 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIVIC: End-to-End Sequence Compactness for Efficient Vision-Language Models
May 27, 2026Vision-Language Models (VLMs) face severe memory and latency bottlenecks due to high-resolution visual tokens. While current token reduction methods theoretically save FLOPs, post-hoc pruning introduces structural overhead, failing to yield proportional wall-clock acceleration. However, enforcing a contiguous compact pathway risks geometric disorientation and loss of fine-grained localization. To overcome these barriers, this paper introduces CIVIC, a path-consistent compact visual inference framework. By maintaining compact sequence representations seamlessly across the vision encoder, projection layer, LLM prefill, and KV-cache, CIVIC avoids non-contiguous memory access and localized unmerging overheads. Evaluated on the Qwen3-VL architecture, CIVIC successfully translates sequence reductions into genuine physical hardware efficiency, shrinking KV-cache memory to approximately one-third of the baseline and reducing end-to-end inference latency. Enabled by text-aligned KL distillation and an adaptive spatial retention floor, CIVIC achieves these efficiency milestones without degrading accuracy across rigorous multimodal reasoning and visual grounding benchmarks.
Locatability-Guided Adaptive Reasoning for Image Geo-Localization with Vision-Language Models
Mar 13, 2026The emergence of Vision-Language Models (VLMs) has introduced new paradigms for global image geo-localization through retrieval-augmented generation (RAG) and reasoning-driven inference. However, RAG methods are constrained by retrieval database quality, while reasoning-driven approaches fail to internalize image locatability, relying on inefficient, fixed-depth reasoning paths that increase hallucinations and degrade accuracy. To overcome these limitations, we introduce an Optimized Locatability Score that quantifies an image's suitability for deep reasoning in geo-localization. Using this metric, we curate Geo-ADAPT-51K, a locatability-stratified reasoning dataset enriched with augmented reasoning trajectories for complex visual scenes. Building on this foundation, we propose a two-stage Group Relative Policy Optimization (GRPO) curriculum with customized reward functions that regulate adaptive reasoning depth, visual grounding, and hierarchical geographical accuracy. Our framework, Geo-ADAPT, learns an adaptive reasoning policy, achieves state-of-the-art performance across multiple geo-localization benchmarks, and substantially reduces hallucinations by reasoning both adaptively and efficiently.
KnowDiffuser: A Knowledge-Guided Diffusion Planner with LM Reasoning and Prior-Informed Trajectory Initialization
Mar 11, 2026Recent advancements in Language Models (LMs) have demonstrated strong semantic reasoning capabilities, enabling their application in high-level decision-making for autonomous driving (AD). However, LMs operate over discrete token spaces and lack the ability to generate continuous, physically feasible trajectories required for motion planning. Meanwhile, diffusion models have proven effective at generating reliable and dynamically consistent trajectories, but often lack semantic interpretability and alignment with scene-level understanding. To address these limitations, we propose \textbf{KnowDiffuser}, a knowledge-guided motion planning framework that tightly integrates the semantic understanding of language models with the generative power of diffusion models. The framework employs a language model to infer context-aware meta-actions from structured scene representations, which are then mapped to prior trajectories that anchor the subsequent denoising process. A two-stage truncated denoising mechanism refines these trajectories efficiently, preserving both semantic alignment and physical feasibility. Experiments on the nuPlan benchmark demonstrate that KnowDiffuser significantly outperforms existing planners in both open-loop and closed-loop evaluations, establishing a robust and interpretable framework that effectively bridges the semantic-to-physical gap in AD systems.
Drive As You Like: Strategy-Level Motion Planning Based on A Multi-Head Diffusion Model
Aug 23, 2025Recent advances in motion planning for autonomous driving have led to models capable of generating high-quality trajectories. However, most existing planners tend to fix their policy after supervised training, leading to consistent but rigid driving behaviors. This limits their ability to reflect human preferences or adapt to dynamic, instruction-driven demands. In this work, we propose a diffusion-based multi-head trajectory planner(M-diffusion planner). During the early training stage, all output heads share weights to learn to generate high-quality trajectories. Leveraging the probabilistic nature of diffusion models, we then apply Group Relative Policy Optimization (GRPO) to fine-tune the pre-trained model for diverse policy-specific behaviors. At inference time, we incorporate a large language model (LLM) to guide strategy selection, enabling dynamic, instruction-aware planning without switching models. Closed-loop simulation demonstrates that our post-trained planner retains strong planning capability while achieving state-of-the-art (SOTA) performance on the nuPlan val14 benchmark. Open-loop results further show that the generated trajectories exhibit clear diversity, effectively satisfying multi-modal driving behavior requirements. The code and related experiments will be released upon acceptance of the paper.
AirV2X: Unified Air-Ground Vehicle-to-Everything Collaboration
Jun 24, 2025While multi-vehicular collaborative driving demonstrates clear advantages over single-vehicle autonomy, traditional infrastructure-based V2X systems remain constrained by substantial deployment costs and the creation of "uncovered danger zones" in rural and suburban areas. We present AirV2X-Perception, a large-scale dataset that leverages Unmanned Aerial Vehicles (UAVs) as a flexible alternative or complement to fixed Road-Side Units (RSUs). Drones offer unique advantages over ground-based perception: complementary bird's-eye-views that reduce occlusions, dynamic positioning capabilities that enable hovering, patrolling, and escorting navigation rules, and significantly lower deployment costs compared to fixed infrastructure. Our dataset comprises 6.73 hours of drone-assisted driving scenarios across urban, suburban, and rural environments with varied weather and lighting conditions. The AirV2X-Perception dataset facilitates the development and standardized evaluation of Vehicle-to-Drone (V2D) algorithms, addressing a critical gap in the rapidly expanding field of aerial-assisted autonomous driving systems. The dataset and development kits are open-sourced at https://github.com/taco-group/AirV2X-Perception.
A Comprehensive LLM-powered Framework for Driving Intelligence Evaluation
Mar 07, 2025


Evaluation methods for autonomous driving are crucial for algorithm optimization. However, due to the complexity of driving intelligence, there is currently no comprehensive evaluation method for the level of autonomous driving intelligence. In this paper, we propose an evaluation framework for driving behavior intelligence in complex traffic environments, aiming to fill this gap. We constructed a natural language evaluation dataset of human professional drivers and passengers through naturalistic driving experiments and post-driving behavior evaluation interviews. Based on this dataset, we developed an LLM-powered driving evaluation framework. The effectiveness of this framework was validated through simulated experiments in the CARLA urban traffic simulator and further corroborated by human assessment. Our research provides valuable insights for evaluating and designing more intelligent, human-like autonomous driving agents. The implementation details of the framework and detailed information about the dataset can be found at Github.
* 8 pages, 3 figures
SenseRAG: Constructing Environmental Knowledge Bases with Proactive Querying for LLM-Based Autonomous Driving
Jan 08, 2025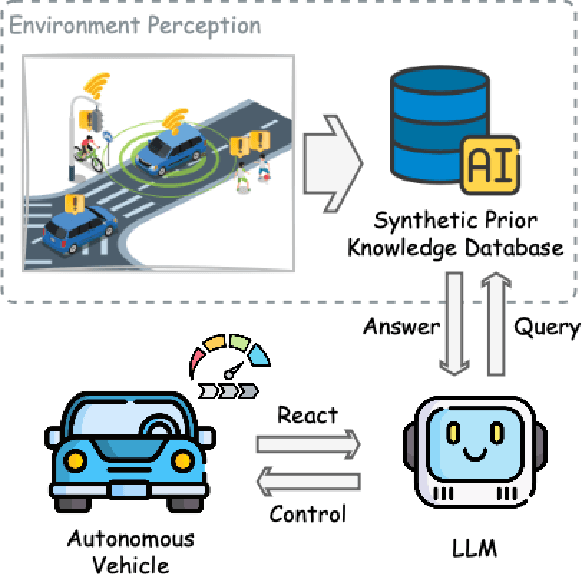
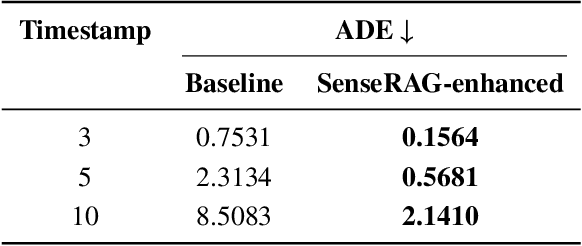
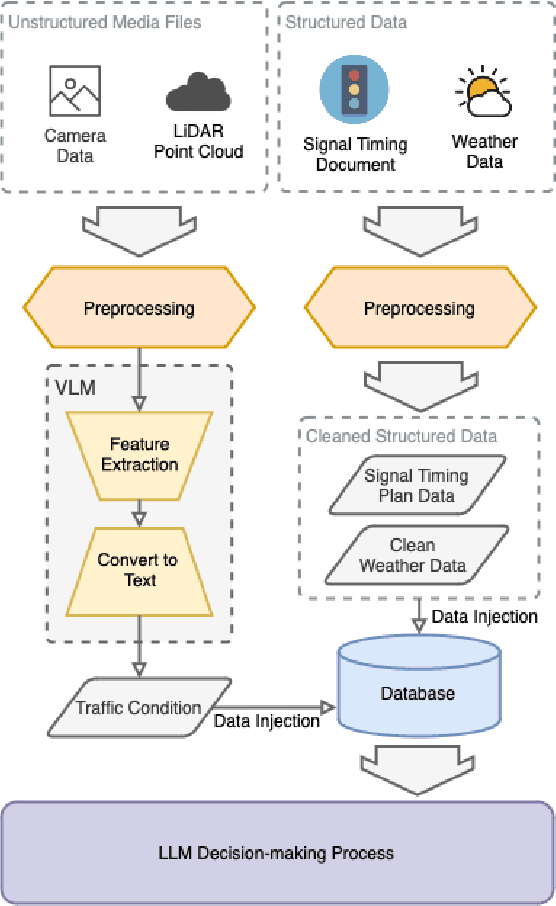
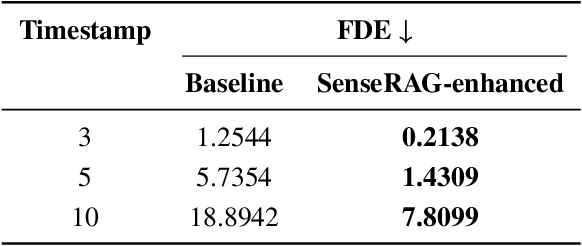
This study addresses the critical need for enhanced situational awareness in autonomous driving (AD) by leveraging the contextual reasoning capabilities of large language models (LLMs). Unlike traditional perception systems that rely on rigid, label-based annotations, it integrates real-time, multimodal sensor data into a unified, LLMs-readable knowledge base, enabling LLMs to dynamically understand and respond to complex driving environments. To overcome the inherent latency and modality limitations of LLMs, a proactive Retrieval-Augmented Generation (RAG) is designed for AD, combined with a chain-of-thought prompting mechanism, ensuring rapid and context-rich understanding. Experimental results using real-world Vehicle-to-everything (V2X) datasets demonstrate significant improvements in perception and prediction performance, highlighting the potential of this framework to enhance safety, adaptability, and decision-making in next-generation AD systems.
KANS: Knowledge Discovery Graph Attention Network for Soft Sensing in Multivariate Industrial Processes
Jan 02, 2025



Soft sensing of hard-to-measure variables is often crucial in industrial processes. Current practices rely heavily on conventional modeling techniques that show success in improving accuracy. However, they overlook the non-linear nature, dynamics characteristics, and non-Euclidean dependencies between complex process variables. To tackle these challenges, we present a framework known as a Knowledge discovery graph Attention Network for effective Soft sensing (KANS). Unlike the existing deep learning soft sensor models, KANS can discover the intrinsic correlations and irregular relationships between the multivariate industrial processes without a predefined topology. First, an unsupervised graph structure learning method is introduced, incorporating the cosine similarity between different sensor embedding to capture the correlations between sensors. Next, we present a graph attention-based representation learning that can compute the multivariate data parallelly to enhance the model in learning complex sensor nodes and edges. To fully explore KANS, knowledge discovery analysis has also been conducted to demonstrate the interpretability of the model. Experimental results demonstrate that KANS significantly outperforms all the baselines and state-of-the-art methods in soft sensing performance. Furthermore, the analysis shows that KANS can find sensors closely related to different process variables without domain knowledge, significantly improving soft sensing accuracy.
PKRD-CoT: A Unified Chain-of-thought Prompting for Multi-Modal Large Language Models in Autonomous Driving
Dec 02, 2024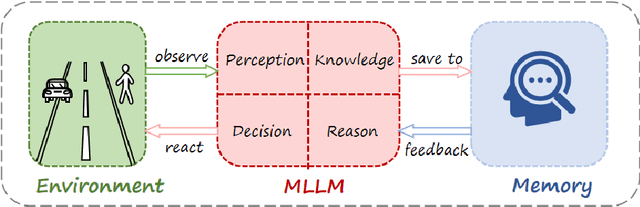


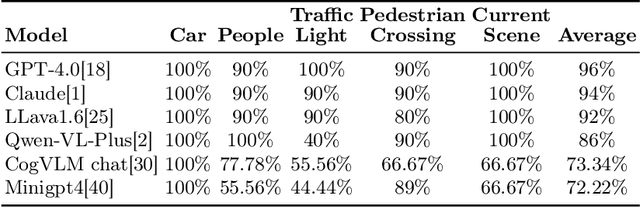
There is growing interest in leveraging the capabilities of robust Multi-Modal Large Language Models (MLLMs) directly within autonomous driving contexts. However, the high costs and complexity of designing and training end-to-end autonomous driving models make them challenging for many enterprises and research entities. To address this, our study explores a seamless integration of MLLMs into autonomous driving systems by proposing a Zero-Shot Chain-of-Thought (Zero-Shot-CoT) prompt design named PKRD-CoT. PKRD-CoT is based on the four fundamental capabilities of autonomous driving: perception, knowledge, reasoning, and decision-making. This makes it particularly suitable for understanding and responding to dynamic driving environments by mimicking human thought processes step by step, thus enhancing decision-making in real-time scenarios. Our design enables MLLMs to tackle problems without prior experience, thereby increasing their utility within unstructured autonomous driving environments. In experiments, we demonstrate the exceptional performance of GPT-4.0 with PKRD-CoT across autonomous driving tasks, highlighting its effectiveness in autonomous driving scenarios. Additionally, our benchmark analysis reveals the promising viability of PKRD-CoT for other MLLMs, such as Claude, LLava1.6, and Qwen-VL-Plus. Overall, this study contributes a novel and unified prompt-design framework for GPT-4.0 and other MLLMs in autonomous driving, while also rigorously evaluating the efficacy of these widely recognized MLLMs in the autonomous driving domain through comprehensive comparisons.
Cross-Domain Transfer Learning using Attention Latent Features for Multi-Agent Trajectory Prediction
Nov 12, 2024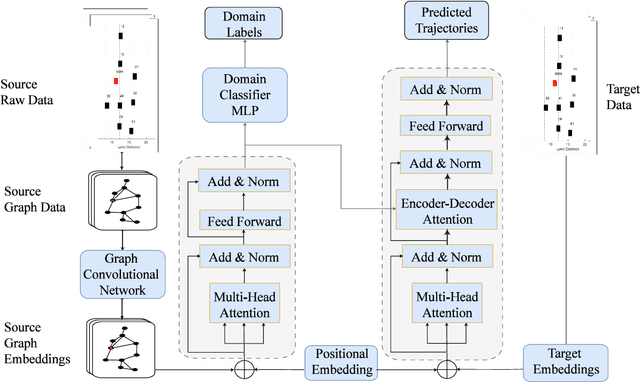
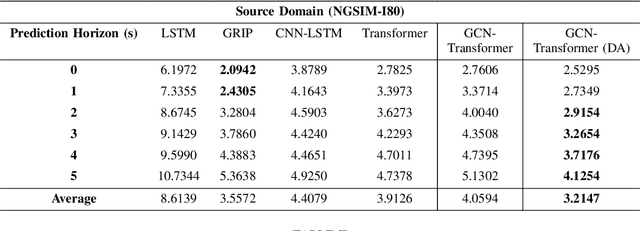
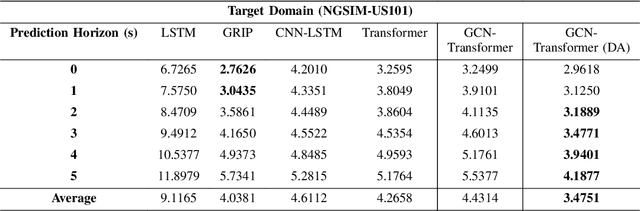
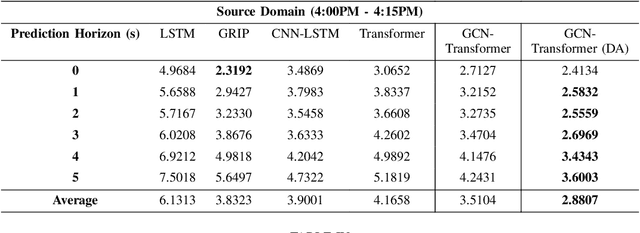
With the advancements of sensor hardware, traffic infrastructure and deep learning architectures, trajectory prediction of vehicles has established a solid foundation in intelligent transportation systems. However, existing solutions are often tailored to specific traffic networks at particular time periods. Consequently, deep learning models trained on one network may struggle to generalize effectively to unseen networks. To address this, we proposed a novel spatial-temporal trajectory prediction framework that performs cross-domain adaption on the attention representation of a Transformer-based model. A graph convolutional network is also integrated to construct dynamic graph feature embeddings that accurately model the complex spatial-temporal interactions between the multi-agent vehicles across multiple traffic domains. The proposed framework is validated on two case studies involving the cross-city and cross-period settings. Experimental results show that our proposed framework achieves superior trajectory prediction and domain adaptation performances over the state-of-the-art models.