 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Techniques for GAN based Facial Inpainting
Paper and Code
Oct 20, 2018


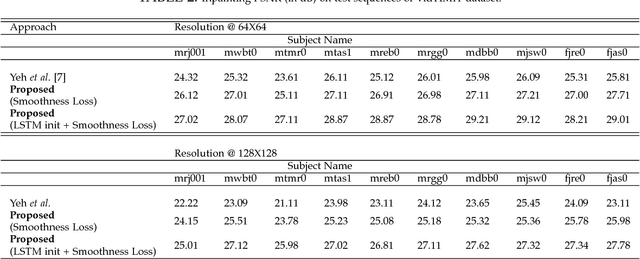
In this paper we present several architectural and optimization recipes for generative adversarial network(GAN) based facial semantic inpainting. Current benchmark models are susceptible to initial solutions of non-convex optimization criterion of GAN based inpainting. We present an end-to-end trainable parametric network to deterministically start from good initial solutions leading to more photo realistic reconstructions with significant optimization speed up. For the first time, we show how to efficiently extend GAN based single image inpainter models to sequences by a)learning to initialize a temporal window of solutions with a recurrent neural network and b)imposing a temporal smoothness loss(during iterative optimization) to respect the redundancy in temporal dimension of a sequence. We conduct comprehensive empirical evaluations on CelebA images and pseudo sequences followed by real life videos of VidTIMIT dataset. The proposed method significantly outperforms current GAN based state-of-the-art in terms of reconstruction quality with a simultaneous speedup of over 15$\times$. We also show that our proposed model is better in preserving facial identity in a sequence even without explicitly using any face recognition module during training.