 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework using Intuitionistic Fuzzy Logic with U-Net and U-Net++ Architecture: A case Study of MRI Bain Image Segmentation
Mar 15, 2026Accurate segmentation of brain images from magnetic resonance imaging (MRI) scans plays a pivotal role in brain image analysis and the diagnosis of neurological disorders. Deep learning algorithms, particularly U-Net and U-Net++, are widely used for image segmentation. However, it finds difficult to deal with uncertainty in images. To address this challenge, this work integrates intuitionistic fuzzy logic into U-Net and U-Net++, propose a novel framework, named as IFS U-Net and IFS U-Net++. These models accept input data in an intuitionistic fuzzy representation to manage uncertainty arising from vague ness and imprecise data. This approach effectively handles tissue ambiguity caused by the partial volume effect and boundary uncertainties. To evaluate the effectiveness of IFS U-Net and IFS U-Net++, experiments are conducted on two publicly available MRI brain datasets: the Internet Brain Segmentation Repository (IBSR) and the Open Access Series of Imaging Studies (OASIS). Segmentation performance is quantitatively assessed using Accuracy, Dice Coefficient, and Intersection over Union (IoU). The results demonstrate that the proposed architectures consistently improve segmentation performance by effectively addressing uncertainty
Twin Restricted Kernel Machines for Multiview Classification
Dec 12, 2025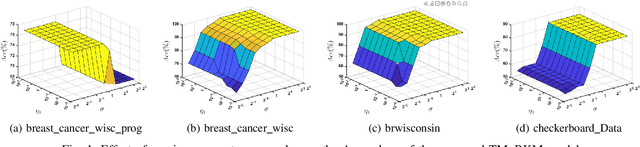
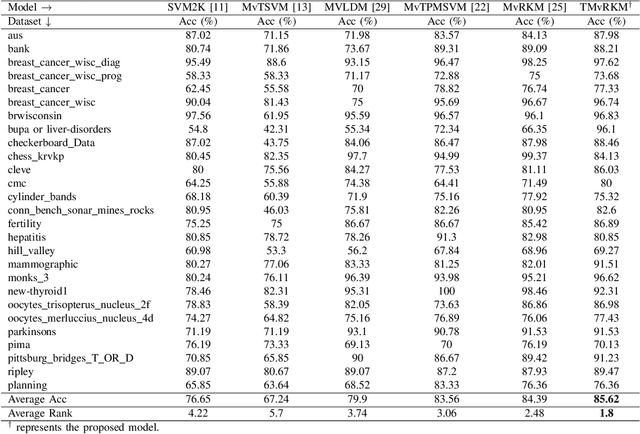
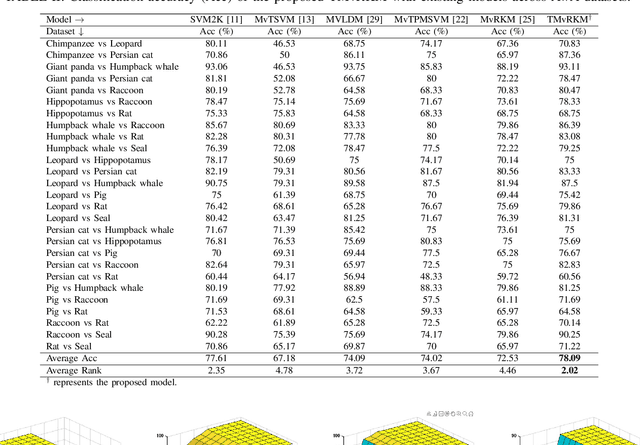
Multi-view learning (MVL) is an emerging field in machine learning that focuses on improving generalization performance by leveraging complementary information from multiple perspectives or views. Various multi-view support vector machine (MvSVM) approaches have been developed, demonstrating significant success. Moreover, these models face challenges in effectively capturing decision boundaries in high-dimensional spaces using the kernel trick. They are also prone to errors and struggle with view inconsistencies, which are common in multi-view datasets. In this work, we introduce the multiview twin restricted kernel machine (TMvRKM), a novel model that integrates the strengths of kernel machines with the multiview framework, addressing key computational and generalization challenges associated with traditional kernel-based approaches. Unlike traditional methods that rely on solving large quadratic programming problems (QPPs), the proposed TMvRKM efficiently determines an optimal separating hyperplane through a regularized least squares approach, enhancing both computational efficiency and classification performance. The primal objective of TMvRKM includes a coupling term designed to balance errors across multiple views effectively. By integrating early and late fusion strategies, TMvRKM leverages the collective information from all views during training while remaining flexible to variations specific to individual views. The proposed TMvRKM model is rigorously tested on UCI, KEEL, and AwA benchmark datasets. Both experimental results and statistical analyses consistently highlight its exceptional generalization performance, outperforming baseline models in every scenario.
* pp. 1-8
R^2VFL: A Robust Random Vector Functional Link Network with Huber-Weighted Framework
Apr 29, 2025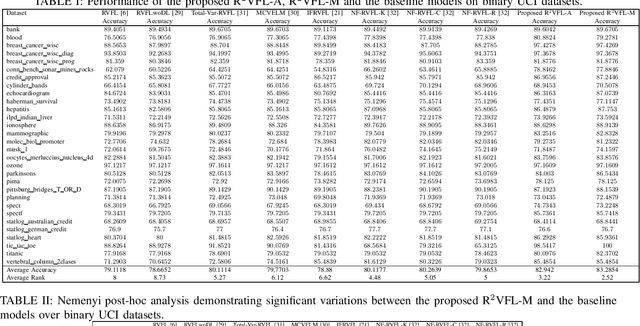
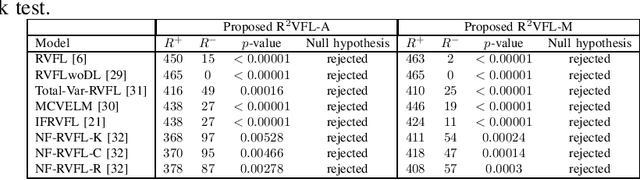
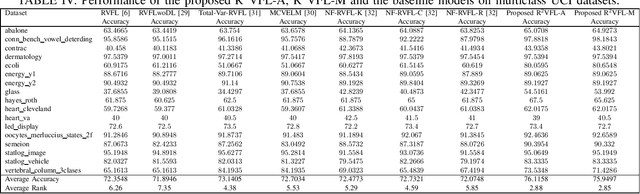
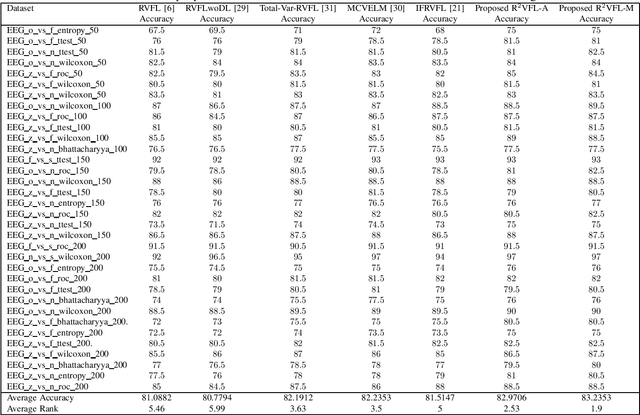
The random vector functional link (RVFL) neural network has shown significant potential in overcoming the constraints of traditional artificial neural networks, such as excessive computation time and suboptimal solutions. However, RVFL faces challenges when dealing with noise and outliers, as it assumes all data samples contribute equally. To address this issue, we propose a novel robust framework, R2VFL, RVFL with Huber weighting function and class probability, which enhances the model's robustness and adaptability by effectively mitigating the impact of noise and outliers in the training data. The Huber weighting function reduces the influence of outliers, while the class probability mechanism assigns less weight to noisy data points, resulting in a more resilient model. We explore two distinct approaches for calculating class centers within the R2VFL framework: the simple average of all data points in each class and the median of each feature, the later providing a robust alternative by minimizing the effect of extreme values. These approaches give rise to two novel variants of the model-R2VFL-A and R2VFL-M. We extensively evaluate the proposed models on 47 UCI datasets, encompassing both binary and multiclass datasets, and conduct rigorous statistical testing, which confirms the superiority of the proposed models. Notably, the models also demonstrate exceptional performance in classifying EEG signals, highlighting their practical applicability in real-world biomedical domain.
CI-RKM: A Class-Informed Approach to Robust Restricted Kernel Machines
Apr 12, 2025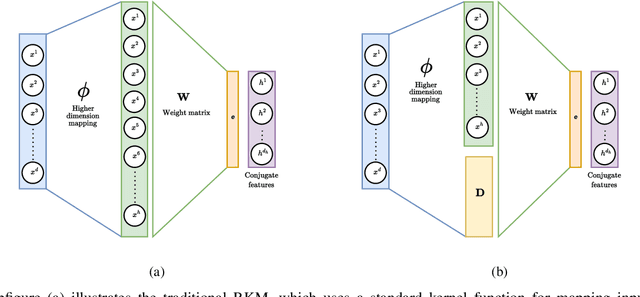
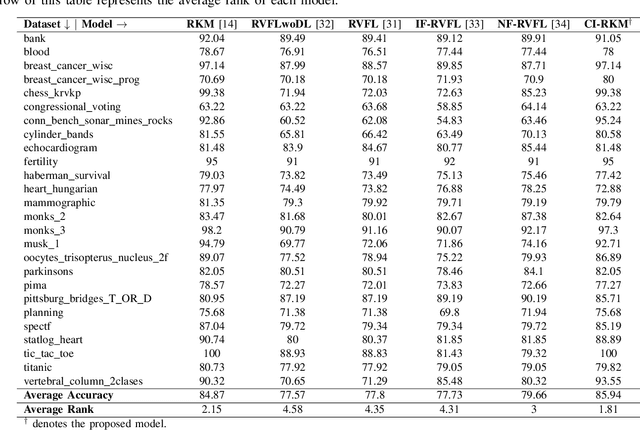
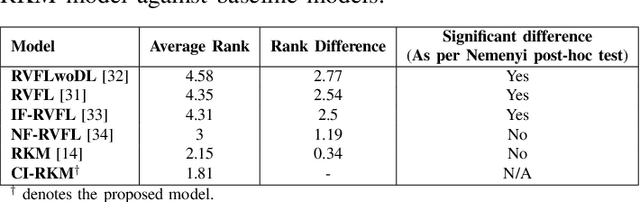
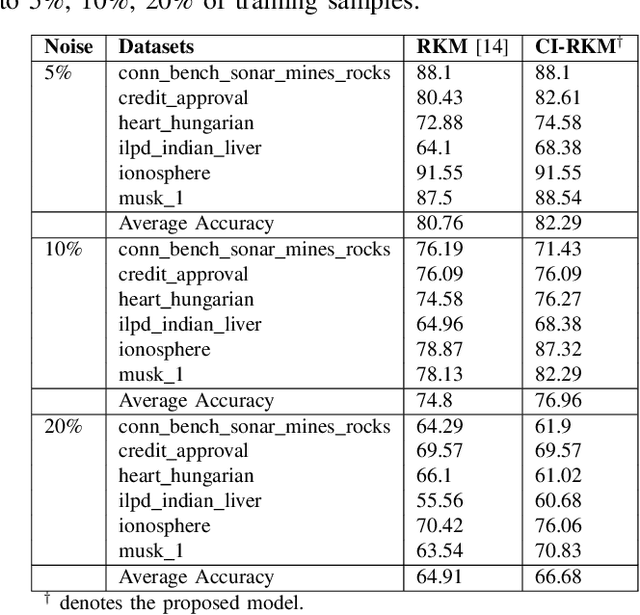
Restricted kernel machines (RKMs) represent a versatile and powerful framework within the kernel machine family, leveraging conjugate feature duality to address a wide range of machine learning tasks, including classification, regression, and feature learning. However, their performance can degrade significantly in the presence of noise and outliers, which compromises robustness and predictive accuracy. In this paper, we propose a novel enhancement to the RKM framework by integrating a class-informed weighted function. This weighting mechanism dynamically adjusts the contribution of individual training points based on their proximity to class centers and class-specific characteristics, thereby mitigating the adverse effects of noisy and outlier data. By incorporating weighted conjugate feature duality and leveraging the Schur complement theorem, we introduce the class-informed restricted kernel machine (CI-RKM), a robust extension of the RKM designed to improve generalization and resilience to data imperfections. Experimental evaluations on benchmark datasets demonstrate that the proposed CI-RKM consistently outperforms existing baselines, achieving superior classification accuracy and enhanced robustness against noise and outliers. Our proposed method establishes a significant advancement in the development of kernel-based learning models, addressing a core challenge in the field.
Enhancing Imbalance Learning: A Novel Slack-Factor Fuzzy SVM Approach
Nov 26, 2024



In real-world applications, class-imbalanced datasets pose significant challenges for machine learning algorithms, such as support vector machines (SVMs), particularly in effectively managing imbalance, noise, and outliers. Fuzzy support vector machines (FSVMs) address class imbalance by assigning varying fuzzy memberships to samples; however, their sensitivity to imbalanced datasets can lead to inaccurate assessments. The recently developed slack-factor-based FSVM (SFFSVM) improves traditional FSVMs by using slack factors to adjust fuzzy memberships based on misclassification likelihood, thereby rectifying misclassifications induced by the hyperplane obtained via different error cost (DEC). Building on SFFSVM, we propose an improved slack-factor-based FSVM (ISFFSVM) that introduces a novel location parameter. This novel parameter significantly advances the model by constraining the DEC hyperplane's extension, thereby mitigating the risk of misclassifying minority class samples. It ensures that majority class samples with slack factor scores approaching the location threshold are assigned lower fuzzy memberships, which enhances the model's discrimination capability. Extensive experimentation on a diverse array of real-world KEEL datasets demonstrates that the proposed ISFFSVM consistently achieves higher F1-scores, Matthews correlation coefficients (MCC), and area under the precision-recall curve (AUC-PR) compared to baseline classifiers. Consequently, the introduction of the location parameter, coupled with the slack-factor-based fuzzy membership, enables ISFFSVM to outperform traditional approaches, particularly in scenarios characterized by severe class disparity. The code for the proposed model is available at \url{https://github.com/mtanveer1/ISFFSVM}.
Intuitionistic Fuzzy Universum Twin Support Vector Machine for Imbalanced Data
Oct 27, 2024One of the major difficulties in machine learning methods is categorizing datasets that are imbalanced. This problem may lead to biased models, where the training process is dominated by the majority class, resulting in inadequate representation of the minority class. Universum twin support vector machine (UTSVM) produces a biased model towards the majority class, as a result, its performance on the minority class is often poor as it might be mistakenly classified as noise. Moreover, UTSVM is not proficient in handling datasets that contain outliers and noises. Inspired by the concept of incorporating prior information about the data and employing an intuitionistic fuzzy membership scheme, we propose intuitionistic fuzzy universum twin support vector machines for imbalanced data (IFUTSVM-ID). We use an intuitionistic fuzzy membership scheme to mitigate the impact of noise and outliers. Moreover, to tackle the problem of imbalanced class distribution, data oversampling and undersampling methods are utilized. Prior knowledge about the data is provided by universum data. This leads to better generalization performance. UTSVM is susceptible to overfitting risks due to the omission of the structural risk minimization (SRM) principle in their primal formulations. However, the proposed IFUTSVM-ID model incorporates the SRM principle through the incorporation of regularization terms, effectively addressing the issue of overfitting. We conduct a comprehensive evaluation of the proposed IFUTSVM-ID model on benchmark datasets from KEEL and compare it with existing baseline models. Furthermore, to assess the effectiveness of the proposed IFUTSVM-ID model in diagnosing Alzheimer's disease (AD), we applied them to the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Experimental results showcase the superiority of the proposed IFUTSVM-ID models compared to the baseline models.
Enhancing Robustness and Efficiency of Least Square Twin SVM via Granular Computing
Oct 22, 2024



In the domain of machine learning, least square twin support vector machine (LSTSVM) stands out as one of the state-of-the-art models. However, LSTSVM suffers from sensitivity to noise and outliers, overlooking the SRM principle and instability in resampling. Moreover, its computational complexity and reliance on matrix inversions hinder the efficient processing of large datasets. As a remedy to the aforementioned challenges, we propose the robust granular ball LSTSVM (GBLSTSVM). GBLSTSVM is trained using granular balls instead of original data points. The core of a granular ball is found at its center, where it encapsulates all the pertinent information of the data points within the ball of specified radius. To improve scalability and efficiency, we further introduce the large-scale GBLSTSVM (LS-GBLSTSVM), which incorporates the SRM principle through regularization terms. Experiments are performed on UCI, KEEL, and NDC benchmark datasets; both the proposed GBLSTSVM and LS-GBLSTSVM models consistently outperform the baseline models.
Flexi-Fuzz least squares SVM for Alzheimer's diagnosis: Tackling noise, outliers, and class imbalance
Oct 18, 2024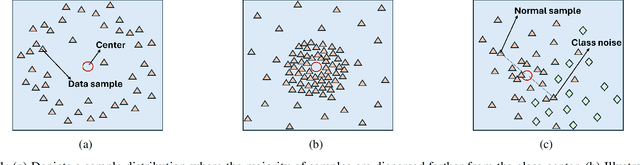
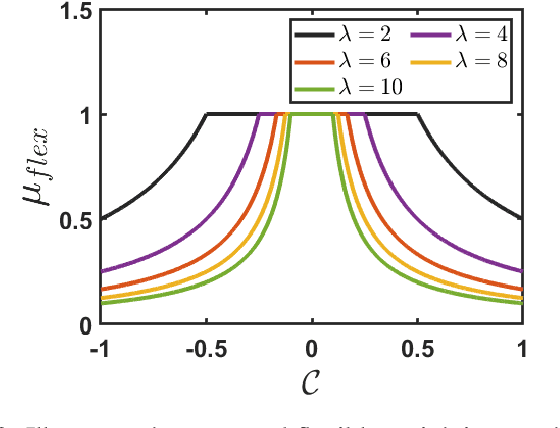


Alzheimer's disease (AD) is a leading neurodegenerative condition and the primary cause of dementia, characterized by progressive cognitive decline and memory loss. Its progression, marked by shrinkage in the cerebral cortex, is irreversible. Numerous machine learning algorithms have been proposed for the early diagnosis of AD. However, they often struggle with the issues of noise, outliers, and class imbalance. To tackle the aforementioned limitations, in this article, we introduce a novel, robust, and flexible membership scheme called Flexi-Fuzz. This scheme integrates a novel flexible weighting mechanism, class probability, and imbalance ratio. The proposed flexible weighting mechanism assigns the maximum weight to samples within a specific proximity to the center, with a gradual decrease in weight beyond a certain threshold. This approach ensures that samples near the class boundary still receive significant weight, maintaining their influence in the classification process. Class probability is used to mitigate the impact of noisy samples, while the imbalance ratio addresses class imbalance. Leveraging this, we incorporate the proposed Flexi-Fuzz membership scheme into the least squares support vector machines (LSSVM) framework, resulting in a robust and flexible model termed Flexi-Fuzz-LSSVM. We determine the class-center using two methods: the conventional mean approach and an innovative median approach, leading to two model variants, Flexi-Fuzz-LSSVM-I and Flexi-Fuzz-LSSVM-II. To validate the effectiveness of the proposed Flexi-Fuzz-LSSVM models, we evaluated them on benchmark UCI and KEEL datasets, both with and without label noise. Additionally, we tested the models on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset for AD diagnosis. Experimental results demonstrate the superiority of the Flexi-Fuzz-LSSVM models over baseline models.
Enhanced Feature Based Granular Ball Twin Support Vector Machine
Oct 08, 2024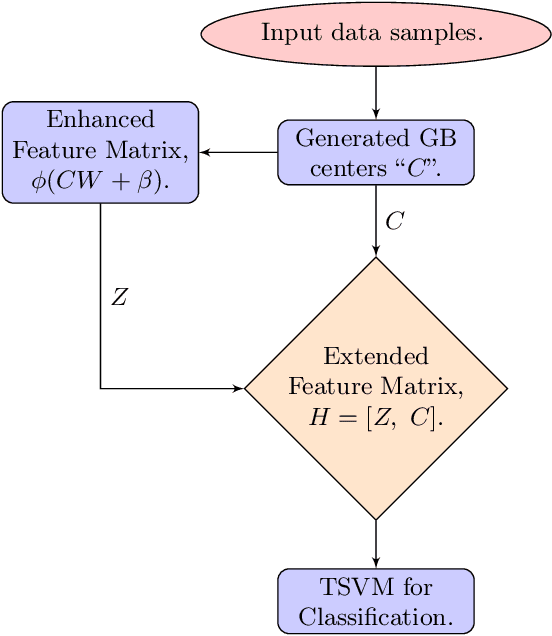



In this paper, we propose enhanced feature based granular ball twin support vector machine (EF-GBTSVM). EF-GBTSVM employs the coarse granularity of granular balls (GBs) as input rather than individual data samples. The GBs are mapped to the feature space of the hidden layer using random projection followed by the utilization of a non-linear activation function. The concatenation of original and hidden features derived from the centers of GBs gives rise to an enhanced feature space, commonly referred to as the random vector functional link (RVFL) space. This space encapsulates nuanced feature information to GBs. Further, we employ twin support vector machine (TSVM) in the RVFL space for classification. TSVM generates the two non-parallel hyperplanes in the enhanced feature space, which improves the generalization performance of the proposed EF-GBTSVM model. Moreover, the coarser granularity of the GBs enables the proposed EF-GBTSVM model to exhibit robustness to resampling, showcasing reduced susceptibility to the impact of noise and outliers. We undertake a thorough evaluation of the proposed EF-GBTSVM model on benchmark UCI and KEEL datasets. This evaluation encompasses scenarios with and without the inclusion of label noise. Moreover, experiments using NDC datasets further emphasize the proposed model's ability to handle large datasets. Experimental results, supported by thorough statistical analyses, demonstrate that the proposed EF-GBTSVM model significantly outperforms the baseline models in terms of generalization capabilities, scalability, and robustness. The source code for the proposed EF-GBTSVM model, along with additional results and further details, can be accessed at https://github.com/mtanveer1/EF-GBTSVM.
Granular Ball Twin Support Vector Machine
Oct 07, 2024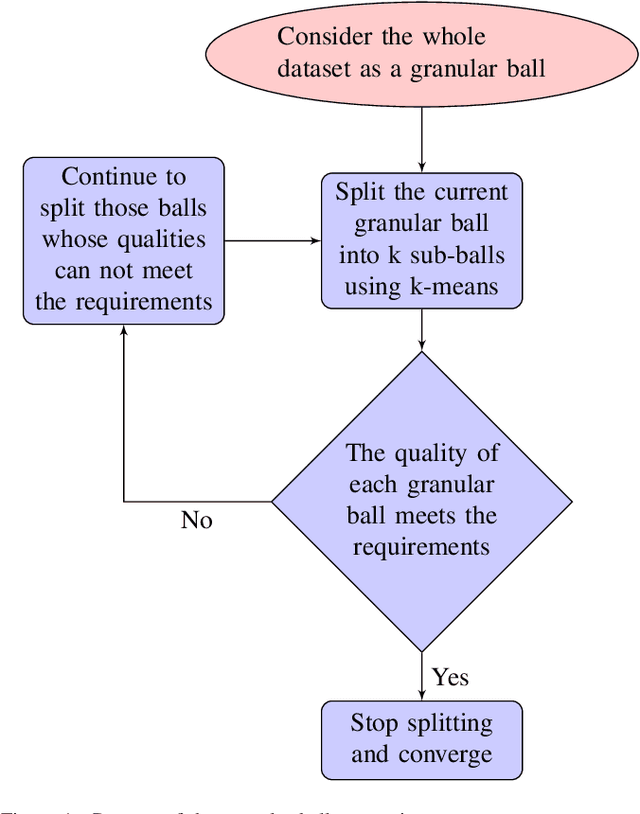
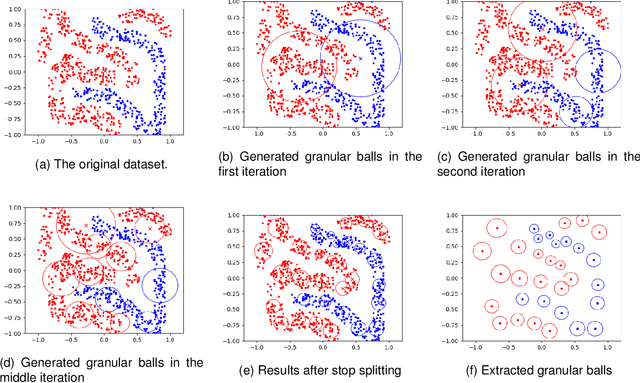
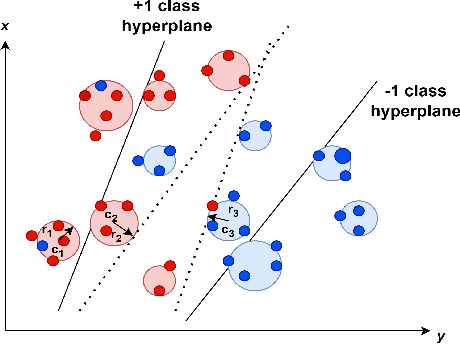

On Efficient and Scalable Computation of the Nonparametric Maximum Likelihood Estimator in Mixture ModelsTwin support vector machine (TSVM) is an emerging machine learning model with versatile applicability in classification and regression endeavors. Nevertheless, TSVM confronts noteworthy challenges: $(i)$ the imperative demand for matrix inversions presents formidable obstacles to its efficiency and applicability on large-scale datasets; $(ii)$ the omission of the structural risk minimization (SRM) principle in its primal formulation heightens the vulnerability to overfitting risks; and $(iii)$ the TSVM exhibits a high susceptibility to noise and outliers, and also demonstrates instability when subjected to resampling. In view of the aforementioned challenges, we propose the granular ball twin support vector machine (GBTSVM). GBTSVM takes granular balls, rather than individual data points, as inputs to construct a classifier. These granular balls, characterized by their coarser granularity, exhibit robustness to resampling and reduced susceptibility to the impact of noise and outliers. We further propose a novel large-scale granular ball twin support vector machine (LS-GBTSVM). LS-GBTSVM's optimization formulation ensures two critical facets: $(i)$ it eliminates the need for matrix inversions, streamlining the LS-GBTSVM's computational efficiency, and $(ii)$ it incorporates the SRM principle through the incorporation of regularization terms, effectively addressing the issue of overfitting. The proposed LS-GBTSVM exemplifies efficiency, scalability for large datasets, and robustness against noise and outliers. We conduct a comprehensive evaluation of the GBTSVM and LS-GBTSVM models on benchmark datasets from UCI, KEEL, and NDC datasets. Our experimental findings and statistical analyses affirm the superior generalization prowess of the proposed GBTSVM and LS-GBTSVM models.
* Manuscript submitted to IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS: 19 September 2023; revised 13 February 2024 and 14 July 2024; accepted 05 October 2024