 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR^2VFL: A Robust Random Vector Functional Link Network with Huber-Weighted Framework
Apr 29, 2025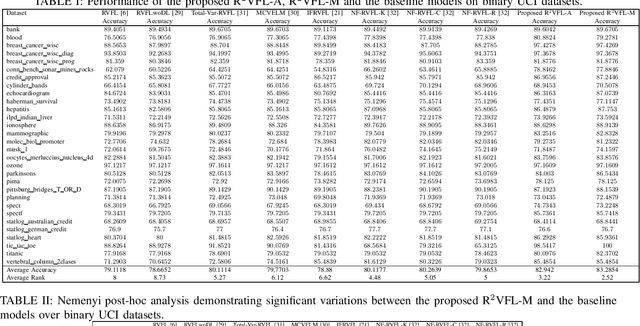
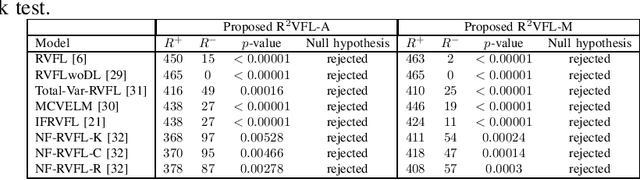
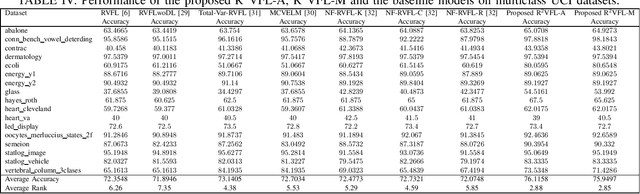
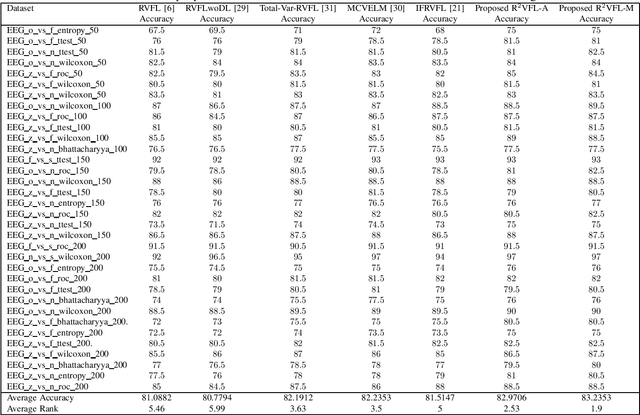
The random vector functional link (RVFL) neural network has shown significant potential in overcoming the constraints of traditional artificial neural networks, such as excessive computation time and suboptimal solutions. However, RVFL faces challenges when dealing with noise and outliers, as it assumes all data samples contribute equally. To address this issue, we propose a novel robust framework, R2VFL, RVFL with Huber weighting function and class probability, which enhances the model's robustness and adaptability by effectively mitigating the impact of noise and outliers in the training data. The Huber weighting function reduces the influence of outliers, while the class probability mechanism assigns less weight to noisy data points, resulting in a more resilient model. We explore two distinct approaches for calculating class centers within the R2VFL framework: the simple average of all data points in each class and the median of each feature, the later providing a robust alternative by minimizing the effect of extreme values. These approaches give rise to two novel variants of the model-R2VFL-A and R2VFL-M. We extensively evaluate the proposed models on 47 UCI datasets, encompassing both binary and multiclass datasets, and conduct rigorous statistical testing, which confirms the superiority of the proposed models. Notably, the models also demonstrate exceptional performance in classifying EEG signals, highlighting their practical applicability in real-world biomedical domain.
Learning Strategies in Particle Swarm Optimizer: A Critical Review and Performance Analysis
Apr 16, 2025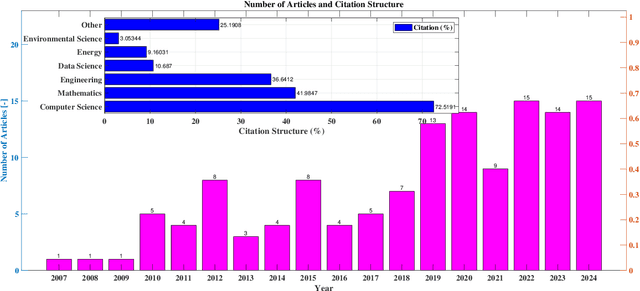



Nature has long inspired the development of swarm intelligence (SI), a key branch of artificial intelligence that models collective behaviors observed in biological systems for solving complex optimization problems. Particle swarm optimization (PSO) is widely adopted among SI algorithms due to its simplicity and efficiency. Despite numerous learning strategies proposed to enhance PSO's performance in terms of convergence speed, robustness, and adaptability, no comprehensive and systematic analysis of these strategies exists. We review and classify various learning strategies to address this gap, assessing their impact on optimization performance. Additionally, a comparative experimental evaluation is conducted to examine how these strategies influence PSO's search dynamics. Finally, we discuss open challenges and future directions, emphasizing the need for self-adaptive, intelligent PSO variants capable of addressing increasingly complex real-world problems.
Enhanced Feature Based Granular Ball Twin Support Vector Machine
Oct 08, 2024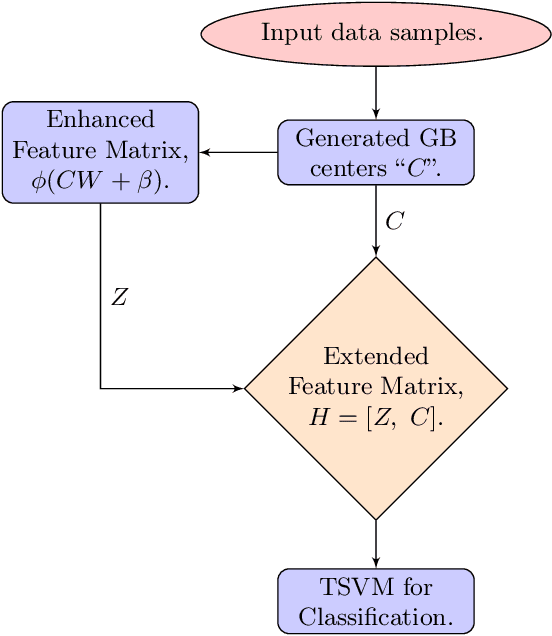



In this paper, we propose enhanced feature based granular ball twin support vector machine (EF-GBTSVM). EF-GBTSVM employs the coarse granularity of granular balls (GBs) as input rather than individual data samples. The GBs are mapped to the feature space of the hidden layer using random projection followed by the utilization of a non-linear activation function. The concatenation of original and hidden features derived from the centers of GBs gives rise to an enhanced feature space, commonly referred to as the random vector functional link (RVFL) space. This space encapsulates nuanced feature information to GBs. Further, we employ twin support vector machine (TSVM) in the RVFL space for classification. TSVM generates the two non-parallel hyperplanes in the enhanced feature space, which improves the generalization performance of the proposed EF-GBTSVM model. Moreover, the coarser granularity of the GBs enables the proposed EF-GBTSVM model to exhibit robustness to resampling, showcasing reduced susceptibility to the impact of noise and outliers. We undertake a thorough evaluation of the proposed EF-GBTSVM model on benchmark UCI and KEEL datasets. This evaluation encompasses scenarios with and without the inclusion of label noise. Moreover, experiments using NDC datasets further emphasize the proposed model's ability to handle large datasets. Experimental results, supported by thorough statistical analyses, demonstrate that the proposed EF-GBTSVM model significantly outperforms the baseline models in terms of generalization capabilities, scalability, and robustness. The source code for the proposed EF-GBTSVM model, along with additional results and further details, can be accessed at https://github.com/mtanveer1/EF-GBTSVM.
Underwater Acoustic Signal Denoising Algorithms: A Survey of the State-of-the-art
Jul 18, 2024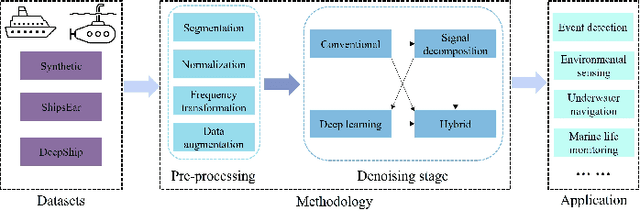
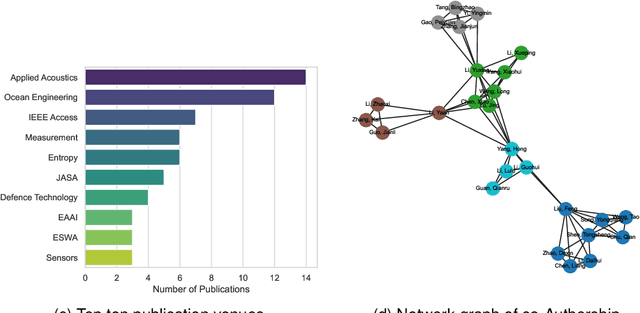

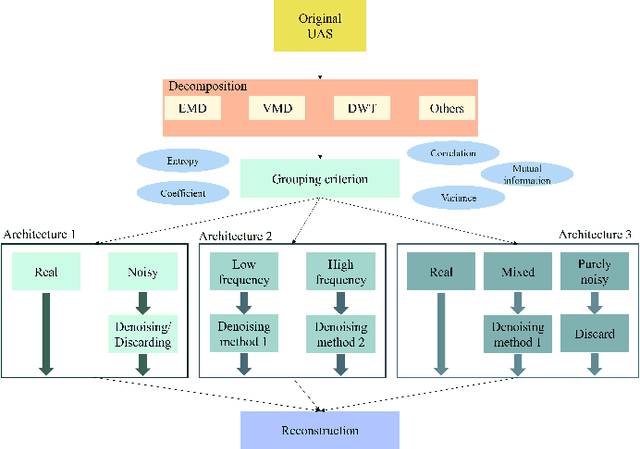
This paper comprehensively reviews recent advances in underwater acoustic signal denoising, an area critical for improving the reliability and clarity of underwater communication and monitoring systems. Despite significant progress in the field, the complex nature of underwater environments poses unique challenges that complicate the denoising process. We begin by outlining the fundamental challenges associated with underwater acoustic signal processing, including signal attenuation, noise variability, and the impact of environmental factors. The review then systematically categorizes and discusses various denoising algorithms, such as conventional, decomposition-based, and learning-based techniques, highlighting their applications, advantages, and limitations. Evaluation metrics and experimental datasets are also reviewed. The paper concludes with a list of open questions and recommendations for future research directions, emphasizing the need for developing more robust denoising techniques that can adapt to the dynamic underwater acoustic environment.
Ensemble Deep Random Vector Functional Link Neural Network Based on Fuzzy Inference System
Jun 02, 2024The ensemble deep random vector functional link (edRVFL) neural network has demonstrated the ability to address the limitations of conventional artificial neural networks. However, since edRVFL generates features for its hidden layers through random projection, it can potentially lose intricate features or fail to capture certain non-linear features in its base models (hidden layers). To enhance the feature learning capabilities of edRVFL, we propose a novel edRVFL based on fuzzy inference system (edRVFL-FIS). The proposed edRVFL-FIS leverages the capabilities of two emerging domains, namely deep learning and ensemble approaches, with the intrinsic IF-THEN properties of fuzzy inference system (FIS) and produces rich feature representation to train the ensemble model. Each base model of the proposed edRVFL-FIS encompasses two key feature augmentation components: a) unsupervised fuzzy layer features and b) supervised defuzzified features. The edRVFL-FIS model incorporates diverse clustering methods (R-means, K-means, Fuzzy C-means) to establish fuzzy layer rules, resulting in three model variations (edRVFL-FIS-R, edRVFL-FIS-K, edRVFL-FIS-C) with distinct fuzzified features and defuzzified features. Within the framework of edRVFL-FIS, each base model utilizes the original, hidden layer and defuzzified features to make predictions. Experimental results, statistical tests, discussions and analyses conducted across UCI and NDC datasets consistently demonstrate the superior performance of all variations of the proposed edRVFL-FIS model over baseline models. The source codes of the proposed models are available at https://github.com/mtanveer1/edRVFL-FIS.
Class-incremental Learning for Time Series: Benchmark and Evaluation
Feb 19, 2024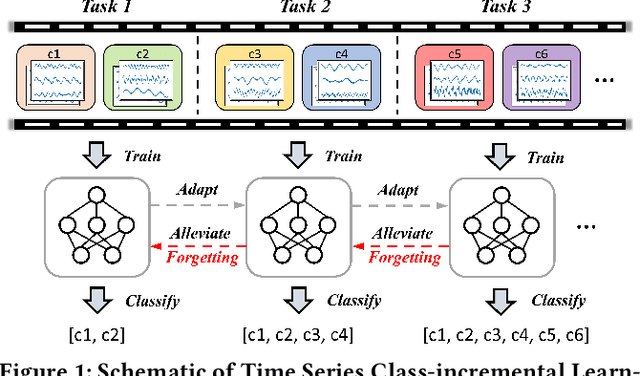
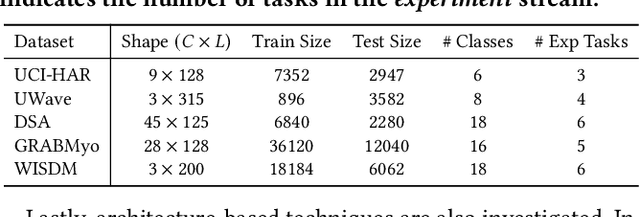
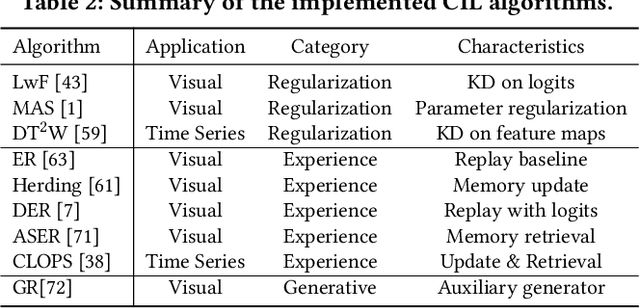
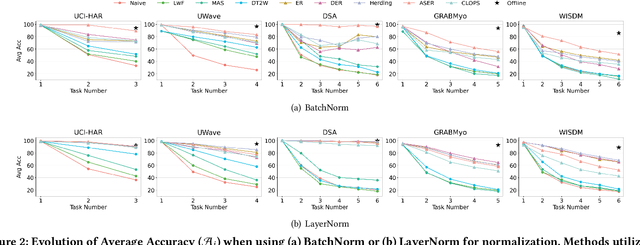
Real-world environments are inherently non-stationary, frequently introducing new classes over time. This is especially common in time series classification, such as the emergence of new disease classification in healthcare or the addition of new activities in human activity recognition. In such cases, a learning system is required to assimilate novel classes effectively while avoiding catastrophic forgetting of the old ones, which gives rise to the Class-incremental Learning (CIL) problem. However, despite the encouraging progress in the image and language domains, CIL for time series data remains relatively understudied. Existing studies suffer from inconsistent experimental designs, necessitating a comprehensive evaluation and benchmarking of methods across a wide range of datasets. To this end, we first present an overview of the Time Series Class-incremental Learning (TSCIL) problem, highlight its unique challenges, and cover the advanced methodologies. Further, based on standardized settings, we develop a unified experimental framework that supports the rapid development of new algorithms, easy integration of new datasets, and standardization of the evaluation process. Using this framework, we conduct a comprehensive evaluation of various generic and time-series-specific CIL methods in both standard and privacy-sensitive scenarios. Our extensive experiments not only provide a standard baseline to support future research but also shed light on the impact of various design factors such as normalization layers or memory budget thresholds. Codes are available at https://github.com/zqiao11/TSCIL.
Reinforcement Learning-assisted Evolutionary Algorithm: A Survey and Research Opportunities
Aug 28, 2023


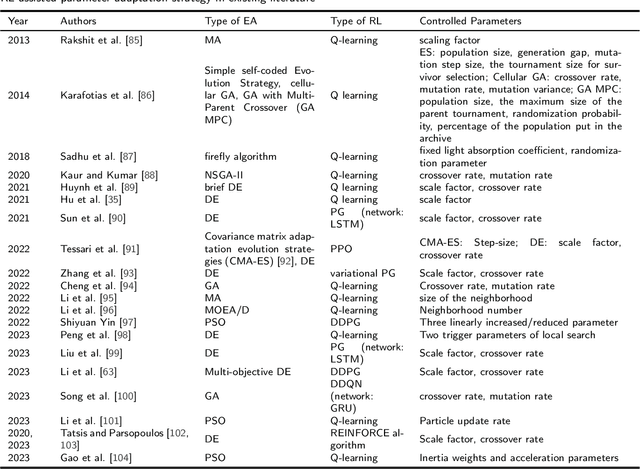
Evolutionary algorithms (EA), a class of stochastic search methods based on the principles of natural evolution, have received widespread acclaim for their exceptional performance in various real-world optimization problems. While researchers worldwide have proposed a wide variety of EAs, certain limitations remain, such as slow convergence speed and poor generalization capabilities. Consequently, numerous scholars actively explore improvements to algorithmic structures, operators, search patterns, etc., to enhance their optimization performance. Reinforcement learning (RL) integrated as a component in the EA framework has demonstrated superior performance in recent years. This paper presents a comprehensive survey on integrating reinforcement learning into the evolutionary algorithm, referred to as reinforcement learning-assisted evolutionary algorithm (RL-EA). We begin with the conceptual outlines of reinforcement learning and the evolutionary algorithm. We then provide a taxonomy of RL-EA. Subsequently, we discuss the RL-EA integration method, the RL-assisted strategy adopted by RL-EA, and its applications according to the existing literature. The RL-assisted procedure is divided according to the implemented functions including solution generation, learnable objective function, algorithm/operator/sub-population selection, parameter adaptation, and other strategies. Finally, we analyze potential directions for future research. This survey serves as a rich resource for researchers interested in RL-EA as it overviews the current state-of-the-art and highlights the associated challenges. By leveraging this survey, readers can swiftly gain insights into RL-EA to develop efficient algorithms, thereby fostering further advancements in this emerging field.
Heterogeneous Oblique Double Random Forest
Apr 13, 2023



The decision tree ensembles use a single data feature at each node for splitting the data. However, splitting in this manner may fail to capture the geometric properties of the data. Thus, oblique decision trees generate the oblique hyperplane for splitting the data at each non-leaf node. Oblique decision trees capture the geometric properties of the data and hence, show better generalization. The performance of the oblique decision trees depends on the way oblique hyperplanes are generate and the data used for the generation of those hyperplanes. Recently, multiple classifiers have been used in a heterogeneous random forest (RaF) classifier, however, it fails to generate the trees of proper depth. Moreover, double RaF studies highlighted that larger trees can be generated via bootstrapping the data at each non-leaf node and splitting the original data instead of the bootstrapped data recently. The study of heterogeneous RaF lacks the generation of larger trees while as the double RaF based model fails to take over the geometric characteristics of the data. To address these shortcomings, we propose heterogeneous oblique double RaF. The proposed model employs several linear classifiers at each non-leaf node on the bootstrapped data and splits the original data based on the optimal linear classifier. The optimal hyperplane corresponds to the models based on the optimized impurity criterion. The experimental analysis indicates that the performance of the introduced heterogeneous double random forest is comparatively better than the baseline models. To demonstrate the effectiveness of the proposed heterogeneous double random forest, we used it for the diagnosis of Schizophrenia disease. The proposed model predicted the disease more accurately compared to the baseline models.
A Reinforcement Learning-assisted Genetic Programming Algorithm for Team Formation Problem Considering Person-Job Matching
Apr 08, 2023
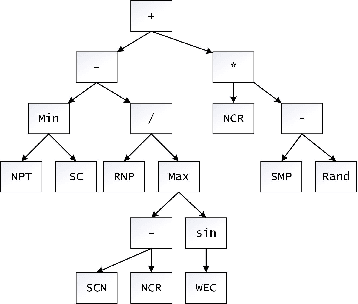
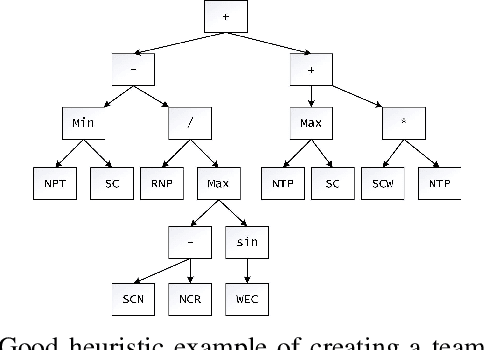
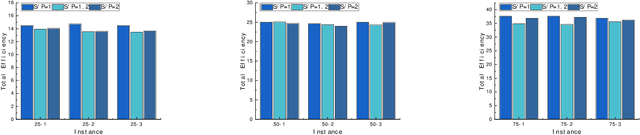
An efficient team is essential for the company to successfully complete new projects. To solve the team formation problem considering person-job matching (TFP-PJM), a 0-1 integer programming model is constructed, which considers both person-job matching and team members' willingness to communicate on team efficiency, with the person-job matching score calculated using intuitionistic fuzzy numbers. Then, a reinforcement learning-assisted genetic programming algorithm (RL-GP) is proposed to enhance the quality of solutions. The RL-GP adopts the ensemble population strategies. Before the population evolution at each generation, the agent selects one from four population search modes according to the information obtained, thus realizing a sound balance of exploration and exploitation. In addition, surrogate models are used in the algorithm to evaluate the formation plans generated by individuals, which speeds up the algorithm learning process. Afterward, a series of comparison experiments are conducted to verify the overall performance of RL-GP and the effectiveness of the improved strategies within the algorithm. The hyper-heuristic rules obtained through efficient learning can be utilized as decision-making aids when forming project teams. This study reveals the advantages of reinforcement learning methods, ensemble strategies, and the surrogate model applied to the GP framework. The diversity and intelligent selection of search patterns along with fast adaptation evaluation, are distinct features that enable RL-GP to be deployed in real-world enterprise environments.
Ensemble Reinforcement Learning: A Survey
Mar 05, 2023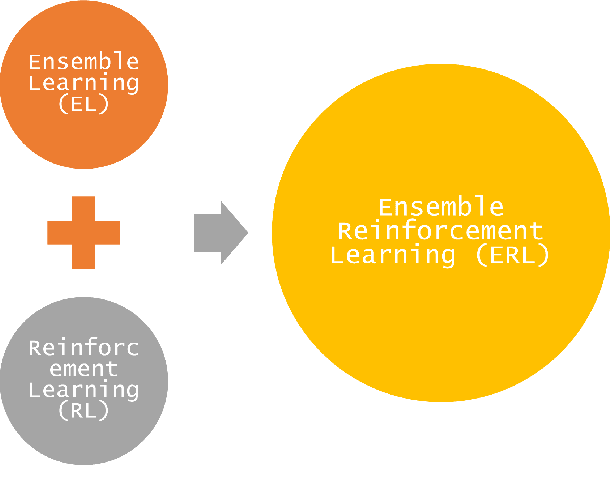
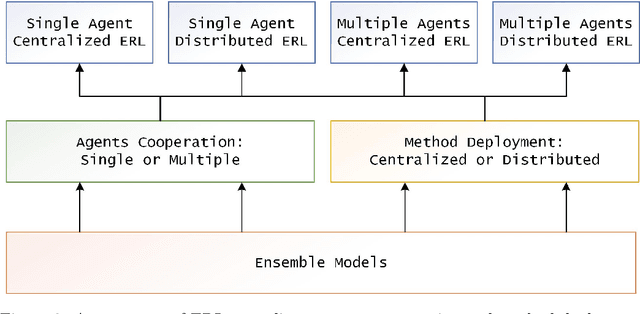

Reinforcement learning (RL) has achieved state-of-the-art performance in many scientific and applied problems. However, some complex tasks still are difficult to handle using a single model and algorithm. The highly popular ensemble reinforcement learning (ERL) has become an important method to handle complex tasks with the advantage of combining reinforcement learning and ensemble learning (EL). ERL combines several models or training algorithms to fully explore the problem space and has strong generalization characteristics. This study presents a comprehensive survey on ERL to provide the readers with an overview of the recent advances and challenges. The background is introduced first. The strategies successfully applied in ERL are analyzed in detail. Finally, we outline some open questions and conclude by discussing some future research directions of ERL. This survey contributes to ERL development by providing a guide for future scientific research and engineering applications.