 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Continual Learning of Local Language Models and Cloud Offloading Decisions with Budget Constraints
Jan 29, 2026Locally deployed Small Language Models (SLMs) must continually support diverse tasks under strict memory and computation constraints, making selective reliance on cloud Large Language Models (LLMs) unavoidable. Regulating cloud assistance during continual learning is challenging, as naive reward-based reinforcement learning often yields unstable offloading behavior and exacerbates catastrophic forgetting as task distributions shift. We propose DA-GRPO, a dual-advantage extension of Group Relative Policy Optimization that incorporates cloud-usage constraints directly into advantage computation, avoiding fixed reward shaping and external routing models. This design enables the local model to jointly learn task competence and collaboration behavior, allowing cloud requests to emerge naturally during post-training while respecting a prescribed assistance budget. Experiments on mathematical reasoning and code generation benchmarks show that DA-GRPO improves post-switch accuracy, substantially reduces forgetting, and maintains stable cloud usage compared to prior collaborative and routing-based approaches.
From Structured Prompts to Open Narratives: Measuring Gender Bias in LLMs Through Open-Ended Storytelling
Mar 20, 2025



Large Language Models (LLMs) have revolutionized natural language processing, yet concerns persist regarding their tendency to reflect or amplify social biases present in their training data. This study introduces a novel evaluation framework to uncover gender biases in LLMs, focusing on their occupational narratives. Unlike previous methods relying on structured scenarios or carefully crafted prompts, our approach leverages free-form storytelling to reveal biases embedded in the models. Systematic analyses show an overrepresentation of female characters across occupations in six widely used LLMs. Additionally, our findings reveal that LLM-generated occupational gender rankings align more closely with human stereotypes than actual labor statistics. These insights underscore the need for balanced mitigation strategies to ensure fairness while avoiding the reinforcement of new stereotypes.
DPZV: Resource Efficient ZO Optimization For Differentially Private VFL
Feb 27, 2025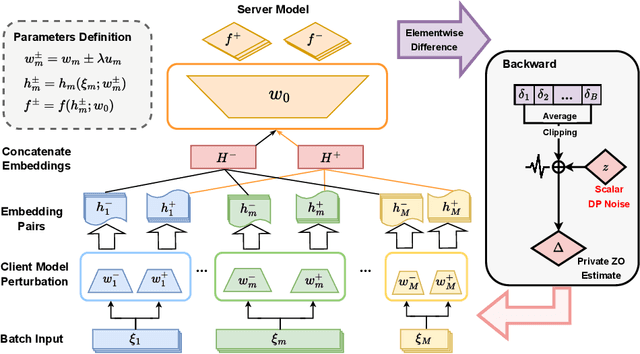

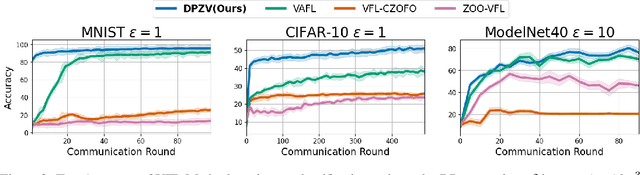
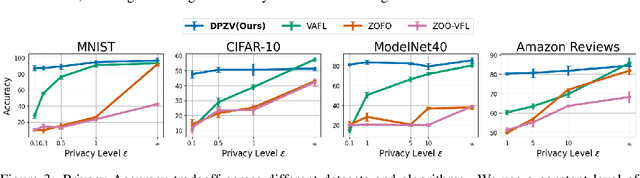
Vertical Federated Learning (VFL) enables collaborative model training across feature-partitioned data, yet faces significant privacy risks and inefficiencies when scaling to large models. We propose DPZV, a memory-efficient Zeroth-Order(ZO) optimization framework that integrates differential privacy (DP) with vertical federated learning, addressing three critical challenges: (1) privacy vulnerabilities from gradient leakage, (2) high computation/communication costs of first-order methods, and (3) excessive memory footprint in conventional zeroth-order approaches. Our framework eliminates backpropagation through two-point gradient estimation, reducing client memory usage by 90\% compared to first-order counterparts while enabling asynchronous communication. By strategically injecting Gaussian noise on the server, DPZV achieves rigorous $(\epsilon, \delta)$-DP guarantees without third-party trust assumptions. Theoretical analysis establishes a convergence rate matching centralized case under non-convex objectives. Extensive experiments on image and NLP benchmarks demonstrate that DPZV outperforms all baselines in accuracy while providing strong privacy assurances ($\epsilon \leq 10$) and requiring far fewer computation resources, establishing new state-of-the-art privacy-utility tradeoffs for resource-constrained VFL deployments.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
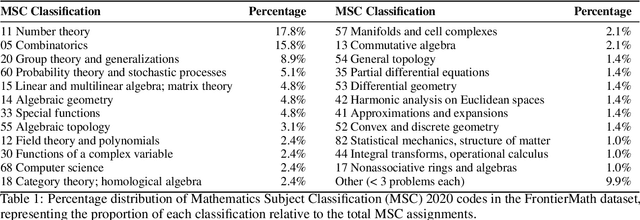
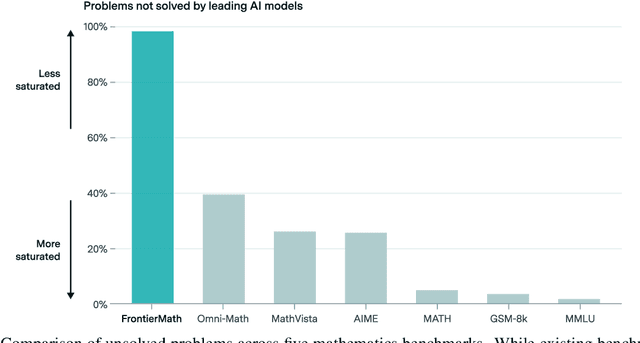
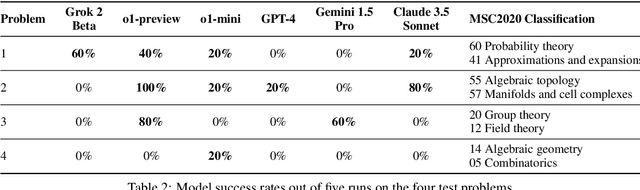
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Hierarchical Federated Learning with Multi-Timescale Gradient Correction
Sep 27, 2024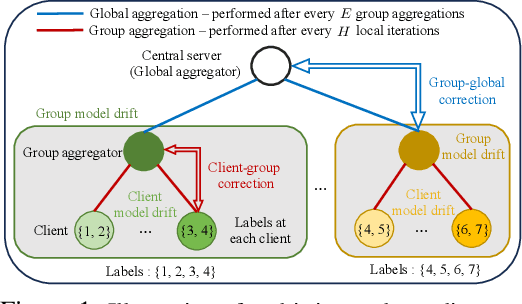
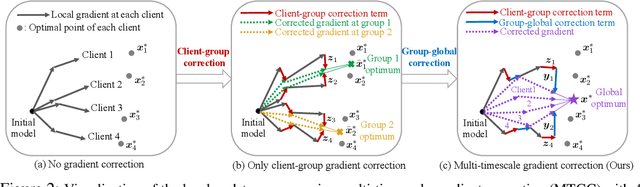
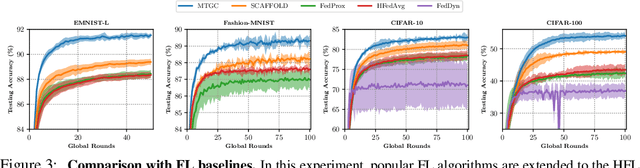
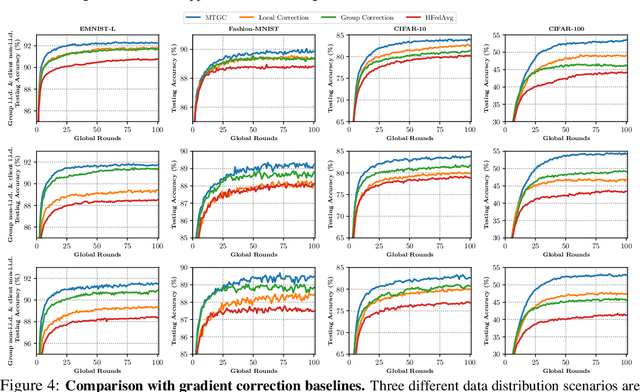
While traditional federated learning (FL) typically focuses on a star topology where clients are directly connected to a central server, real-world distributed systems often exhibit hierarchical architectures. Hierarchical FL (HFL) has emerged as a promising solution to bridge this gap, leveraging aggregation points at multiple levels of the system. However, existing algorithms for HFL encounter challenges in dealing with multi-timescale model drift, i.e., model drift occurring across hierarchical levels of data heterogeneity. In this paper, we propose a multi-timescale gradient correction (MTGC) methodology to resolve this issue. Our key idea is to introduce distinct control variables to (i) correct the client gradient towards the group gradient, i.e., to reduce client model drift caused by local updates based on individual datasets, and (ii) correct the group gradient towards the global gradient, i.e., to reduce group model drift caused by FL over clients within the group. We analytically characterize the convergence behavior of MTGC under general non-convex settings, overcoming challenges associated with couplings between correction terms. We show that our convergence bound is immune to the extent of data heterogeneity, confirming the stability of the proposed algorithm against multi-level non-i.i.d. data. Through extensive experiments on various datasets and models, we validate the effectiveness of MTGC in diverse HFL settings. The code for this project is available at \href{https://github.com/wenzhifang/MTGC}{https://github.com/wenzhifang/MTGC}.
Cross-Resolution Flow Propagation for Foveated Video Super-Resolution
Dec 27, 2022The demand of high-resolution video contents has grown over the years. However, the delivery of high-resolution video is constrained by either computational resources required for rendering or network bandwidth for remote transmission. To remedy this limitation, we leverage the eye trackers found alongside existing augmented and virtual reality headsets. We propose the application of video super-resolution (VSR) technique to fuse low-resolution context with regional high-resolution context for resource-constrained consumption of high-resolution content without perceivable drop in quality. Eye trackers provide us the gaze direction of a user, aiding us in the extraction of the regional high-resolution context. As only pixels that falls within the gaze region can be resolved by the human eye, a large amount of the delivered content is redundant as we can't perceive the difference in quality of the region beyond the observed region. To generate a visually pleasing frame from the fusion of high-resolution region and low-resolution region, we study the capability of a deep neural network of transferring the context of the observed region to other regions (low-resolution) of the current and future frames. We label this task a Foveated Video Super-Resolution (FVSR), as we need to super-resolve the low-resolution regions of current and future frames through the fusion of pixels from the gaze region. We propose Cross-Resolution Flow Propagation (CRFP) for FVSR. We train and evaluate CRFP on REDS dataset on the task of 8x FVSR, i.e. a combination of 8x VSR and the fusion of foveated region. Departing from the conventional evaluation of per frame quality using SSIM or PSNR, we propose the evaluation of past foveated region, measuring the capability of a model to leverage the noise present in eye trackers during FVSR. Code is made available at https://github.com/eugenelet/CRFP.
Meta-rPPG: Remote Heart Rate Estimation Using a Transductive Meta-Learner
Jul 14, 2020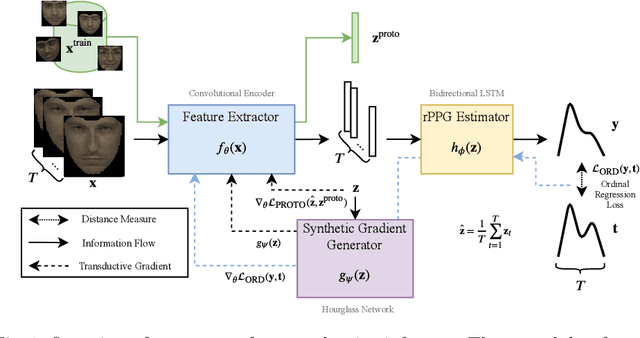
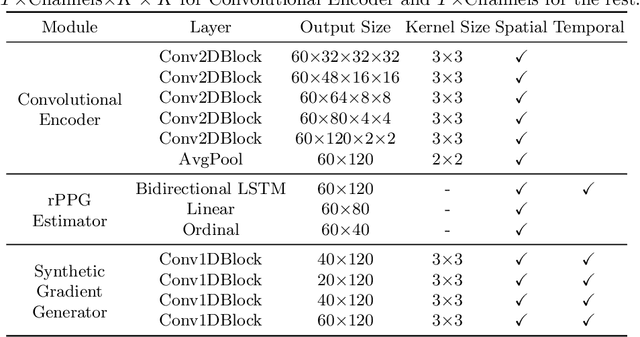
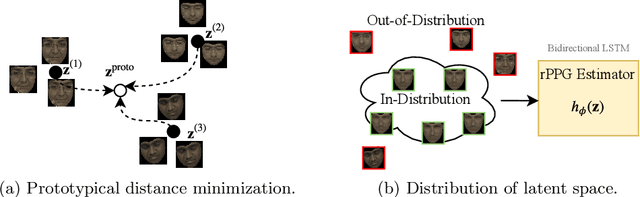
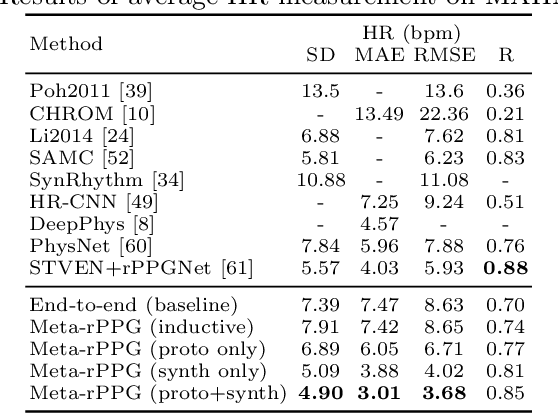
Remote heart rate estimation is the measurement of heart rate without any physical contact with the subject and is accomplished using remote photoplethysmography (rPPG) in this work. rPPG signals are usually collected using a video camera with a limitation of being sensitive to multiple contributing factors, e.g. variation in skin tone, lighting condition and facial structure. End-to-end supervised learning approach performs well when training data is abundant, covering a distribution that doesn't deviate too much from the distribution of testing data or during deployment. To cope with the unforeseeable distributional changes during deployment, we propose a transductive meta-learner that takes unlabeled samples during testing (deployment) for a self-supervised weight adjustment (also known as transductive inference), providing fast adaptation to the distributional changes. Using this approach, we achieve state-of-the-art performance on MAHNOB-HCI and UBFC-rPPG.