 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowDiffuser: A Knowledge-Guided Diffusion Planner with LM Reasoning and Prior-Informed Trajectory Initialization
Mar 11, 2026Recent advancements in Language Models (LMs) have demonstrated strong semantic reasoning capabilities, enabling their application in high-level decision-making for autonomous driving (AD). However, LMs operate over discrete token spaces and lack the ability to generate continuous, physically feasible trajectories required for motion planning. Meanwhile, diffusion models have proven effective at generating reliable and dynamically consistent trajectories, but often lack semantic interpretability and alignment with scene-level understanding. To address these limitations, we propose \textbf{KnowDiffuser}, a knowledge-guided motion planning framework that tightly integrates the semantic understanding of language models with the generative power of diffusion models. The framework employs a language model to infer context-aware meta-actions from structured scene representations, which are then mapped to prior trajectories that anchor the subsequent denoising process. A two-stage truncated denoising mechanism refines these trajectories efficiently, preserving both semantic alignment and physical feasibility. Experiments on the nuPlan benchmark demonstrate that KnowDiffuser significantly outperforms existing planners in both open-loop and closed-loop evaluations, establishing a robust and interpretable framework that effectively bridges the semantic-to-physical gap in AD systems.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Drive As You Like: Strategy-Level Motion Planning Based on A Multi-Head Diffusion Model
Aug 23, 2025Recent advances in motion planning for autonomous driving have led to models capable of generating high-quality trajectories. However, most existing planners tend to fix their policy after supervised training, leading to consistent but rigid driving behaviors. This limits their ability to reflect human preferences or adapt to dynamic, instruction-driven demands. In this work, we propose a diffusion-based multi-head trajectory planner(M-diffusion planner). During the early training stage, all output heads share weights to learn to generate high-quality trajectories. Leveraging the probabilistic nature of diffusion models, we then apply Group Relative Policy Optimization (GRPO) to fine-tune the pre-trained model for diverse policy-specific behaviors. At inference time, we incorporate a large language model (LLM) to guide strategy selection, enabling dynamic, instruction-aware planning without switching models. Closed-loop simulation demonstrates that our post-trained planner retains strong planning capability while achieving state-of-the-art (SOTA) performance on the nuPlan val14 benchmark. Open-loop results further show that the generated trajectories exhibit clear diversity, effectively satisfying multi-modal driving behavior requirements. The code and related experiments will be released upon acceptance of the paper.
SenseRAG: Constructing Environmental Knowledge Bases with Proactive Querying for LLM-Based Autonomous Driving
Jan 08, 2025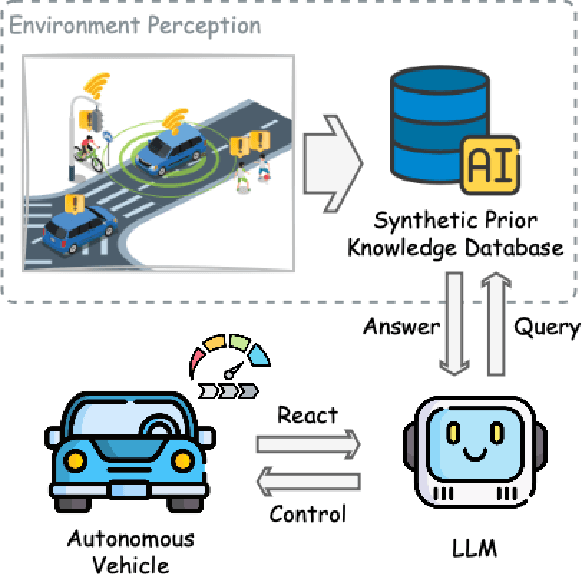
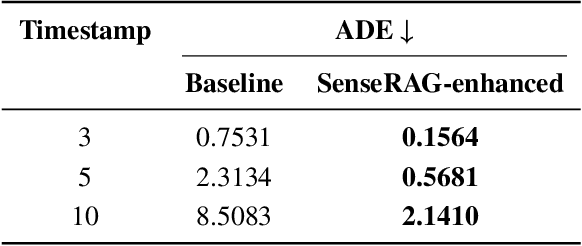
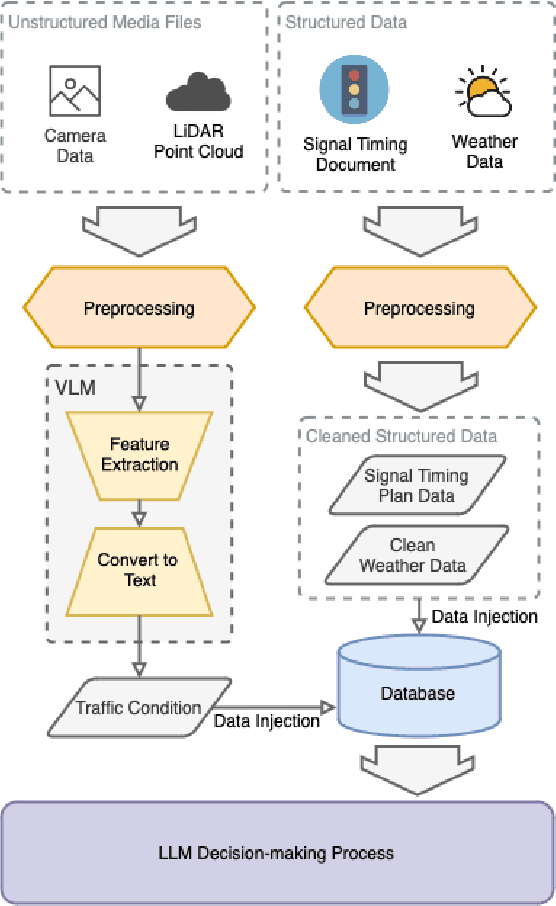
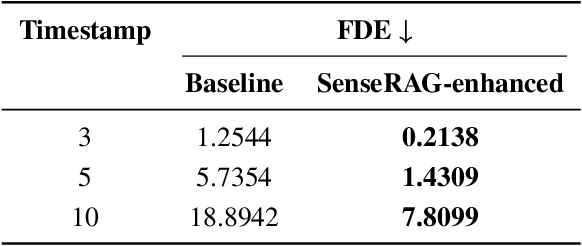
This study addresses the critical need for enhanced situational awareness in autonomous driving (AD) by leveraging the contextual reasoning capabilities of large language models (LLMs). Unlike traditional perception systems that rely on rigid, label-based annotations, it integrates real-time, multimodal sensor data into a unified, LLMs-readable knowledge base, enabling LLMs to dynamically understand and respond to complex driving environments. To overcome the inherent latency and modality limitations of LLMs, a proactive Retrieval-Augmented Generation (RAG) is designed for AD, combined with a chain-of-thought prompting mechanism, ensuring rapid and context-rich understanding. Experimental results using real-world Vehicle-to-everything (V2X) datasets demonstrate significant improvements in perception and prediction performance, highlighting the potential of this framework to enhance safety, adaptability, and decision-making in next-generation AD systems.
ST-HCSS: Deep Spatio-Temporal Hypergraph Convolutional Neural Network for Soft Sensing
Jan 02, 2025
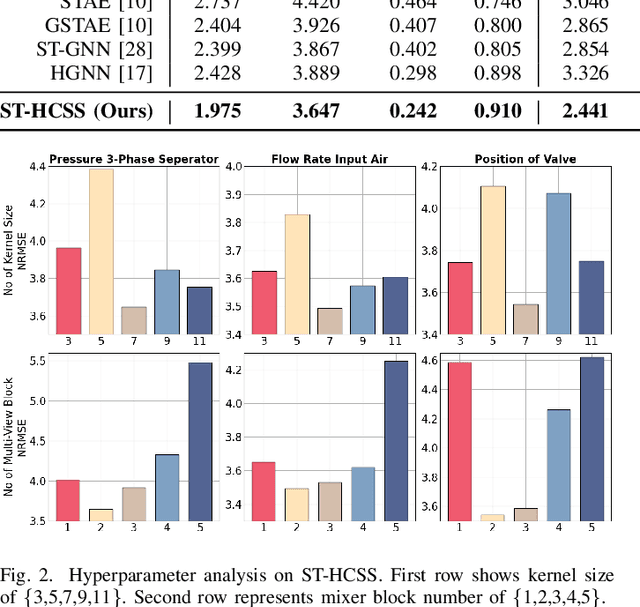


Higher-order sensor networks are more accurate in characterizing the nonlinear dynamics of sensory time-series data in modern industrial settings by allowing multi-node connections beyond simple pairwise graph edges. In light of this, we propose a deep spatio-temporal hypergraph convolutional neural network for soft sensing (ST-HCSS). In particular, our proposed framework is able to construct and leverage a higher-order graph (hypergraph) to model the complex multi-interactions between sensor nodes in the absence of prior structural knowledge. To capture rich spatio-temporal relationships underlying sensor data, our proposed ST-HCSS incorporates stacked gated temporal and hypergraph convolution layers to effectively aggregate and update hypergraph information across time and nodes. Our results validate the superiority of ST-HCSS compared to existing state-of-the-art soft sensors, and demonstrates that the learned hypergraph feature representations aligns well with the sensor data correlations. The code is available at https://github.com/htew0001/ST-HCSS.git
KANS: Knowledge Discovery Graph Attention Network for Soft Sensing in Multivariate Industrial Processes
Jan 02, 2025



Soft sensing of hard-to-measure variables is often crucial in industrial processes. Current practices rely heavily on conventional modeling techniques that show success in improving accuracy. However, they overlook the non-linear nature, dynamics characteristics, and non-Euclidean dependencies between complex process variables. To tackle these challenges, we present a framework known as a Knowledge discovery graph Attention Network for effective Soft sensing (KANS). Unlike the existing deep learning soft sensor models, KANS can discover the intrinsic correlations and irregular relationships between the multivariate industrial processes without a predefined topology. First, an unsupervised graph structure learning method is introduced, incorporating the cosine similarity between different sensor embedding to capture the correlations between sensors. Next, we present a graph attention-based representation learning that can compute the multivariate data parallelly to enhance the model in learning complex sensor nodes and edges. To fully explore KANS, knowledge discovery analysis has also been conducted to demonstrate the interpretability of the model. Experimental results demonstrate that KANS significantly outperforms all the baselines and state-of-the-art methods in soft sensing performance. Furthermore, the analysis shows that KANS can find sensors closely related to different process variables without domain knowledge, significantly improving soft sensing accuracy.
PKRD-CoT: A Unified Chain-of-thought Prompting for Multi-Modal Large Language Models in Autonomous Driving
Dec 02, 2024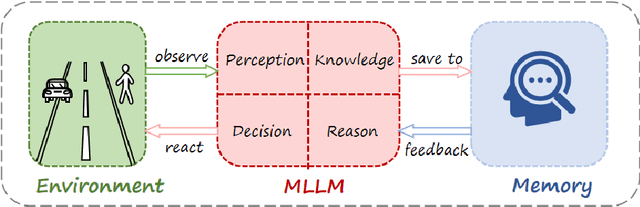


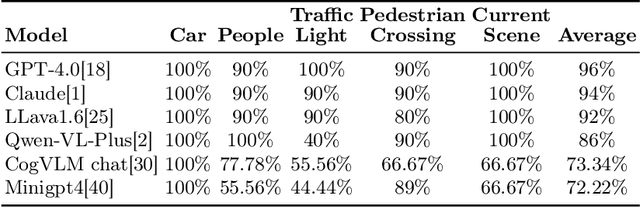
There is growing interest in leveraging the capabilities of robust Multi-Modal Large Language Models (MLLMs) directly within autonomous driving contexts. However, the high costs and complexity of designing and training end-to-end autonomous driving models make them challenging for many enterprises and research entities. To address this, our study explores a seamless integration of MLLMs into autonomous driving systems by proposing a Zero-Shot Chain-of-Thought (Zero-Shot-CoT) prompt design named PKRD-CoT. PKRD-CoT is based on the four fundamental capabilities of autonomous driving: perception, knowledge, reasoning, and decision-making. This makes it particularly suitable for understanding and responding to dynamic driving environments by mimicking human thought processes step by step, thus enhancing decision-making in real-time scenarios. Our design enables MLLMs to tackle problems without prior experience, thereby increasing their utility within unstructured autonomous driving environments. In experiments, we demonstrate the exceptional performance of GPT-4.0 with PKRD-CoT across autonomous driving tasks, highlighting its effectiveness in autonomous driving scenarios. Additionally, our benchmark analysis reveals the promising viability of PKRD-CoT for other MLLMs, such as Claude, LLava1.6, and Qwen-VL-Plus. Overall, this study contributes a novel and unified prompt-design framework for GPT-4.0 and other MLLMs in autonomous driving, while also rigorously evaluating the efficacy of these widely recognized MLLMs in the autonomous driving domain through comprehensive comparisons.
Cross-Domain Transfer Learning using Attention Latent Features for Multi-Agent Trajectory Prediction
Nov 12, 2024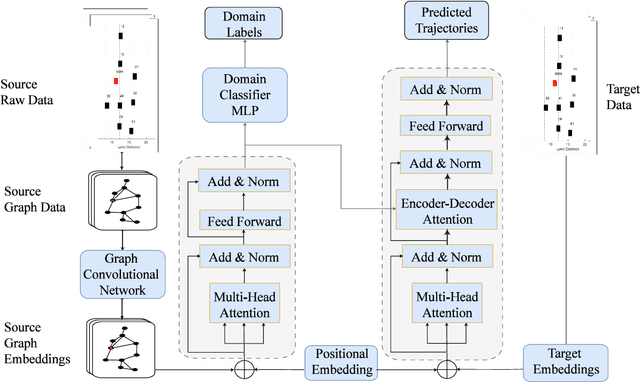
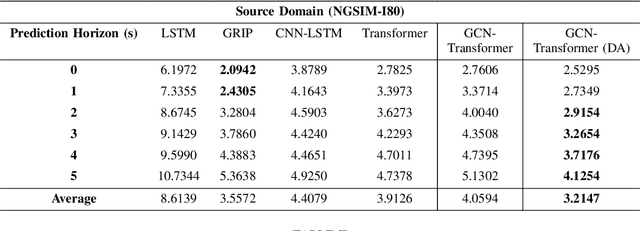
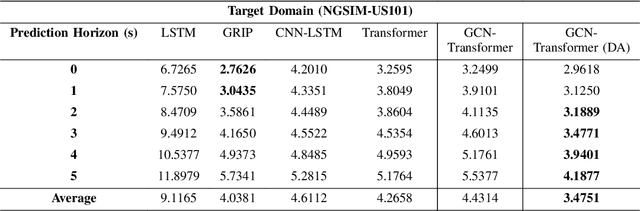
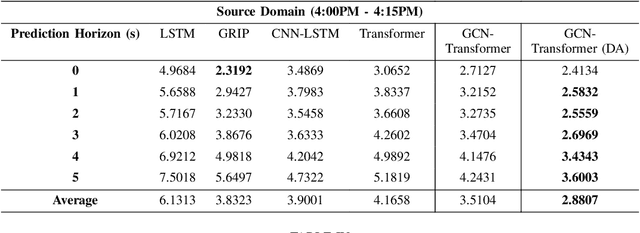
With the advancements of sensor hardware, traffic infrastructure and deep learning architectures, trajectory prediction of vehicles has established a solid foundation in intelligent transportation systems. However, existing solutions are often tailored to specific traffic networks at particular time periods. Consequently, deep learning models trained on one network may struggle to generalize effectively to unseen networks. To address this, we proposed a novel spatial-temporal trajectory prediction framework that performs cross-domain adaption on the attention representation of a Transformer-based model. A graph convolutional network is also integrated to construct dynamic graph feature embeddings that accurately model the complex spatial-temporal interactions between the multi-agent vehicles across multiple traffic domains. The proposed framework is validated on two case studies involving the cross-city and cross-period settings. Experimental results show that our proposed framework achieves superior trajectory prediction and domain adaptation performances over the state-of-the-art models.
Energy-efficient Hybrid Model Predictive Trajectory Planning for Autonomous Electric Vehicles
Nov 09, 2024To tackle the twin challenges of limited battery life and lengthy charging durations in electric vehicles (EVs), this paper introduces an Energy-efficient Hybrid Model Predictive Planner (EHMPP), which employs an energy-saving optimization strategy. EHMPP focuses on refining the design of the motion planner to be seamlessly integrated with the existing automatic driving algorithms, without additional hardware. It has been validated through simulation experiments on the Prescan, CarSim, and Matlab platforms, demonstrating that it can increase passive recovery energy by 11.74\% and effectively track motor speed and acceleration at optimal power. To sum up, EHMPP not only aids in trajectory planning but also significantly boosts energy efficiency in autonomous EVs.
Configuration-Aware Safe Control for Mobile Robotic Arm with Control Barrier Functions
Apr 18, 2022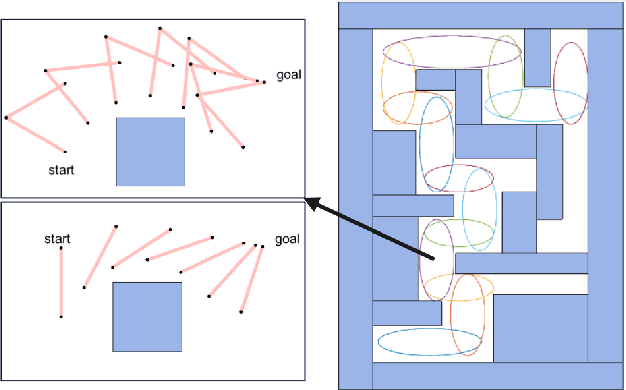
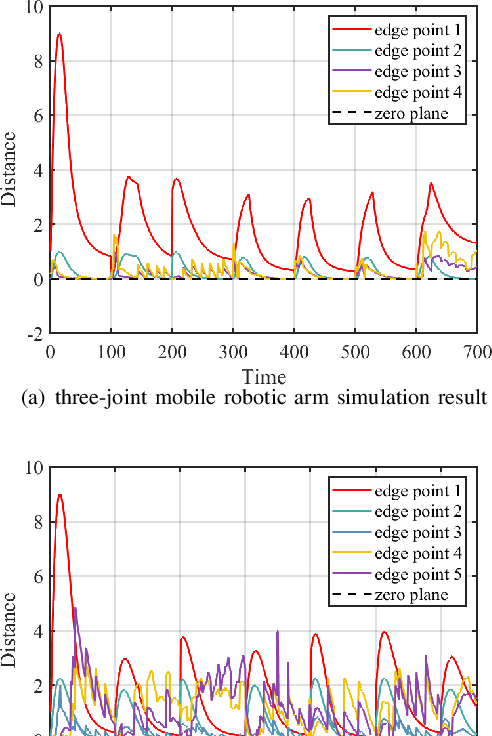
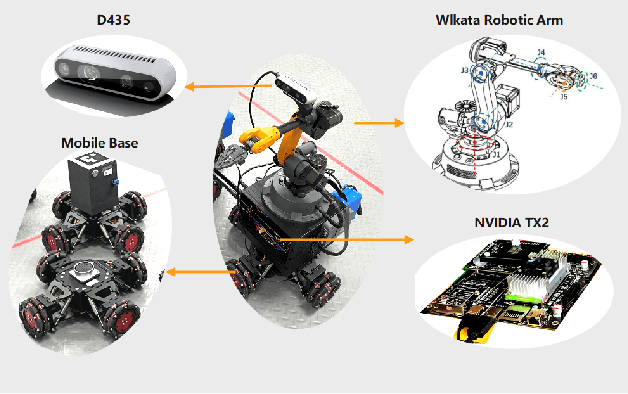
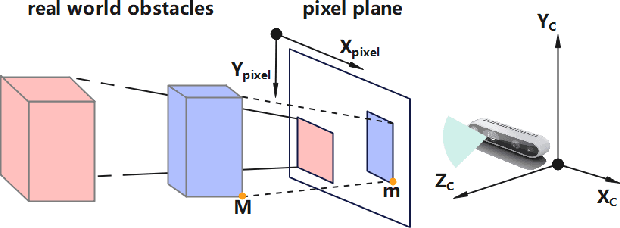
Collision avoidance is a widely investigated topic in robotic applications. When applying collision avoidance techniques to a mobile robot, how to deal with the spatial structure of the robot still remains a challenge. In this paper, we design a configuration-aware safe control law by solving a Quadratic Programming (QP) with designed Control Barrier Functions (CBFs) constraints, which can safely navigate a mobile robotic arm to a desired region while avoiding collision with environmental obstacles. The advantage of our approach is that it correctly and in an elegant way incorporates the spatial structure of the mobile robotic arm. This is achieved by merging geometric restrictions among mobile robotic arm links into CBFs constraints. Simulations on a rigid rod and the modeled mobile robotic arm are performed to verify the feasibility and time-efficiency of proposed method. Numerical results about the time consuming for different degrees of freedom illustrate that our method scales well with dimension.