 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI-to-Mid Distilled Compression (M2M-DC): An Hybrid-Information-Guided-Block Pruning with Progressive Inner Slicing Approach to Model Compression
Nov 18, 2025We introduce MI-to-Mid Distilled Compression (M2M-DC), a two-scale, shape-safe compression framework that interleaves information-guided block pruning with progressive inner slicing and staged knowledge distillation (KD). First, M2M-DC ranks residual (or inverted-residual) blocks by a label-aware mutual information (MI) signal and removes the least informative units (structured prune-after-training). It then alternates short KD phases with stage-coherent, residual-safe channel slicing: (i) stage "planes" (co-slicing conv2 out-channels with the downsample path and next-stage inputs), and (ii) an optional mid-channel trim (conv1 out / bn1 / conv2 in). This targets complementary redundancy, whole computational motifs and within-stage width while preserving residual shape invariants. On CIFAR-100, M2M-DC yields a clean accuracy-compute frontier. For ResNet-18, we obtain 85.46% Top-1 with 3.09M parameters and 0.0139 GMacs (72% params, 63% GMacs vs. teacher; mean final 85.29% over three seeds). For ResNet-34, we reach 85.02% Top-1 with 5.46M params and 0.0195 GMacs (74% / 74% vs. teacher; mean final 84.62%). Extending to inverted-residuals, MobileNetV2 achieves a mean final 68.54% Top-1 at 1.71M params (27%) and 0.0186 conv GMacs (24%), improving over the teacher's 66.03% by +2.5 points across three seeds. Because M2M-DC exposes only a thin, architecture-aware interface (blocks, stages, and down sample/skip wiring), it generalizes across residual CNNs and extends to inverted-residual families with minor legalization rules. The result is a compact, practical recipe for deployment-ready models that match or surpass teacher accuracy at a fraction of the compute.
Exploring a Datasets Statistical Effect Size Impact on Model Performance, and Data Sample-Size Sufficiency
Jan 05, 2025Having a sufficient quantity of quality data is a critical enabler of training effective machine learning models. Being able to effectively determine the adequacy of a dataset prior to training and evaluating a model's performance would be an essential tool for anyone engaged in experimental design or data collection. However, despite the need for it, the ability to prospectively assess data sufficiency remains an elusive capability. We report here on two experiments undertaken in an attempt to better ascertain whether or not basic descriptive statistical measures can be indicative of how effective a dataset will be at training a resulting model. Leveraging the effect size of our features, this work first explores whether or not a correlation exists between effect size, and resulting model performance (theorizing that the magnitude of the distinction between classes could correlate to a classifier's resulting success). We then explore whether or not the magnitude of the effect size will impact the rate of convergence of our learning rate, (theorizing again that a greater effect size may indicate that the model will converge more rapidly, and with a smaller sample size needed). Our results appear to indicate that this is not an effective heuristic for determining adequate sample size or projecting model performance, and therefore that additional work is still needed to better prospectively assess adequacy of data.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
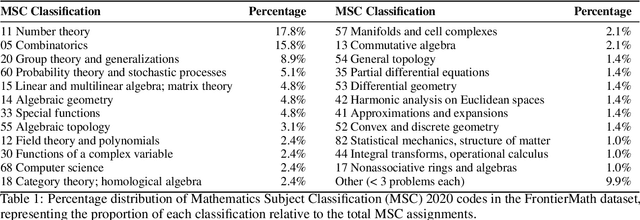
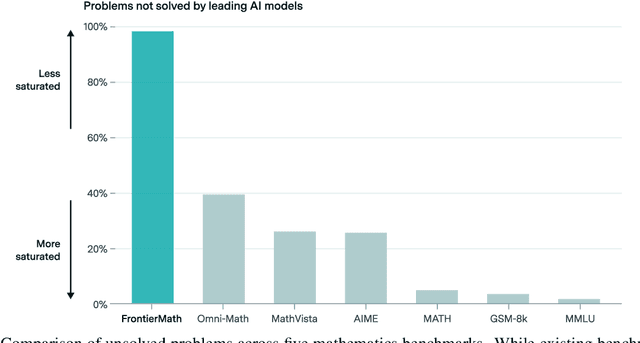
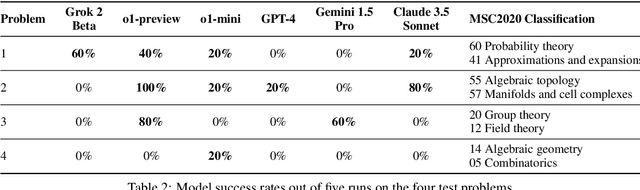
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Exploring Cross-model Neuronal Correlations in the Context of Predicting Model Performance and Generalizability
Aug 15, 2024
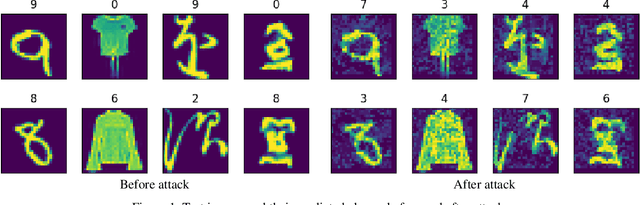
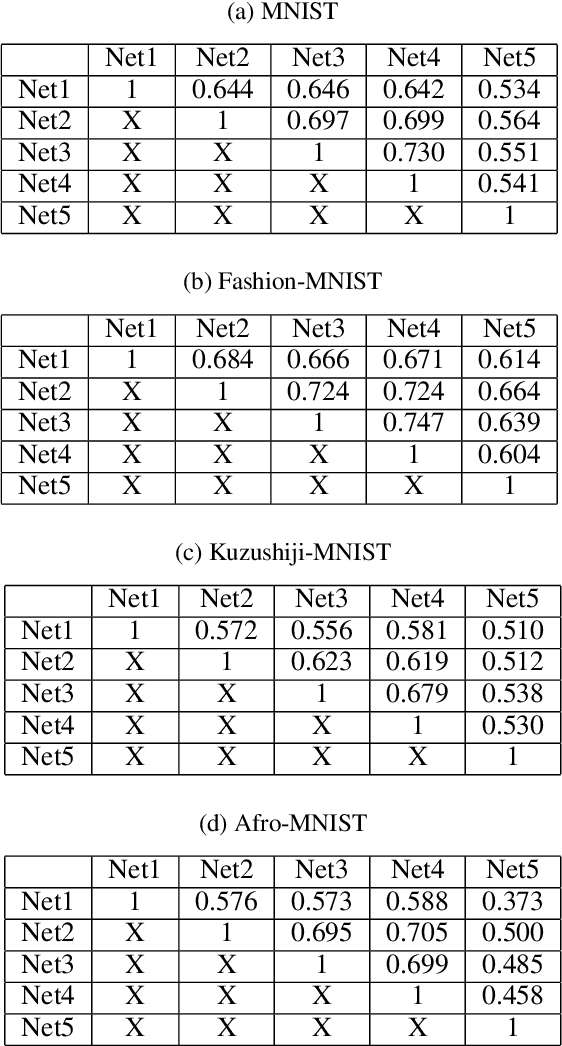
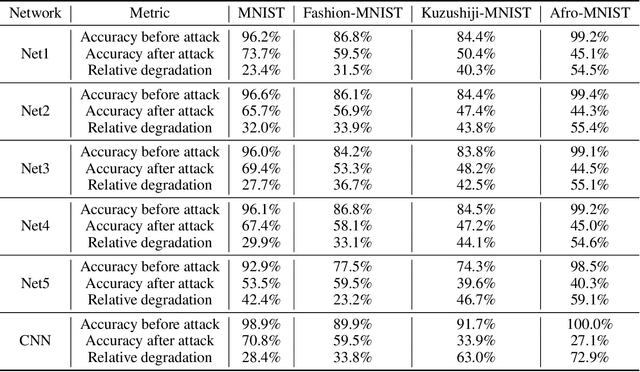
As Artificial Intelligence (AI) models are increasingly integrated into critical systems, the need for a robust framework to establish the trustworthiness of AI is increasingly paramount. While collaborative efforts have established conceptual foundations for such a framework, there remains a significant gap in developing concrete, technically robust methods for assessing AI model quality and performance. A critical drawback in the traditional methods for assessing the validity and generalizability of models is their dependence on internal developer datasets, rendering it challenging to independently assess and verify their performance claims. This paper introduces a novel approach for assessing a newly trained model's performance based on another known model by calculating correlation between neural networks. The proposed method evaluates correlations by determining if, for each neuron in one network, there exists a neuron in the other network that produces similar output. This approach has implications for memory efficiency, allowing for the use of smaller networks when high correlation exists between networks of different sizes. Additionally, the method provides insights into robustness, suggesting that if two highly correlated networks are compared and one demonstrates robustness when operating in production environments, the other is likely to exhibit similar robustness. This contribution advances the technical toolkit for responsible AI, supporting more comprehensive and nuanced evaluations of AI models to ensure their safe and effective deployment.
Do language models plan ahead for future tokens?
Apr 01, 2024



Do transformers "think ahead" during inference at a given position? It is known transformers prepare information in the hidden states of the forward pass at $t$ that is then used in future forward passes $t+\tau$. We posit two explanations for this phenomenon: pre-caching, in which off-diagonal gradient terms present in training result in the model computing features at $t$ irrelevant to the present inference task but useful for the future, and breadcrumbs, in which features most relevant to time step $t$ are already the same as those that would most benefit inference at time $t+\tau$. We test these hypotheses by training language models without propagating gradients to past timesteps, a scheme we formalize as myopic training. In a synthetic data setting, we find clear evidence for pre-caching. In the autoregressive language modeling setting, our experiments are more suggestive of the breadcrumbs hypothesis.
A Self-supervised Framework for Improved Data-Driven Monitoring of Stress via Multi-modal Passive Sensing
Mar 24, 2023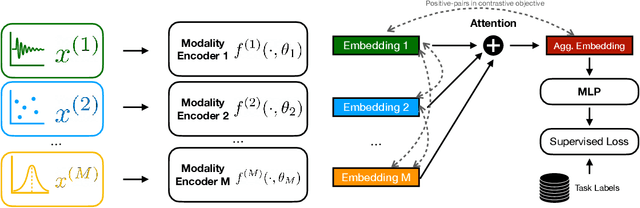
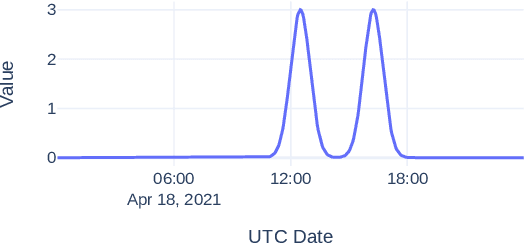

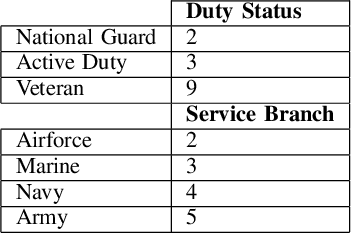
Recent advances in remote health monitoring systems have significantly benefited patients and played a crucial role in improving their quality of life. However, while physiological health-focused solutions have demonstrated increasing success and maturity, mental health-focused applications have seen comparatively limited success in spite of the fact that stress and anxiety disorders are among the most common issues people deal with in their daily lives. In the hopes of furthering progress in this domain through the development of a more robust analytic framework for the measurement of indicators of mental health, we propose a multi-modal semi-supervised framework for tracking physiological precursors of the stress response. Our methodology enables utilizing multi-modal data of differing domains and resolutions from wearable devices and leveraging them to map short-term episodes to semantically efficient embeddings for a given task. Additionally, we leverage an inter-modality contrastive objective, with the advantages of rendering our framework both modular and scalable. The focus on optimizing both local and global aspects of our embeddings via a hierarchical structure renders transferring knowledge and compatibility with other devices easier to achieve. In our pipeline, a task-specific pooling based on an attention mechanism, which estimates the contribution of each modality on an instance level, computes the final embeddings for observations. This additionally provides a thorough diagnostic insight into the data characteristics and highlights the importance of signals in the broader view of predicting episodes annotated per mental health status. We perform training experiments using a corpus of real-world data on perceived stress, and our results demonstrate the efficacy of the proposed approach in performance improvements.