 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Resolution Flow Propagation for Foveated Video Super-Resolution
Dec 27, 2022The demand of high-resolution video contents has grown over the years. However, the delivery of high-resolution video is constrained by either computational resources required for rendering or network bandwidth for remote transmission. To remedy this limitation, we leverage the eye trackers found alongside existing augmented and virtual reality headsets. We propose the application of video super-resolution (VSR) technique to fuse low-resolution context with regional high-resolution context for resource-constrained consumption of high-resolution content without perceivable drop in quality. Eye trackers provide us the gaze direction of a user, aiding us in the extraction of the regional high-resolution context. As only pixels that falls within the gaze region can be resolved by the human eye, a large amount of the delivered content is redundant as we can't perceive the difference in quality of the region beyond the observed region. To generate a visually pleasing frame from the fusion of high-resolution region and low-resolution region, we study the capability of a deep neural network of transferring the context of the observed region to other regions (low-resolution) of the current and future frames. We label this task a Foveated Video Super-Resolution (FVSR), as we need to super-resolve the low-resolution regions of current and future frames through the fusion of pixels from the gaze region. We propose Cross-Resolution Flow Propagation (CRFP) for FVSR. We train and evaluate CRFP on REDS dataset on the task of 8x FVSR, i.e. a combination of 8x VSR and the fusion of foveated region. Departing from the conventional evaluation of per frame quality using SSIM or PSNR, we propose the evaluation of past foveated region, measuring the capability of a model to leverage the noise present in eye trackers during FVSR. Code is made available at https://github.com/eugenelet/CRFP.
Few-Shot and Continual Learning with Attentive Independent Mechanisms
Jul 29, 2021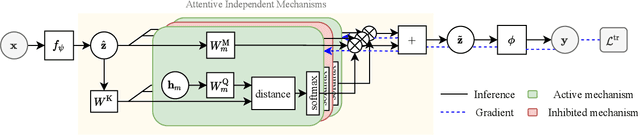
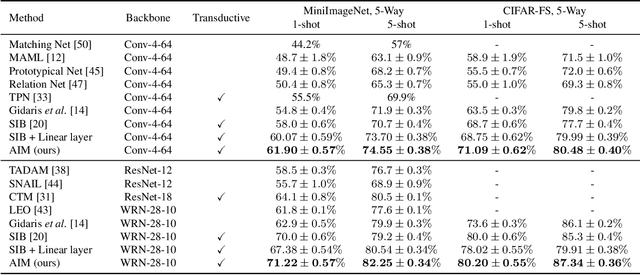
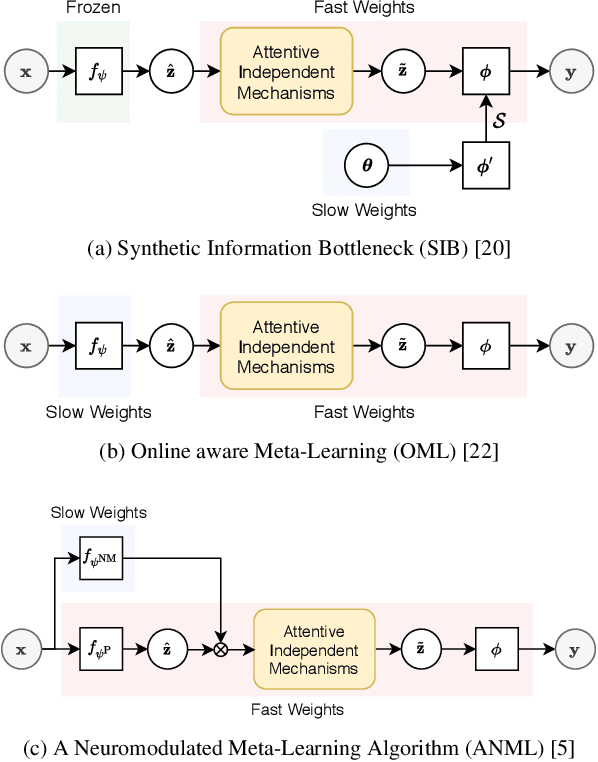

Deep neural networks (DNNs) are known to perform well when deployed to test distributions that shares high similarity with the training distribution. Feeding DNNs with new data sequentially that were unseen in the training distribution has two major challenges -- fast adaptation to new tasks and catastrophic forgetting of old tasks. Such difficulties paved way for the on-going research on few-shot learning and continual learning. To tackle these problems, we introduce Attentive Independent Mechanisms (AIM). We incorporate the idea of learning using fast and slow weights in conjunction with the decoupling of the feature extraction and higher-order conceptual learning of a DNN. AIM is designed for higher-order conceptual learning, modeled by a mixture of experts that compete to learn independent concepts to solve a new task. AIM is a modular component that can be inserted into existing deep learning frameworks. We demonstrate its capability for few-shot learning by adding it to SIB and trained on MiniImageNet and CIFAR-FS, showing significant improvement. AIM is also applied to ANML and OML trained on Omniglot, CIFAR-100 and MiniImageNet to demonstrate its capability in continual learning. Code made publicly available at https://github.com/huang50213/AIM-Fewshot-Continual.
Meta-rPPG: Remote Heart Rate Estimation Using a Transductive Meta-Learner
Jul 14, 2020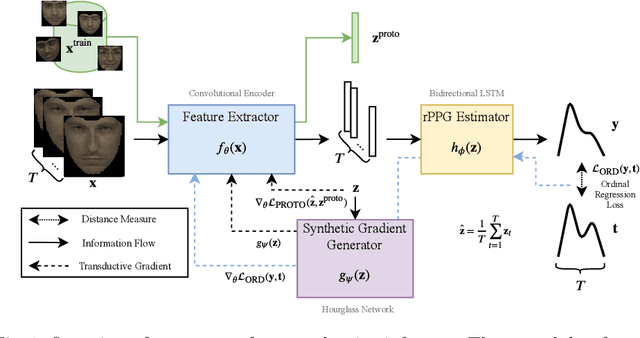
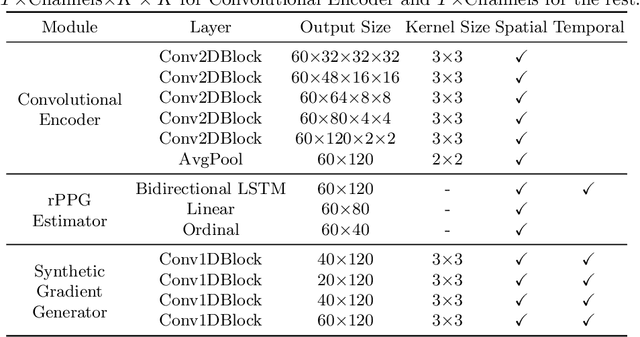
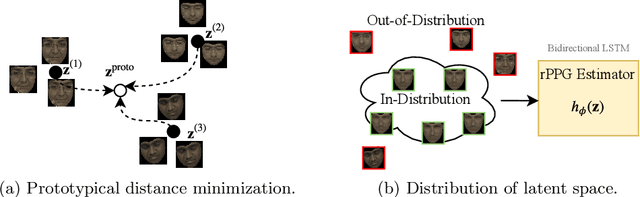
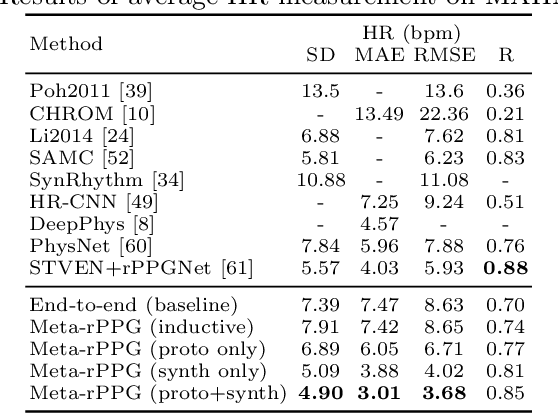
Remote heart rate estimation is the measurement of heart rate without any physical contact with the subject and is accomplished using remote photoplethysmography (rPPG) in this work. rPPG signals are usually collected using a video camera with a limitation of being sensitive to multiple contributing factors, e.g. variation in skin tone, lighting condition and facial structure. End-to-end supervised learning approach performs well when training data is abundant, covering a distribution that doesn't deviate too much from the distribution of testing data or during deployment. To cope with the unforeseeable distributional changes during deployment, we propose a transductive meta-learner that takes unlabeled samples during testing (deployment) for a self-supervised weight adjustment (also known as transductive inference), providing fast adaptation to the distributional changes. Using this approach, we achieve state-of-the-art performance on MAHNOB-HCI and UBFC-rPPG.
NeuralScale: Efficient Scaling of Neurons for Resource-Constrained Deep Neural Networks
Jun 23, 2020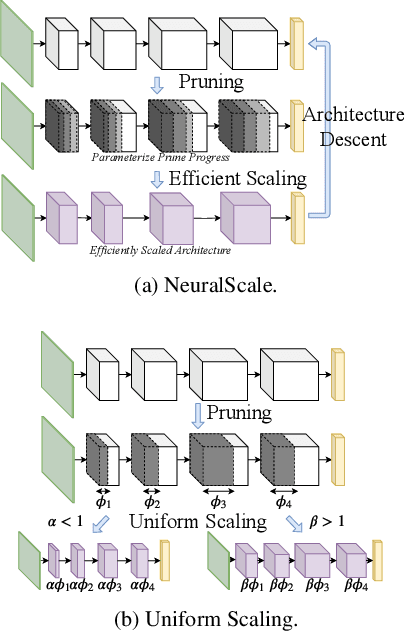
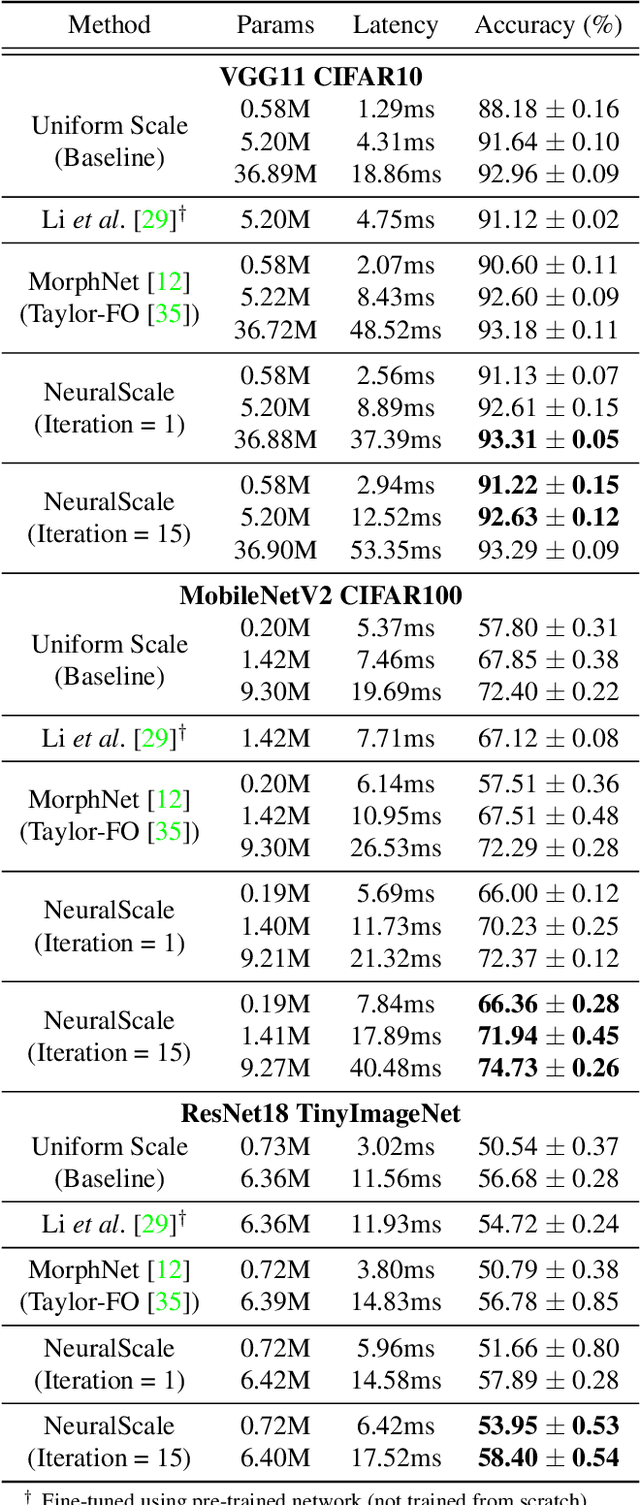
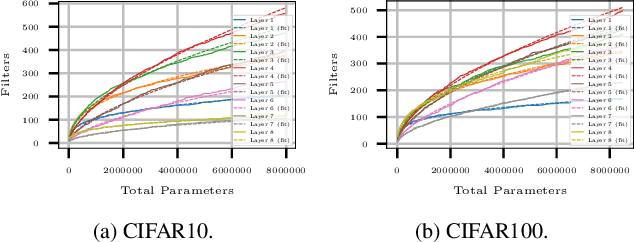
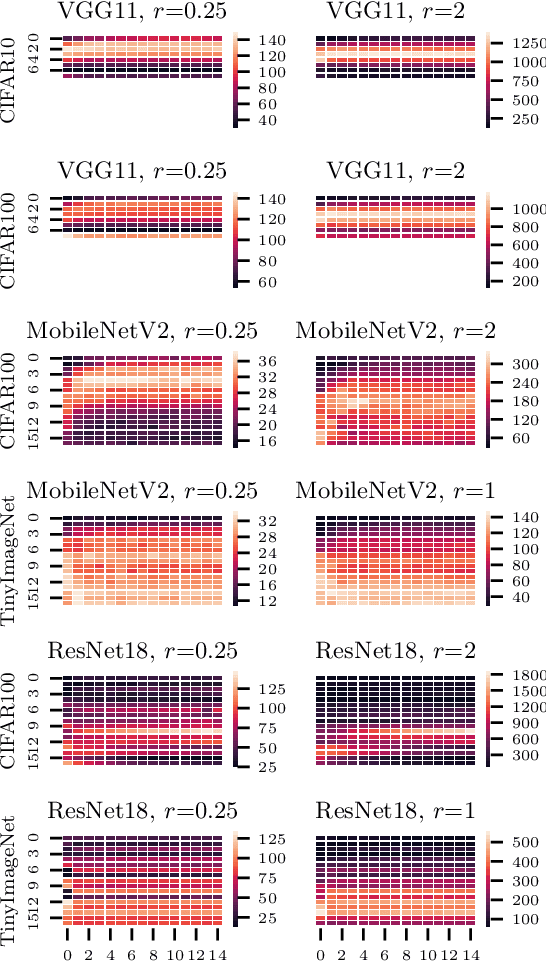
Deciding the amount of neurons during the design of a deep neural network to maximize performance is not intuitive. In this work, we attempt to search for the neuron (filter) configuration of a fixed network architecture that maximizes accuracy. Using iterative pruning methods as a proxy, we parameterize the change of the neuron (filter) number of each layer with respect to the change in parameters, allowing us to efficiently scale an architecture across arbitrary sizes. We also introduce architecture descent which iteratively refines the parameterized function used for model scaling. The combination of both proposed methods is coined as NeuralScale. To prove the efficiency of NeuralScale in terms of parameters, we show empirical simulations on VGG11, MobileNetV2 and ResNet18 using CIFAR10, CIFAR100 and TinyImageNet as benchmark datasets. Our results show an increase in accuracy of 3.04%, 8.56% and 3.41% for VGG11, MobileNetV2 and ResNet18 on CIFAR10, CIFAR100 and TinyImageNet respectively under a parameter-constrained setting (output neurons (filters) of default configuration with scaling factor of 0.25).
* 17 pages, 11 figures, accepted by CVPR as oral paper