeh/OpenRUMPL
Few-Shot Adaptation Benchmark for Remote Sensing Vision-Language Models
Oct 08, 2025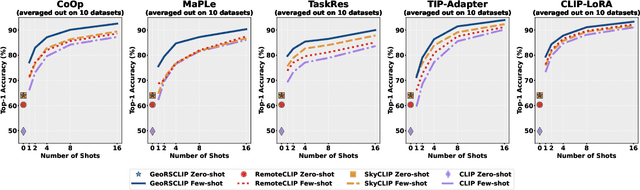



Remote Sensing Vision-Language Models (RSVLMs) have shown remarkable potential thanks to large-scale pretraining, achieving strong zero-shot performance on various tasks. However, their ability to generalize in low-data regimes, such as few-shot learning, remains insufficiently explored. In this work, we present the first structured benchmark for evaluating few-shot adaptation methods on RSVLMs. We conduct comprehensive experiments across ten remote sensing scene classification datasets, applying five widely used few-shot adaptation strategies to three state-of-the-art RSVLMs with varying backbones. Our findings reveal that models with similar zero-shot performance can exhibit markedly different behavior under few-shot adaptation, with some RSVLMs being inherently more amenable to such adaptation than others. The variability of performance and the absence of a clear winner among existing methods highlight the need for the development of more robust methods for few-shot adaptation tailored to RS. To facilitate future research, we provide a reproducible benchmarking framework and open-source code to systematically evaluate RSVLMs under few-shot conditions. The source code is publicly available on Github: https://github.com/elkhouryk/fewshot_RSVLMs
NeRF-based Visualization of 3D Cues Supporting Data-Driven Spacecraft Pose Estimation
Sep 18, 2025On-orbit operations require the estimation of the relative 6D pose, i.e., position and orientation, between a chaser spacecraft and its target. While data-driven spacecraft pose estimation methods have been developed, their adoption in real missions is hampered by the lack of understanding of their decision process. This paper presents a method to visualize the 3D visual cues on which a given pose estimator relies. For this purpose, we train a NeRF-based image generator using the gradients back-propagated through the pose estimation network. This enforces the generator to render the main 3D features exploited by the spacecraft pose estimation network. Experiments demonstrate that our method recovers the relevant 3D cues. Furthermore, they offer additional insights on the relationship between the pose estimation network supervision and its implicit representation of the target spacecraft.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Vocabulary-free few-shot learning for Vision-Language Models
Jun 04, 2025Recent advances in few-shot adaptation for Vision-Language Models (VLMs) have greatly expanded their ability to generalize across tasks using only a few labeled examples. However, existing approaches primarily build upon the strong zero-shot priors of these models by leveraging carefully designed, task-specific prompts. This dependence on predefined class names can restrict their applicability, especially in scenarios where exact class names are unavailable or difficult to specify. To address this limitation, we introduce vocabulary-free few-shot learning for VLMs, a setting where target class instances - that is, images - are available but their corresponding names are not. We propose Similarity Mapping (SiM), a simple yet effective baseline that classifies target instances solely based on similarity scores with a set of generic prompts (textual or visual), eliminating the need for carefully handcrafted prompts. Although conceptually straightforward, SiM demonstrates strong performance, operates with high computational efficiency (learning the mapping typically takes less than one second), and provides interpretability by linking target classes to generic prompts. We believe that our approach could serve as an important baseline for future research in vocabulary-free few-shot learning. Code is available at https://github.com/MaxZanella/vocabulary-free-FSL.
CAMELTrack: Context-Aware Multi-cue ExpLoitation for Online Multi-Object Tracking
May 02, 2025Online multi-object tracking has been recently dominated by tracking-by-detection (TbD) methods, where recent advances rely on increasingly sophisticated heuristics for tracklet representation, feature fusion, and multi-stage matching. The key strength of TbD lies in its modular design, enabling the integration of specialized off-the-shelf models like motion predictors and re-identification. However, the extensive usage of human-crafted rules for temporal associations makes these methods inherently limited in their ability to capture the complex interplay between various tracking cues. In this work, we introduce CAMEL, a novel association module for Context-Aware Multi-Cue ExpLoitation, that learns resilient association strategies directly from data, breaking free from hand-crafted heuristics while maintaining TbD's valuable modularity. At its core, CAMEL employs two transformer-based modules and relies on a novel association-centric training scheme to effectively model the complex interactions between tracked targets and their various association cues. Unlike end-to-end detection-by-tracking approaches, our method remains lightweight and fast to train while being able to leverage external off-the-shelf models. Our proposed online tracking pipeline, CAMELTrack, achieves state-of-the-art performance on multiple tracking benchmarks. Our code is available at https://github.com/TrackingLaboratory/CAMELTrack.