 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Model Already Knows: Attention-Guided Safety Filter for Vision-Language-Action Models
Jun 08, 2026Vision-Language-Action (VLA) models have demonstrated impressive end-to-end performance across a variety of robotic manipulation tasks. However, these policies offer no guarantees against collisions with task-irrelevant objects in the scene. Existing safety filters sidestep this problem by querying a vision-language model (VLM) to identify obstacles and their locations. This, however, is too slow to run in the control loop and can only be invoked at episode initialization, leaving the filter unable to track moving obstacles. We discover that a small number of attention heads within a VLA model reliably localize the object the policy intends to approach. These heads can be exploited within a training-free safety framework that obtains the active target from the attention heads at every step, treats the remainder of the scene as obstacles, and feeds these into a Control Barrier Function (CBF) filter. Together with a lightweight real-time object tracker, this allows for collision avoidance for non-static obstacles. We evaluate our framework on SafeLIBERO, which we extend with moving obstacles. On the original static benchmark, our method performs comparably to an oracle that uses privileged simulator state to identify the target, emulating a VLM-based identification step run once at episode initialization. On the dynamic variant, where the oracle's init-time target assignment becomes stale, our method substantially outperforms it by 43%, on average. Our findings suggest that the perceptual signals needed for real-time safety filtering are already present within VLA policies and can be exploited without additional training or heavy auxiliary models.
ProbeAct: Probe-Guided Training-Free Failure Recovery in Vision-Language-Action Models
Jun 08, 2026Vision-Language-Action (VLA) models demonstrate strong perfor-1 mance on language-conditioned robotic manipulation within their training dis-2 tribution, yet their generalization capabilities remain fundamentally limited. They3 lack the robustness required to handle perturbations, frequently failing when con-4 fronted with lighting changes, altered camera viewpoints, or small initial-state5 variations. We propose PROBEACT, a training-free runtime intervention frame-6 work that detects and recovers from grasping and placement failures in pre-7 trained VLA policies without modifying their weights or requiring additional8 demonstrations. PROBEACT combines three components: (i) a lightweight multi-9 target hidden-state probe that predicts the 3D positions of task-relevant objects10 from intermediate VLA features, with Hungarian-matched identity tracking for11 multi-object scenes; (ii) an object-agnostic kinematic state machine that detects12 grasp, transport, and placement failures using only gripper-internal signals and13 end-effector kinematics; and (iii) a hierarchical Control Barrier Function (CBF)14 filter that encodes repeated-failure locations as soft safe-set constraints, mini-15 mally correcting VLA actions while preserving baseline behavior. As a plug-and-16 play, training-free intervention loop, PROBEACT is orthogonal to existing train-17 ing pipelines. Evaluated on the LIBERO-plus benchmark, our framework acts as18 a universal safety net, improving the success rate of the OpenVLA-OFT model19 from 69.6% to 74.1%, while demonstrating broad applicability to both base and20 fine-tuned VLA policies.
How Transformers Learn to Plan via Multi-Token Prediction
Apr 13, 2026While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
Theoretical Perspectives on Data Quality and Synergistic Effects in Pre- and Post-Training Reasoning Models
Mar 01, 2026Large Language Models (LLMs) are pretrained on massive datasets and later instruction-tuned via supervised fine-tuning (SFT) or reinforcement learning (RL). Best practices emphasize large, diverse pretraining data, whereas post-training operates differently: SFT relies on smaller, high-quality datasets, while RL benefits more from scale, with larger amounts of feedback often outweighing label quality. Yet it remains unclear why pretraining and RL require large datasets, why SFT excels on smaller ones, and what defines high-quality SFT data. In this work, we theoretically analyze transformers trained on an in-context weight prediction task for linear regression. Our analysis reveals several key findings: $(i)$ balanced pretraining data can induce latent capabilities later activated during post-training, and $(ii)$ SFT learns best from a small set of examples challenging for the pretrained model, while excessively large SFT datasets may dilute informative pretraining signals. In contrast, RL is most effective on large-scale data that is not overly difficult for the pretrained model. We validate these theoretical insights with experiments on large nonlinear transformer architectures.
Beyond What Seems Necessary: Hidden Gains from Scaling Training-Time Reasoning Length under Outcome Supervision
Jan 31, 2026Training LLMs to think and reason for longer has become a key ingredient in building state-of-the-art models that can solve complex problems previously out of reach. Recent efforts pursue this in different ways, such as RL fine-tuning to elicit long CoT or scaling latent reasoning through architectural recurrence. This makes reasoning length an important scaling knob. In this work, we identify a novel phenomenon (both theoretically and experimentally): under outcome-only supervision, out-of-distribution (OOD) performance can continue improving as training-time reasoning length (e.g., the token budget in RL, or the loop count in looped Transformers) increases, even after in-distribution (ID) performance has saturated. This suggests that robustness may require a larger budget than ID validation alone would indicate. We provide theoretical explanations via two mechanisms: (i) self-iteration can induce a stronger inductive bias in the hypothesis class, reshaping ID-optimal solutions in ways that improve OOD generalization; and (ii) when shortcut solutions that work for ID samples but not for OOD samples persist in the hypothesis class, regularization can reduce the learned solution's reliance on these shortcuts as the number of self-iterations increases. We complement the theory with empirical evidence from two realizations of scaling training-time reasoning length: increasing the number of loops in looped Transformers on a synthetic task, and increasing token budgets during RL fine-tuning of LLMs on mathematical reasoning.
Data Distribution as a Lever for Guiding Optimizers Toward Superior Generalization in LLMs
Jan 31, 2026Can modifying the training data distribution guide optimizers toward solutions with improved generalization when training large language models (LLMs)? In this work, we theoretically analyze an in-context linear regression model with multi-head linear self-attention, and compare the training dynamics of two gradient based optimizers, namely gradient descent (GD) and sharpness-aware minimization (SAM), the latter exhibiting superior generalization properties but is prohibitively expensive for training even medium-sized LLMs. We show, for the first time, that SAM induces a lower simplicity bias (SB)-the tendency of an optimizer to preferentially learn simpler features earlier in training-and identify this reduction as a key factor underlying its improved generalization performance. Motivated by this insight, we demonstrate that altering the training data distribution by upsampling or augmenting examples learned later in training similarly reduces SB and leads to improved generalization. Our extensive experiments show that our strategy improves the performance of multiple LLMs-including Phi2-2.7B , Llama3.2-1B, Gemma3-1B-PT, and Qwen3-0.6B-Base-achieving relative accuracy gains up to 18% when fine-tuned with AdamW and Muon on mathematical reasoning tasks.
Tuning the Implicit Regularizer of Masked Diffusion Language Models: Enhancing Generalization via Insights from $k$-Parity
Jan 30, 2026Masked Diffusion Language Models have recently emerged as a powerful generative paradigm, yet their generalization properties remain understudied compared to their auto-regressive counterparts. In this work, we investigate these properties within the setting of the $k$-parity problem (computing the XOR sum of $k$ relevant bits), where neural networks typically exhibit grokking -- a prolonged plateau of chance-level performance followed by sudden generalization. We theoretically decompose the Masked Diffusion (MD) objective into a Signal regime which drives feature learning, and a Noise regime which serves as an implicit regularizer. By training nanoGPT using MD objective on the $k$-parity problem, we demonstrate that MD objective fundamentally alters the learning landscape, enabling rapid and simultaneous generalization without experiencing grokking. Furthermore, we leverage our theoretical insights to optimize the distribution of the mask probability in the MD objective. Our method significantly improves perplexity for 50M-parameter models and achieves superior results across both pre-training from scratch and supervised fine-tuning. Specifically, we observe performance gains peaking at $8.8\%$ and $5.8\%$, respectively, on 8B-parameter models, confirming the scalability and effectiveness of our framework in large-scale masked diffusion language model regimes.
Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories
Oct 01, 2025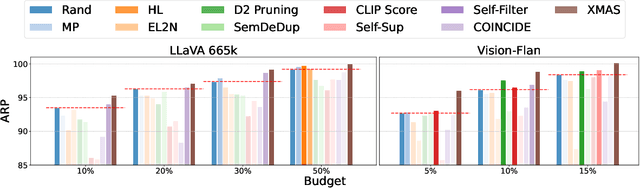

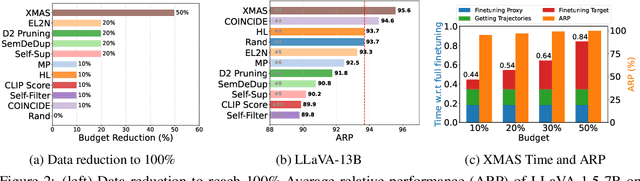

Data-efficient learning aims to eliminate redundancy in large training datasets by training models on smaller subsets of the most informative examples. While data selection has been extensively explored for vision models and large language models (LLMs), it remains underexplored for Large Vision-Language Models (LVLMs). Notably, none of existing methods can outperform random selection at different subset sizes. In this work, we propose the first principled method for data-efficient instruction tuning of LVLMs. We prove that examples with similar cross-modal attention matrices during instruction tuning have similar gradients. Thus, they influence model parameters in a similar manner and convey the same information to the model during training. Building on this insight, we propose XMAS, which clusters examples based on the trajectories of the top singular values of their attention matrices obtained from fine-tuning a small proxy LVLM. By sampling a balanced subset from these clusters, XMAS effectively removes redundancy in large-scale LVLM training data. Extensive experiments show that XMAS can discard 50% of the LLaVA-665k dataset and 85% of the Vision-Flan dataset while fully preserving performance of LLaVA-1.5-7B on 10 downstream benchmarks and speeding up its training by 1.2x. This is 30% more data reduction compared to the best baseline for LLaVA-665k. The project's website can be found at https://bigml-cs-ucla.github.io/XMAS-project-page/.
LoRA is All You Need for Safety Alignment of Reasoning LLMs
Jul 22, 2025


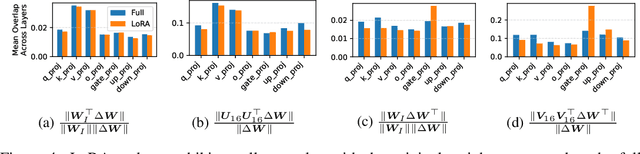
Reasoning LLMs have demonstrated remarkable breakthroughs in solving complex problems that were previously out of reach. To ensure LLMs do not assist with harmful requests, safety alignment fine-tuning is necessary in the post-training phase. However, safety alignment fine-tuning has recently been shown to significantly degrade reasoning abilities, a phenomenon known as the "Safety Tax". In this work, we show that using LoRA for SFT on refusal datasets effectively aligns the model for safety without harming its reasoning capabilities. This is because restricting the safety weight updates to a low-rank space minimizes the interference with the reasoning weights. Our extensive experiments across four benchmarks covering math, science, and coding show that this approach produces highly safe LLMs -- with safety levels comparable to full-model fine-tuning -- without compromising their reasoning abilities. Additionally, we observe that LoRA induces weight updates with smaller overlap with the initial weights compared to full-model fine-tuning. We also explore methods that further reduce such overlap -- via regularization or during weight merging -- and observe some improvement on certain tasks. We hope this result motivates designing approaches that yield more consistent improvements in the reasoning-safety trade-off.
Bootstrapping LLM Robustness for VLM Safety via Reducing the Pretraining Modality Gap
May 30, 2025Ensuring Vision-Language Models (VLMs) generate safe outputs is crucial for their reliable deployment. However, LVLMs suffer from drastic safety degradation compared to their LLM backbone. Even blank or irrelevant images can trigger LVLMs to generate harmful responses to prompts that would otherwise be refused in text-only contexts. The modality gap between image and text representations has been recently hypothesized to contribute to safety degradation of LVLMs. However, if and how the amount of modality gap affects LVLMs' safety is not studied. In this work, we show that the amount of modality gap is highly inversely correlated with VLMs' safety. Then, we show that this modality gap is introduced during pretraining LVLMs and persists through fine-tuning. Inspired by this observation, we propose a regularization to reduce the modality gap during pretraining. Our extensive experiments on LLaVA v1.5, ShareGPT4V, and MiniGPT-4 show that our method substantially improves safety alignment of LVLMs, reducing unsafe rate by up to 16.3% without compromising performance, and can further boost existing defenses by up to 18.2%.