 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralScale: Efficient Scaling of Neurons for Resource-Constrained Deep Neural Networks
Paper and Code
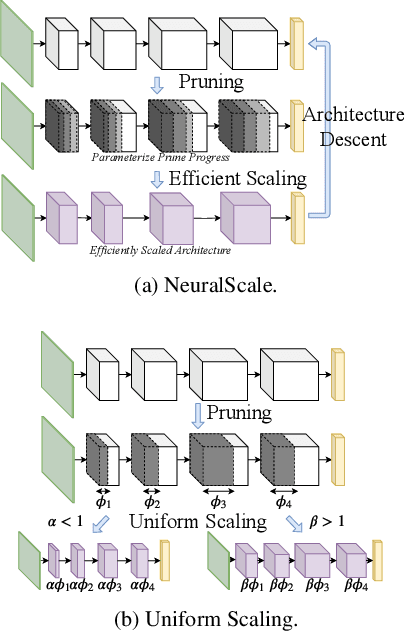
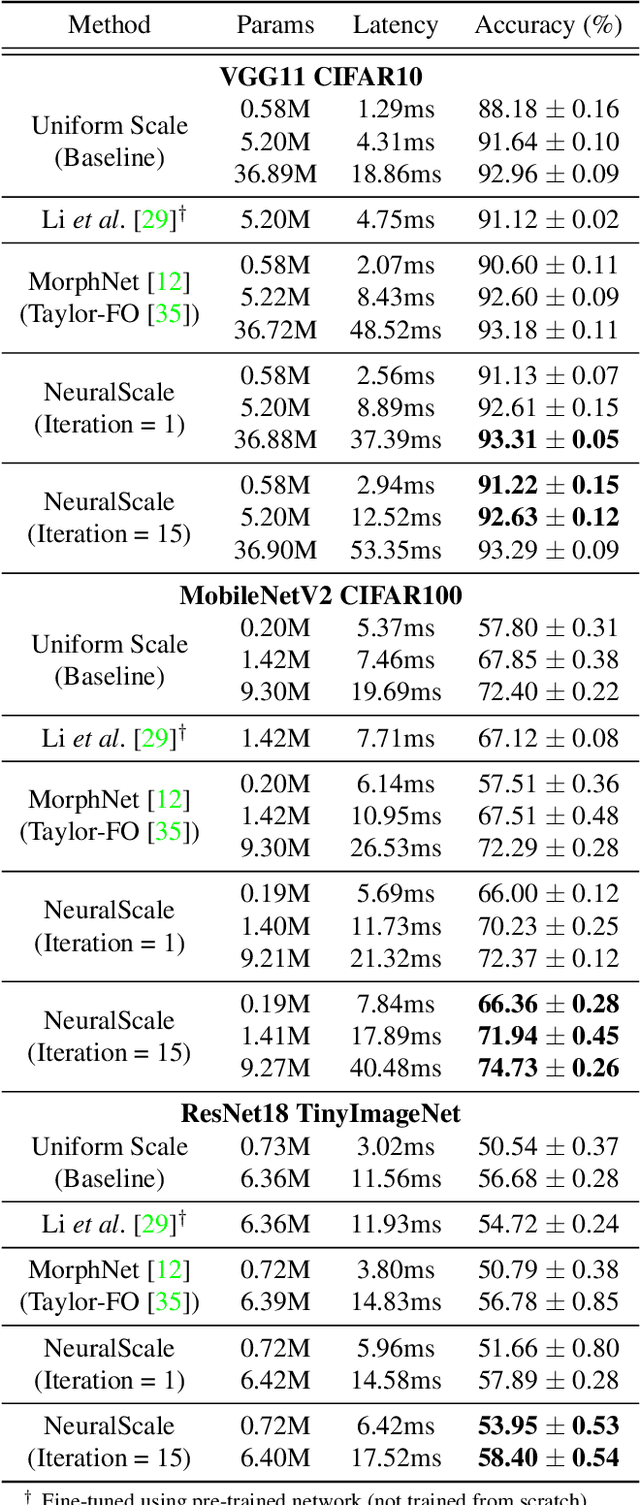
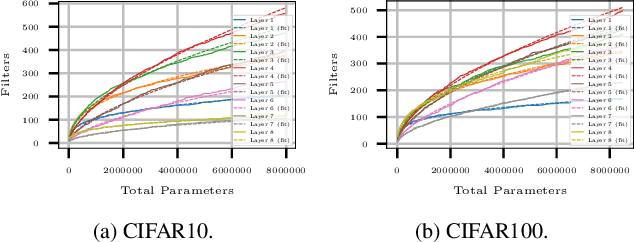
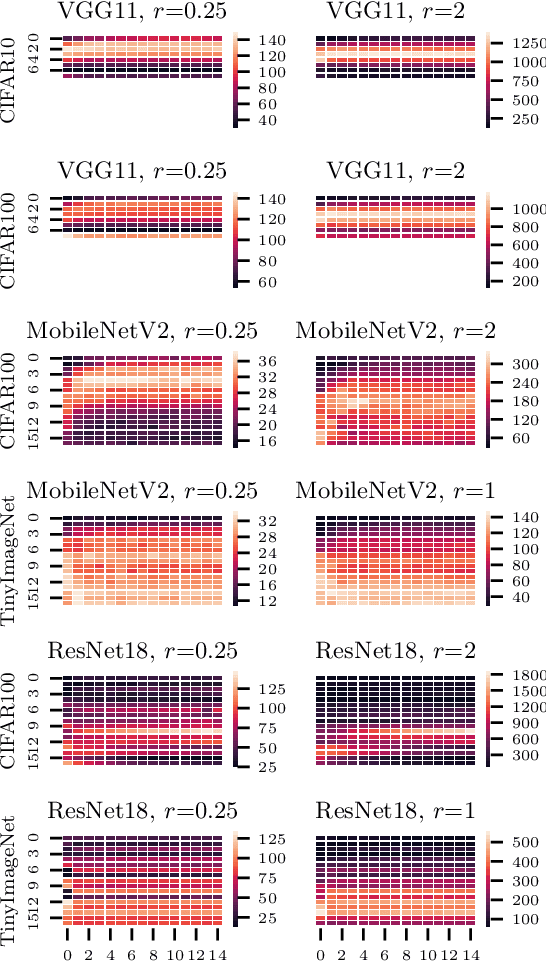
Deciding the amount of neurons during the design of a deep neural network to maximize performance is not intuitive. In this work, we attempt to search for the neuron (filter) configuration of a fixed network architecture that maximizes accuracy. Using iterative pruning methods as a proxy, we parameterize the change of the neuron (filter) number of each layer with respect to the change in parameters, allowing us to efficiently scale an architecture across arbitrary sizes. We also introduce architecture descent which iteratively refines the parameterized function used for model scaling. The combination of both proposed methods is coined as NeuralScale. To prove the efficiency of NeuralScale in terms of parameters, we show empirical simulations on VGG11, MobileNetV2 and ResNet18 using CIFAR10, CIFAR100 and TinyImageNet as benchmark datasets. Our results show an increase in accuracy of 3.04%, 8.56% and 3.41% for VGG11, MobileNetV2 and ResNet18 on CIFAR10, CIFAR100 and TinyImageNet respectively under a parameter-constrained setting (output neurons (filters) of default configuration with scaling factor of 0.25).