 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTMSE-Net: Long Short Term Speech Enhancement Network for Audio-visual Speech Enhancement
Sep 03, 2024


In this paper, we propose long short term memory speech enhancement network (LSTMSE-Net), an audio-visual speech enhancement (AVSE) method. This innovative method leverages the complementary nature of visual and audio information to boost the quality of speech signals. Visual features are extracted with VisualFeatNet (VFN), and audio features are processed through an encoder and decoder. The system scales and concatenates visual and audio features, then processes them through a separator network for optimized speech enhancement. The architecture highlights advancements in leveraging multi-modal data and interpolation techniques for robust AVSE challenge systems. The performance of LSTMSE-Net surpasses that of the baseline model from the COG-MHEAR AVSE Challenge 2024 by a margin of 0.06 in scale-invariant signal-to-distortion ratio (SISDR), $0.03$ in short-time objective intelligibility (STOI), and $1.32$ in perceptual evaluation of speech quality (PESQ). The source code of the proposed LSTMSE-Net is available at \url{https://github.com/mtanveer1/AVSEC-3-Challenge}.
Data-Efficient Contrastive Language-Image Pretraining: Prioritizing Data Quality over Quantity
Mar 20, 2024Contrastive Language-Image Pre-training (CLIP) on large-scale image-caption datasets learns representations that can achieve remarkable zero-shot generalization. However, such models require a massive amount of pre-training data. Improving the quality of the pre-training data has been shown to be much more effective in improving CLIP's performance than increasing its volume. Nevertheless, finding small subsets of training data that provably generalize the best has remained an open question. In this work, we propose the first theoretically rigorous data selection method for CLIP. We show that subsets that closely preserve the cross-covariance of the images and captions of the full data provably achieve a superior generalization performance. Our extensive experiments on ConceptualCaptions3M and ConceptualCaptions12M demonstrate that subsets found by \method\ achieve over 2.7x and 1.4x the accuracy of the next best baseline on ImageNet and its shifted versions. Moreover, we show that our subsets obtain 1.5x the average accuracy across 11 downstream datasets, of the next best baseline. The code is available at: https://github.com/BigML-CS-UCLA/clipcov-data-efficient-clip.
Confidence-Calibrated Ensemble Dense Phrase Retrieval
Jun 28, 2023In this paper, we consider the extent to which the transformer-based Dense Passage Retrieval (DPR) algorithm, developed by (Karpukhin et. al. 2020), can be optimized without further pre-training. Our method involves two particular insights: we apply the DPR context encoder at various phrase lengths (e.g. one-sentence versus five-sentence segments), and we take a confidence-calibrated ensemble prediction over all of these different segmentations. This somewhat exhaustive approach achieves start-of-the-art results on benchmark datasets such as Google NQ and SQuAD. We also apply our method to domain-specific datasets, and the results suggest how different granularities are optimal for different domains
LB-SimTSC: An Efficient Similarity-Aware Graph Neural Network for Semi-Supervised Time Series Classification
Jan 17, 2023Time series classification is an important data mining task that has received a lot of interest in the past two decades. Due to the label scarcity in practice, semi-supervised time series classification with only a few labeled samples has become popular. Recently, Similarity-aware Time Series Classification (SimTSC) is proposed to address this problem by using a graph neural network classification model on the graph generated from pairwise Dynamic Time Warping (DTW) distance of batch data. It shows excellent accuracy and outperforms state-of-the-art deep learning models in several few-label settings. However, since SimTSC relies on pairwise DTW distances, the quadratic complexity of DTW limits its usability to only reasonably sized datasets. To address this challenge, we propose a new efficient semi-supervised time series classification technique, LB-SimTSC, with a new graph construction module. Instead of using DTW, we propose to utilize a lower bound of DTW, LB_Keogh, to approximate the dissimilarity between instances in linear time, while retaining the relative proximity relationships one would have obtained via computing DTW. We construct the pairwise distance matrix using LB_Keogh and build a graph for the graph neural network. We apply this approach to the ten largest datasets from the well-known UCR time series classification archive. The results demonstrate that this approach can be up to 104x faster than SimTSC when constructing the graph on large datasets without significantly decreasing classification accuracy.
Improved Techniques for GAN based Facial Inpainting
Oct 20, 2018


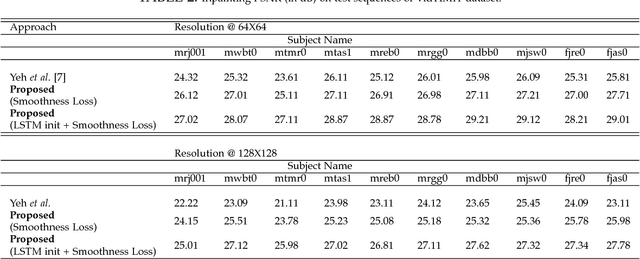
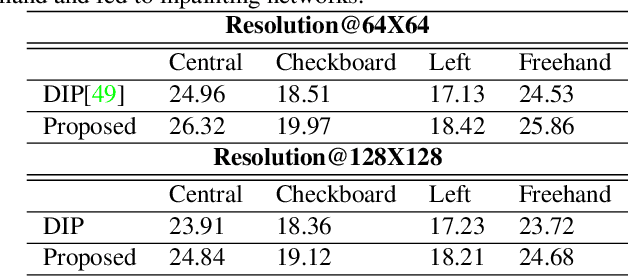
In this paper we present several architectural and optimization recipes for generative adversarial network(GAN) based facial semantic inpainting. Current benchmark models are susceptible to initial solutions of non-convex optimization criterion of GAN based inpainting. We present an end-to-end trainable parametric network to deterministically start from good initial solutions leading to more photo realistic reconstructions with significant optimization speed up. For the first time, we show how to efficiently extend GAN based single image inpainter models to sequences by a)learning to initialize a temporal window of solutions with a recurrent neural network and b)imposing a temporal smoothness loss(during iterative optimization) to respect the redundancy in temporal dimension of a sequence. We conduct comprehensive empirical evaluations on CelebA images and pseudo sequences followed by real life videos of VidTIMIT dataset. The proposed method significantly outperforms current GAN based state-of-the-art in terms of reconstruction quality with a simultaneous speedup of over 15$\times$. We also show that our proposed model is better in preserving facial identity in a sequence even without explicitly using any face recognition module during training.
Improving Consistency and Correctness of Sequence Inpainting using Semantically Guided Generative Adversarial Network
Nov 17, 2017
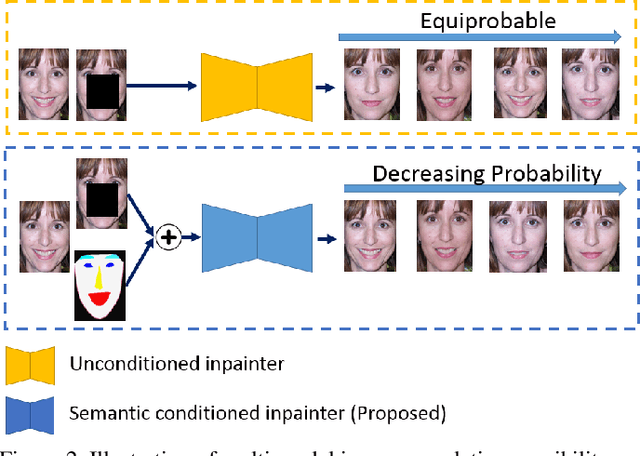

Contemporary benchmark methods for image inpainting are based on deep generative models and specifically leverage adversarial loss for yielding realistic reconstructions. However, these models cannot be directly applied on image/video sequences because of an intrinsic drawback- the reconstructions might be independently realistic, but, when visualized as a sequence, often lacks fidelity to the original uncorrupted sequence. The fundamental reason is that these methods try to find the best matching latent space representation near to natural image manifold without any explicit distance based loss. In this paper, we present a semantically conditioned Generative Adversarial Network (GAN) for sequence inpainting. The conditional information constrains the GAN to map a latent representation to a point in image manifold respecting the underlying pose and semantics of the scene. To the best of our knowledge, this is the first work which simultaneously addresses consistency and correctness of generative model based inpainting. We show that our generative model learns to disentangle pose and appearance information; this independence is exploited by our model to generate highly consistent reconstructions. The conditional information also aids the generator network in GAN to produce sharper images compared to the original GAN formulation. This helps in achieving more appealing inpainting performance. Though generic, our algorithm was targeted for inpainting on faces. When applied on CelebA and Youtube Faces datasets, the proposed method results in a significant improvement over the current benchmark, both in terms of quantitative evaluation (Peak Signal to Noise Ratio) and human visual scoring over diversified combinations of resolutions and deformations.