 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Volumes to Slices: Computationally Efficient Contrastive Learning for Sequential Abdominal CT Analysis
Jan 21, 2026The requirement for expert annotations limits the effectiveness of deep learning for medical image analysis. Although 3D self-supervised methods like volume contrast learning (VoCo) are powerful and partially address the labeling scarcity issue, their high computational cost and memory consumption are barriers. We propose 2D-VoCo, an efficient adaptation of the VoCo framework for slice-level self-supervised pre-training that learns spatial-semantic features from unlabeled 2D CT slices via contrastive learning. The pre-trained CNN backbone is then integrated into a CNN-LSTM architecture to classify multi-organ injuries. In the RSNA 2023 Abdominal Trauma dataset, 2D-VoCo pre-training significantly improves mAP, precision, recall, and RSNA score over training from scratch. Our framework provides a practical method to reduce the dependency on labeled data and enhance model performance in clinical CT analysis. We release the code for reproducibility. https://github.com/tkz05/2D-VoCo-CT-Classifier
GraphFusionSBR: Denoising Multi-Channel Graphs for Session-Based Recommendation
Jan 13, 2026Session-based recommendation systems must capture implicit user intents from sessions. However, existing models suffer from issues such as item interaction dominance and noisy sessions. We propose a multi-channel recommendation model, including a knowledge graph channel, a session hypergraph channel, and a session line graph channel, to capture information from multiple sources. Our model adaptively removes redundant edges in the knowledge graph channel to reduce noise. Knowledge graph representations cooperate with hypergraph representations for prediction to alleviate item dominance. We also generate in-session attention for denoising. Finally, we maximize mutual information between the hypergraph and line graph channels as an auxiliary task. Experiments demonstrate that our method enhances the accuracy of various recommendations, including e-commerce and multimedia recommendations. We release the code on GitHub for reproducibility.\footnote{https://github.com/hohehohe0509/DSR-HK}
From Structured Prompts to Open Narratives: Measuring Gender Bias in LLMs Through Open-Ended Storytelling
Mar 20, 2025



Large Language Models (LLMs) have revolutionized natural language processing, yet concerns persist regarding their tendency to reflect or amplify social biases present in their training data. This study introduces a novel evaluation framework to uncover gender biases in LLMs, focusing on their occupational narratives. Unlike previous methods relying on structured scenarios or carefully crafted prompts, our approach leverages free-form storytelling to reveal biases embedded in the models. Systematic analyses show an overrepresentation of female characters across occupations in six widely used LLMs. Additionally, our findings reveal that LLM-generated occupational gender rankings align more closely with human stereotypes than actual labor statistics. These insights underscore the need for balanced mitigation strategies to ensure fairness while avoiding the reinforcement of new stereotypes.
Dynamic DropConnect: Enhancing Neural Network Robustness through Adaptive Edge Dropping Strategies
Feb 27, 2025Dropout and DropConnect are well-known techniques that apply a consistent drop rate to randomly deactivate neurons or edges in a neural network layer during training. This paper introduces a novel methodology that assigns dynamic drop rates to each edge within a layer, uniquely tailoring the dropping process without incorporating additional learning parameters. We perform experiments on synthetic and openly available datasets to validate the effectiveness of our approach. The results demonstrate that our method outperforms Dropout, DropConnect, and Standout, a classic mechanism known for its adaptive dropout capabilities. Furthermore, our approach improves the robustness and generalization of neural network training without increasing computational complexity. The complete implementation of our methodology is publicly accessible for research and replication purposes at https://github.com/ericabd888/Adjusting-the-drop-probability-in-DropConnect-based-on-the-magnitude-of-the-gradient/.
Flexible Bivariate Beta Mixture Model: A Probabilistic Approach for Clustering Complex Data Structures
Feb 27, 2025


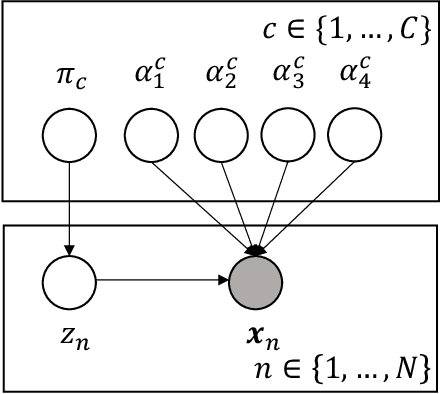
Clustering is essential in data analysis and machine learning, but traditional algorithms like $k$-means and Gaussian Mixture Models (GMM) often fail with nonconvex clusters. To address the challenge, we introduce the Flexible Bivariate Beta Mixture Model (FBBMM), which utilizes the flexibility of the bivariate beta distribution to handle diverse and irregular cluster shapes. Using the Expectation Maximization (EM) algorithm and Sequential Least Squares Programming (SLSQP) optimizer for parameter estimation, we validate FBBMM on synthetic and real-world datasets, demonstrating its superior performance in clustering complex data structures, offering a robust solution for big data analytics across various domains. We release the experimental code at https://github.com/yung-peng/MBMM-and-FBBMM.
Understanding Gradient Boosting Classifier: Training, Prediction, and the Role of $γ_j$
Oct 08, 2024The Gradient Boosting Classifier (GBC) is a widely used machine learning algorithm for binary classification, which builds decision trees iteratively to minimize prediction errors. This document explains the GBC's training and prediction processes, focusing on the computation of terminal node values $\gamma_j$, which are crucial to optimizing the logistic loss function. We derive $\gamma_j$ through a Taylor series approximation and provide a step-by-step pseudocode for the algorithm's implementation. The guide explains the theory of GBC and its practical application, demonstrating its effectiveness in binary classification tasks. We provide a step-by-step example in the appendix to help readers understand.
The Effectiveness of Graph Contrastive Learning on Mathematical Information Retrieval
Feb 21, 2024This paper details an empirical investigation into using Graph Contrastive Learning (GCL) to generate mathematical equation representations, a critical aspect of Mathematical Information Retrieval (MIR). Our findings reveal that this simple approach consistently exceeds the performance of the current leading formula retrieval model, TangentCFT. To support ongoing research and development in this field, we have made our source code accessible to the public at https://github.com/WangPeiSyuan/GCL-Formula-Retrieval/.
Multivariate Beta Mixture Model: Probabilistic Clustering With Flexible Cluster Shapes
Jan 30, 2024This paper introduces the multivariate beta mixture model (MBMM), a new probabilistic model for soft clustering. MBMM adapts to diverse cluster shapes because of the flexible probability density function of the multivariate beta distribution. We introduce the properties of MBMM, describe the parameter learning procedure, and present the experimental results, showing that MBMM fits diverse cluster shapes on synthetic and real datasets. The code is released anonymously at \url{https://github.com/hhchen1105/mbmm/}.
Toward Efficient and Incremental Spectral Clustering via Parametric Spectral Clustering
Nov 14, 2023Spectral clustering is a popular method for effectively clustering nonlinearly separable data. However, computational limitations, memory requirements, and the inability to perform incremental learning challenge its widespread application. To overcome these limitations, this paper introduces a novel approach called parametric spectral clustering (PSC). By extending the capabilities of spectral clustering, PSC addresses the challenges associated with big data and real-time scenarios and enables efficient incremental clustering with new data points. Experimental evaluations conducted on various open datasets demonstrate the superiority of PSC in terms of computational efficiency while achieving clustering quality mostly comparable to standard spectral clustering. The proposed approach has significant potential for incremental and real-time data analysis applications, facilitating timely and accurate clustering in dynamic and evolving datasets. The findings of this research contribute to the advancement of clustering techniques and open new avenues for efficient and effective data analysis. We publish the experimental code at https://github.com/109502518/PSC_BigData.
Detecting Inactive Cyberwarriors from Online Forums
Aug 28, 2023The proliferation of misinformation has emerged as a new form of warfare in the information age. This type of warfare involves cyberwarriors, who deliberately propagate messages aimed at defaming opponents or fostering unity among allies. In this study, we investigate the level of activity exhibited by cyberwarriors within a large online forum, and remarkably, we discover that only a minute fraction of cyberwarriors are active users. Surprisingly, despite their expected role of actively disseminating misinformation, cyberwarriors remain predominantly silent during peacetime and only spring into action when necessary. Moreover, we analyze the challenges associated with identifying cyberwarriors and provide evidence that detecting inactive cyberwarriors is considerably more challenging than identifying their active counterparts. Finally, we discuss potential methodologies to more effectively identify cyberwarriors during their inactive phases, offering insights into better capturing their presence and actions. The experimental code is released for reproducibility: \url{https://github.com/Ryaninthegame/Detect-Inactive-Spammers-on-PTT}.