 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Restricted Kernel Machines for Multiview Classification
Dec 12, 2025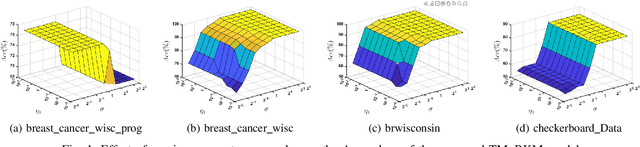
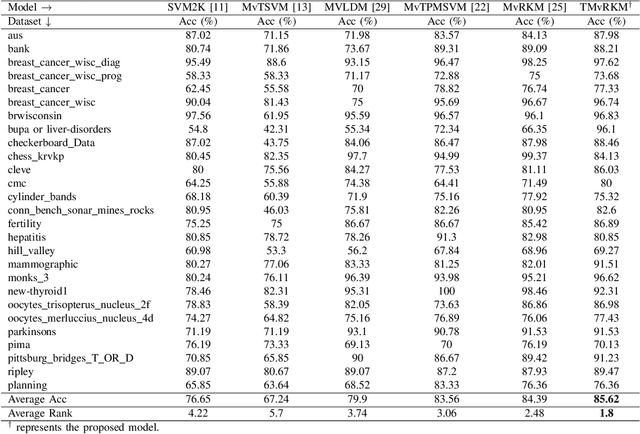
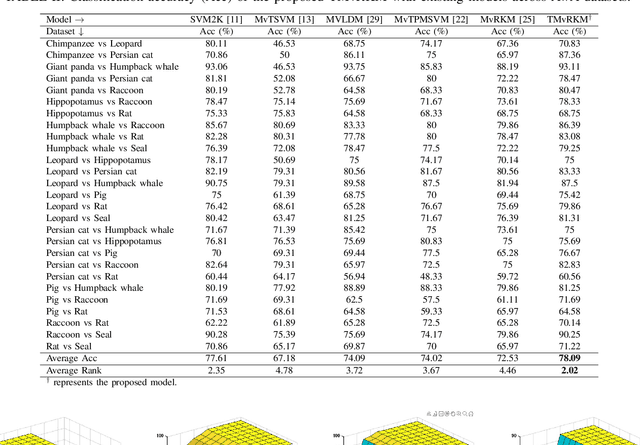
Multi-view learning (MVL) is an emerging field in machine learning that focuses on improving generalization performance by leveraging complementary information from multiple perspectives or views. Various multi-view support vector machine (MvSVM) approaches have been developed, demonstrating significant success. Moreover, these models face challenges in effectively capturing decision boundaries in high-dimensional spaces using the kernel trick. They are also prone to errors and struggle with view inconsistencies, which are common in multi-view datasets. In this work, we introduce the multiview twin restricted kernel machine (TMvRKM), a novel model that integrates the strengths of kernel machines with the multiview framework, addressing key computational and generalization challenges associated with traditional kernel-based approaches. Unlike traditional methods that rely on solving large quadratic programming problems (QPPs), the proposed TMvRKM efficiently determines an optimal separating hyperplane through a regularized least squares approach, enhancing both computational efficiency and classification performance. The primal objective of TMvRKM includes a coupling term designed to balance errors across multiple views effectively. By integrating early and late fusion strategies, TMvRKM leverages the collective information from all views during training while remaining flexible to variations specific to individual views. The proposed TMvRKM model is rigorously tested on UCI, KEEL, and AwA benchmark datasets. Both experimental results and statistical analyses consistently highlight its exceptional generalization performance, outperforming baseline models in every scenario.
* pp. 1-8
Intuitionistic Fuzzy Universum Twin Support Vector Machine for Imbalanced Data
Oct 27, 2024One of the major difficulties in machine learning methods is categorizing datasets that are imbalanced. This problem may lead to biased models, where the training process is dominated by the majority class, resulting in inadequate representation of the minority class. Universum twin support vector machine (UTSVM) produces a biased model towards the majority class, as a result, its performance on the minority class is often poor as it might be mistakenly classified as noise. Moreover, UTSVM is not proficient in handling datasets that contain outliers and noises. Inspired by the concept of incorporating prior information about the data and employing an intuitionistic fuzzy membership scheme, we propose intuitionistic fuzzy universum twin support vector machines for imbalanced data (IFUTSVM-ID). We use an intuitionistic fuzzy membership scheme to mitigate the impact of noise and outliers. Moreover, to tackle the problem of imbalanced class distribution, data oversampling and undersampling methods are utilized. Prior knowledge about the data is provided by universum data. This leads to better generalization performance. UTSVM is susceptible to overfitting risks due to the omission of the structural risk minimization (SRM) principle in their primal formulations. However, the proposed IFUTSVM-ID model incorporates the SRM principle through the incorporation of regularization terms, effectively addressing the issue of overfitting. We conduct a comprehensive evaluation of the proposed IFUTSVM-ID model on benchmark datasets from KEEL and compare it with existing baseline models. Furthermore, to assess the effectiveness of the proposed IFUTSVM-ID model in diagnosing Alzheimer's disease (AD), we applied them to the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Experimental results showcase the superiority of the proposed IFUTSVM-ID models compared to the baseline models.
Enhancing Robustness and Efficiency of Least Square Twin SVM via Granular Computing
Oct 22, 2024



In the domain of machine learning, least square twin support vector machine (LSTSVM) stands out as one of the state-of-the-art models. However, LSTSVM suffers from sensitivity to noise and outliers, overlooking the SRM principle and instability in resampling. Moreover, its computational complexity and reliance on matrix inversions hinder the efficient processing of large datasets. As a remedy to the aforementioned challenges, we propose the robust granular ball LSTSVM (GBLSTSVM). GBLSTSVM is trained using granular balls instead of original data points. The core of a granular ball is found at its center, where it encapsulates all the pertinent information of the data points within the ball of specified radius. To improve scalability and efficiency, we further introduce the large-scale GBLSTSVM (LS-GBLSTSVM), which incorporates the SRM principle through regularization terms. Experiments are performed on UCI, KEEL, and NDC benchmark datasets; both the proposed GBLSTSVM and LS-GBLSTSVM models consistently outperform the baseline models.
Flexi-Fuzz least squares SVM for Alzheimer's diagnosis: Tackling noise, outliers, and class imbalance
Oct 18, 2024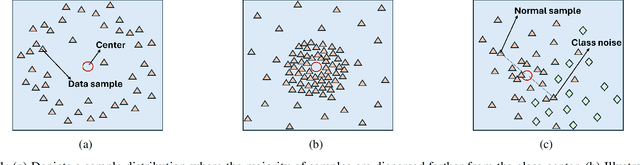
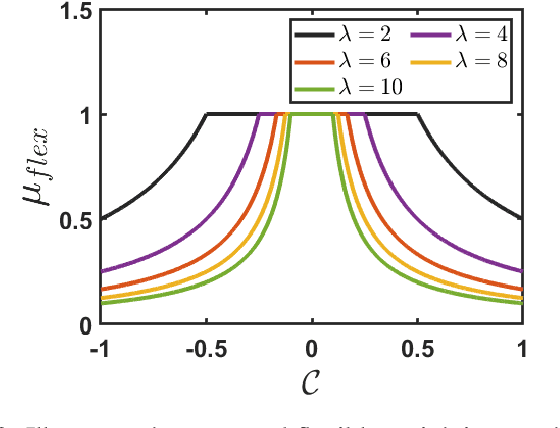


Alzheimer's disease (AD) is a leading neurodegenerative condition and the primary cause of dementia, characterized by progressive cognitive decline and memory loss. Its progression, marked by shrinkage in the cerebral cortex, is irreversible. Numerous machine learning algorithms have been proposed for the early diagnosis of AD. However, they often struggle with the issues of noise, outliers, and class imbalance. To tackle the aforementioned limitations, in this article, we introduce a novel, robust, and flexible membership scheme called Flexi-Fuzz. This scheme integrates a novel flexible weighting mechanism, class probability, and imbalance ratio. The proposed flexible weighting mechanism assigns the maximum weight to samples within a specific proximity to the center, with a gradual decrease in weight beyond a certain threshold. This approach ensures that samples near the class boundary still receive significant weight, maintaining their influence in the classification process. Class probability is used to mitigate the impact of noisy samples, while the imbalance ratio addresses class imbalance. Leveraging this, we incorporate the proposed Flexi-Fuzz membership scheme into the least squares support vector machines (LSSVM) framework, resulting in a robust and flexible model termed Flexi-Fuzz-LSSVM. We determine the class-center using two methods: the conventional mean approach and an innovative median approach, leading to two model variants, Flexi-Fuzz-LSSVM-I and Flexi-Fuzz-LSSVM-II. To validate the effectiveness of the proposed Flexi-Fuzz-LSSVM models, we evaluated them on benchmark UCI and KEEL datasets, both with and without label noise. Additionally, we tested the models on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset for AD diagnosis. Experimental results demonstrate the superiority of the Flexi-Fuzz-LSSVM models over baseline models.
Enhanced Feature Based Granular Ball Twin Support Vector Machine
Oct 08, 2024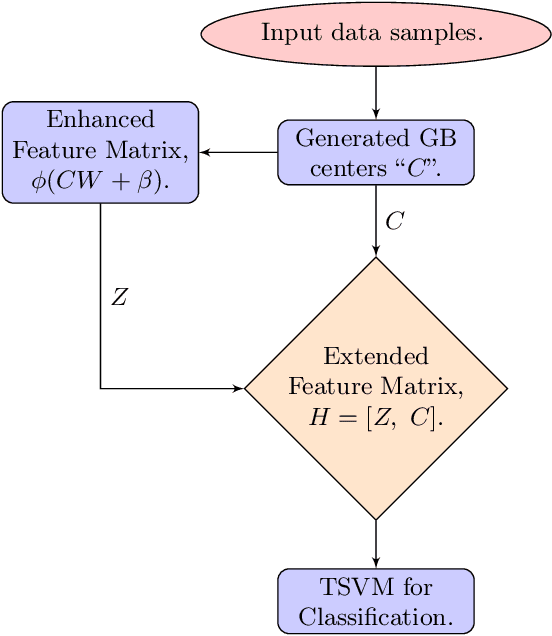



In this paper, we propose enhanced feature based granular ball twin support vector machine (EF-GBTSVM). EF-GBTSVM employs the coarse granularity of granular balls (GBs) as input rather than individual data samples. The GBs are mapped to the feature space of the hidden layer using random projection followed by the utilization of a non-linear activation function. The concatenation of original and hidden features derived from the centers of GBs gives rise to an enhanced feature space, commonly referred to as the random vector functional link (RVFL) space. This space encapsulates nuanced feature information to GBs. Further, we employ twin support vector machine (TSVM) in the RVFL space for classification. TSVM generates the two non-parallel hyperplanes in the enhanced feature space, which improves the generalization performance of the proposed EF-GBTSVM model. Moreover, the coarser granularity of the GBs enables the proposed EF-GBTSVM model to exhibit robustness to resampling, showcasing reduced susceptibility to the impact of noise and outliers. We undertake a thorough evaluation of the proposed EF-GBTSVM model on benchmark UCI and KEEL datasets. This evaluation encompasses scenarios with and without the inclusion of label noise. Moreover, experiments using NDC datasets further emphasize the proposed model's ability to handle large datasets. Experimental results, supported by thorough statistical analyses, demonstrate that the proposed EF-GBTSVM model significantly outperforms the baseline models in terms of generalization capabilities, scalability, and robustness. The source code for the proposed EF-GBTSVM model, along with additional results and further details, can be accessed at https://github.com/mtanveer1/EF-GBTSVM.
Granular Ball Twin Support Vector Machine
Oct 07, 2024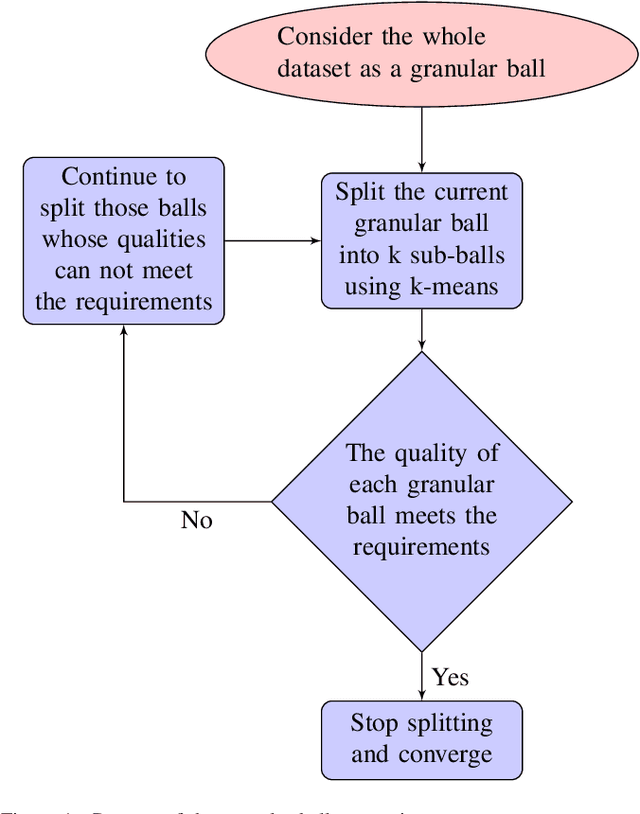
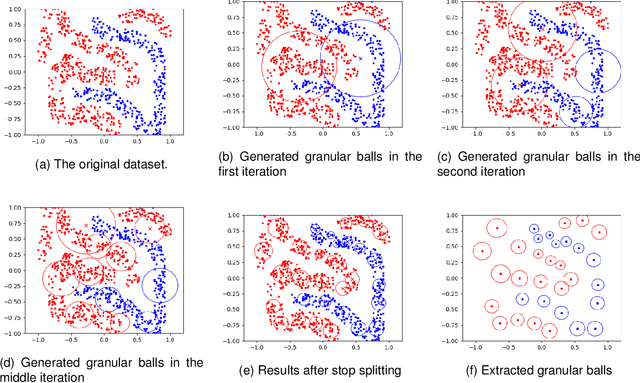
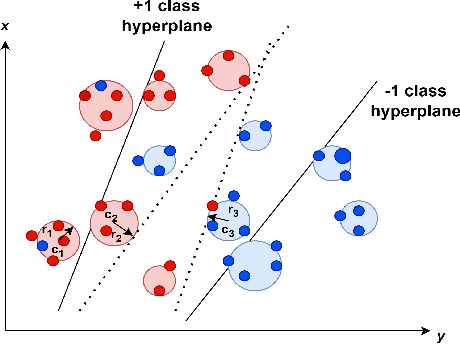

On Efficient and Scalable Computation of the Nonparametric Maximum Likelihood Estimator in Mixture ModelsTwin support vector machine (TSVM) is an emerging machine learning model with versatile applicability in classification and regression endeavors. Nevertheless, TSVM confronts noteworthy challenges: $(i)$ the imperative demand for matrix inversions presents formidable obstacles to its efficiency and applicability on large-scale datasets; $(ii)$ the omission of the structural risk minimization (SRM) principle in its primal formulation heightens the vulnerability to overfitting risks; and $(iii)$ the TSVM exhibits a high susceptibility to noise and outliers, and also demonstrates instability when subjected to resampling. In view of the aforementioned challenges, we propose the granular ball twin support vector machine (GBTSVM). GBTSVM takes granular balls, rather than individual data points, as inputs to construct a classifier. These granular balls, characterized by their coarser granularity, exhibit robustness to resampling and reduced susceptibility to the impact of noise and outliers. We further propose a novel large-scale granular ball twin support vector machine (LS-GBTSVM). LS-GBTSVM's optimization formulation ensures two critical facets: $(i)$ it eliminates the need for matrix inversions, streamlining the LS-GBTSVM's computational efficiency, and $(ii)$ it incorporates the SRM principle through the incorporation of regularization terms, effectively addressing the issue of overfitting. The proposed LS-GBTSVM exemplifies efficiency, scalability for large datasets, and robustness against noise and outliers. We conduct a comprehensive evaluation of the GBTSVM and LS-GBTSVM models on benchmark datasets from UCI, KEEL, and NDC datasets. Our experimental findings and statistical analyses affirm the superior generalization prowess of the proposed GBTSVM and LS-GBTSVM models.
* Manuscript submitted to IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS: 19 September 2023; revised 13 February 2024 and 14 July 2024; accepted 05 October 2024
GB-RVFL: Fusion of Randomized Neural Network and Granular Ball Computing
Sep 25, 2024The random vector functional link (RVFL) network is a prominent classification model with strong generalization ability. However, RVFL treats all samples uniformly, ignoring whether they are pure or noisy, and its scalability is limited due to the need for inverting the entire training matrix. To address these issues, we propose granular ball RVFL (GB-RVFL) model, which uses granular balls (GBs) as inputs instead of training samples. This approach enhances scalability by requiring only the inverse of the GB center matrix and improves robustness against noise and outliers through the coarse granularity of GBs. Furthermore, RVFL overlooks the dataset's geometric structure. To address this, we propose graph embedding GB-RVFL (GE-GB-RVFL) model, which fuses granular computing and graph embedding (GE) to preserve the topological structure of GBs. The proposed GB-RVFL and GE-GB-RVFL models are evaluated on KEEL, UCI, NDC and biomedical datasets, demonstrating superior performance compared to baseline models.
GRVFL-2V: Graph Random Vector Functional Link Based on Two-View Learning
Sep 07, 2024The classification performance of the random vector functional link (RVFL), a randomized neural network, has been widely acknowledged. However, due to its shallow learning nature, RVFL often fails to consider all the relevant information available in a dataset. Additionally, it overlooks the geometrical properties of the dataset. To address these limitations, a novel graph random vector functional link based on two-view learning (GRVFL-2V) model is proposed. The proposed model is trained on multiple views, incorporating the concept of multiview learning (MVL), and it also incorporates the geometrical properties of all the views using the graph embedding (GE) framework. The fusion of RVFL networks, MVL, and GE framework enables our proposed model to achieve the following: i) \textit{efficient learning}: by leveraging the topology of RVFL, our proposed model can efficiently capture nonlinear relationships within the multi-view data, facilitating efficient and accurate predictions; ii) \textit{comprehensive representation}: fusing information from diverse perspectives enhance the proposed model's ability to capture complex patterns and relationships within the data, thereby improving the model's overall generalization performance; and iii) \textit{structural awareness}: by employing the GE framework, our proposed model leverages the original data distribution of the dataset by naturally exploiting both intrinsic and penalty subspace learning criteria. The evaluation of the proposed GRVFL-2V model on various datasets, including 27 UCI and KEEL datasets, 50 datasets from Corel5k, and 45 datasets from AwA, demonstrates its superior performance compared to baseline models. These results highlight the enhanced generalization capabilities of the proposed GRVFL-2V model across a diverse range of datasets.
Multiview Random Vector Functional Link Network for Predicting DNA-Binding Proteins
Sep 04, 2024The identification of DNA-binding proteins (DBPs) is a critical task due to their significant impact on various biological activities. Understanding the mechanisms underlying protein-DNA interactions is essential for elucidating various life activities. In recent years, machine learning-based models have been prominently utilized for DBP prediction. In this paper, to predict DBPs, we propose a novel framework termed a multiview random vector functional link (MvRVFL) network, which fuses neural network architecture with multiview learning. The proposed MvRVFL model combines the benefits of late and early fusion, allowing for distinct regularization parameters across different views while leveraging a closed-form solution to determine unknown parameters efficiently. The primal objective function incorporates a coupling term aimed at minimizing a composite of errors stemming from all views. From each of the three protein views of the DBP datasets, we extract five features. These features are then fused together by incorporating a hidden feature during the model training process. The performance of the proposed MvRVFL model on the DBP dataset surpasses that of baseline models, demonstrating its superior effectiveness. Furthermore, we extend our assessment to the UCI, KEEL, AwA, and Corel5k datasets, to establish the practicality of the proposed models. The consistency error bound, the generalization error bound, and empirical findings, coupled with rigorous statistical analyses, confirm the superior generalization capabilities of the MvRVFL model compared to the baseline models.
Enhancing Multiview Synergy: Robust Learning by Exploiting the Wave Loss Function with Consensus and Complementarity Principles
Aug 13, 2024Multiview learning (MvL) is an advancing domain in machine learning, leveraging multiple data perspectives to enhance model performance through view-consistency and view-discrepancy. Despite numerous successful multiview-based SVM models, existing frameworks predominantly focus on the consensus principle, often overlooking the complementarity principle. Furthermore, they exhibit limited robustness against noisy, error-prone, and view-inconsistent samples, prevalent in multiview datasets. To tackle the aforementioned limitations, this paper introduces Wave-MvSVM, a novel multiview support vector machine framework leveraging the wave loss (W-loss) function, specifically designed to harness both consensus and complementarity principles. Unlike traditional approaches that often overlook the complementary information among different views, the proposed Wave-MvSVM ensures a more comprehensive and resilient learning process by integrating both principles effectively. The W-loss function, characterized by its smoothness, asymmetry, and bounded nature, is particularly effective in mitigating the adverse effects of noisy and outlier data, thereby enhancing model stability. Theoretically, the W-loss function also exhibits a crucial classification-calibrated property, further boosting its effectiveness. Wave-MvSVM employs a between-view co-regularization term to enforce view consistency and utilizes an adaptive combination weight strategy to maximize the discriminative power of each view. The optimization problem is efficiently solved using a combination of GD and the ADMM, ensuring reliable convergence to optimal solutions. Theoretical analyses, grounded in Rademacher complexity, validate the generalization capabilities of the Wave-MvSVM model. Extensive empirical evaluations across diverse datasets demonstrate the superior performance of Wave-MvSVM in comparison to existing benchmark models.