 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-HCSS: Deep Spatio-Temporal Hypergraph Convolutional Neural Network for Soft Sensing
Jan 02, 2025Higher-order sensor networks are more accurate in characterizing the nonlinear dynamics of sensory time-series data in modern industrial settings by allowing multi-node connections beyond simple pairwise graph edges. In light of this, we propose a deep spatio-temporal hypergraph convolutional neural network for soft sensing (ST-HCSS). In particular, our proposed framework is able to construct and leverage a higher-order graph (hypergraph) to model the complex multi-interactions between sensor nodes in the absence of prior structural knowledge. To capture rich spatio-temporal relationships underlying sensor data, our proposed ST-HCSS incorporates stacked gated temporal and hypergraph convolution layers to effectively aggregate and update hypergraph information across time and nodes. Our results validate the superiority of ST-HCSS compared to existing state-of-the-art soft sensors, and demonstrates that the learned hypergraph feature representations aligns well with the sensor data correlations. The code is available at https://github.com/htew0001/ST-HCSS.git
KANS: Knowledge Discovery Graph Attention Network for Soft Sensing in Multivariate Industrial Processes
Jan 02, 2025



Soft sensing of hard-to-measure variables is often crucial in industrial processes. Current practices rely heavily on conventional modeling techniques that show success in improving accuracy. However, they overlook the non-linear nature, dynamics characteristics, and non-Euclidean dependencies between complex process variables. To tackle these challenges, we present a framework known as a Knowledge discovery graph Attention Network for effective Soft sensing (KANS). Unlike the existing deep learning soft sensor models, KANS can discover the intrinsic correlations and irregular relationships between the multivariate industrial processes without a predefined topology. First, an unsupervised graph structure learning method is introduced, incorporating the cosine similarity between different sensor embedding to capture the correlations between sensors. Next, we present a graph attention-based representation learning that can compute the multivariate data parallelly to enhance the model in learning complex sensor nodes and edges. To fully explore KANS, knowledge discovery analysis has also been conducted to demonstrate the interpretability of the model. Experimental results demonstrate that KANS significantly outperforms all the baselines and state-of-the-art methods in soft sensing performance. Furthermore, the analysis shows that KANS can find sensors closely related to different process variables without domain knowledge, significantly improving soft sensing accuracy.
Energy-efficient Hybrid Model Predictive Trajectory Planning for Autonomous Electric Vehicles
Nov 09, 2024To tackle the twin challenges of limited battery life and lengthy charging durations in electric vehicles (EVs), this paper introduces an Energy-efficient Hybrid Model Predictive Planner (EHMPP), which employs an energy-saving optimization strategy. EHMPP focuses on refining the design of the motion planner to be seamlessly integrated with the existing automatic driving algorithms, without additional hardware. It has been validated through simulation experiments on the Prescan, CarSim, and Matlab platforms, demonstrating that it can increase passive recovery energy by 11.74\% and effectively track motor speed and acceleration at optimal power. To sum up, EHMPP not only aids in trajectory planning but also significantly boosts energy efficiency in autonomous EVs.
FedBChain: A Blockchain-enabled Federated Learning Framework for Improving DeepConvLSTM with Comparative Strategy Insights
Jul 31, 2024


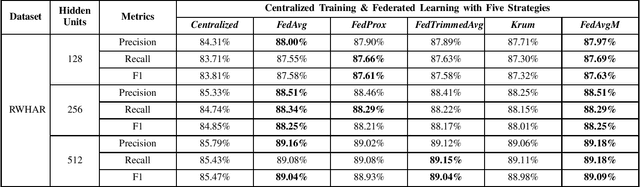
Recent research in the field of Human Activity Recognition has shown that an improvement in prediction performance can be achieved by reducing the number of LSTM layers. However, this kind of enhancement is only significant on monolithic architectures, and when it runs on large-scale distributed training, data security and privacy issues will be reconsidered, and its prediction performance is unknown. In this paper, we introduce a novel framework: FedBChain, which integrates the federated learning paradigm based on a modified DeepConvLSTM architecture with a single LSTM layer. This framework performs comparative tests of prediction performance on three different real-world datasets based on three different hidden layer units (128, 256, and 512) combined with five different federated learning strategies, respectively. The results show that our architecture has significant improvements in Precision, Recall and F1-score compared to the centralized training approach on all datasets with all hidden layer units for all strategies: FedAvg strategy improves on average by 4.54%, FedProx improves on average by 4.57%, FedTrimmedAvg improves on average by 4.35%, Krum improves by 4.18% on average, and FedAvgM improves by 4.46% on average. Based on our results, it can be seen that FedBChain not only improves in performance, but also guarantees the security and privacy of user data compared to centralized training methods during the training process. The code for our experiments is publicly available (https://github.com/Glen909/FedBChain).