 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnGAP: Uncertainty-Guided Affine Prompting for Real-Time Crack Segmentation
May 04, 2026Real-time crack segmentation is vital for structural health monitoring but is plagued by aleatoric uncertainties arising from varying lighting, blur, and texture ambiguity. Current uncertainty-aware approaches typically treat uncertainty estimation as a passive endpoint for post-hoc analysis, failing to close the loop by feeding this information back to refine feature representations. We contend that independent pixel-wise heteroscedastic modeling is uniquely suited for crack segmentation, as cracks are defined by fine-grained local gradients rather than the global semantic coherence relied upon in general object segmentation. However, this approach suffers from a structural optimization pathology: high predicted variance attenuates loss gradients, effectively causing the model to ignore difficult samples and under-fit complex boundaries. To address these challenges, we propose UnGAP, a novel framework that establishes a closed-loop mechanism between uncertainty estimation and feature learning. Central to our approach is the Uncertainty-Prompted Feature Modulator (UPFM), which treats aleatoric uncertainty as an active visual prompt rather than a mere output. UPFM dynamically calibrates feature distributions through pixel-wise affine transformations. Crucially, this mechanism mitigates the heteroscedastic pathology by transforming high variance, which would otherwise indicate gradient suppression, into a constructive signal for stronger feature rectification in ambiguous regions. Additionally, a boundary-aware detection head is introduced to further constrain prediction precision. Extensive experiments demonstrate that UnGAP balances superior segmentation accuracy with real-time inference speed, effectively validating the benefit of transforming uncertainty from a passive metric into an active calibration tool.
MCA: 2D-3D Retrieval with Noisy Labels via Multi-level Adaptive Correction and Alignment
Aug 08, 2025With the increasing availability of 2D and 3D data, significant advancements have been made in the field of cross-modal retrieval. Nevertheless, the existence of imperfect annotations presents considerable challenges, demanding robust solutions for 2D-3D cross-modal retrieval in the presence of noisy label conditions. Existing methods generally address the issue of noise by dividing samples independently within each modality, making them susceptible to overfitting on corrupted labels. To address these issues, we propose a robust 2D-3D \textbf{M}ulti-level cross-modal adaptive \textbf{C}orrection and \textbf{A}lignment framework (MCA). Specifically, we introduce a Multimodal Joint label Correction (MJC) mechanism that leverages multimodal historical self-predictions to jointly model the modality prediction consistency, enabling reliable label refinement. Additionally, we propose a Multi-level Adaptive Alignment (MAA) strategy to effectively enhance cross-modal feature semantics and discrimination across different levels. Extensive experiments demonstrate the superiority of our method, MCA, which achieves state-of-the-art performance on both conventional and realistic noisy 3D benchmarks, highlighting its generality and effectiveness.
Baitradar: A Multi-Model Clickbait Detection Algorithm Using Deep Learning
May 23, 2025Following the rising popularity of YouTube, there is an emerging problem on this platform called clickbait, which provokes users to click on videos using attractive titles and thumbnails. As a result, users ended up watching a video that does not have the content as publicized in the title. This issue is addressed in this study by proposing an algorithm called BaitRadar, which uses a deep learning technique where six inference models are jointly consulted to make the final classification decision. These models focus on different attributes of the video, including title, comments, thumbnail, tags, video statistics and audio transcript. The final classification is attained by computing the average of multiple models to provide a robust and accurate output even in situation where there is missing data. The proposed method is tested on 1,400 YouTube videos. On average, a test accuracy of 98% is achieved with an inference time of less than 2s.
CSTA: Spatial-Temporal Causal Adaptive Learning for Exemplar-Free Video Class-Incremental Learning
Jan 13, 2025



Continual learning aims to acquire new knowledge while retaining past information. Class-incremental learning (CIL) presents a challenging scenario where classes are introduced sequentially. For video data, the task becomes more complex than image data because it requires learning and preserving both spatial appearance and temporal action involvement. To address this challenge, we propose a novel exemplar-free framework that equips separate spatiotemporal adapters to learn new class patterns, accommodating the incremental information representation requirements unique to each class. While separate adapters are proven to mitigate forgetting and fit unique requirements, naively applying them hinders the intrinsic connection between spatial and temporal information increments, affecting the efficiency of representing newly learned class information. Motivated by this, we introduce two key innovations from a causal perspective. First, a causal distillation module is devised to maintain the relation between spatial-temporal knowledge for a more efficient representation. Second, a causal compensation mechanism is proposed to reduce the conflicts during increment and memorization between different types of information. Extensive experiments conducted on benchmark datasets demonstrate that our framework can achieve new state-of-the-art results, surpassing current example-based methods by 4.2% in accuracy on average.
FedBChain: A Blockchain-enabled Federated Learning Framework for Improving DeepConvLSTM with Comparative Strategy Insights
Jul 31, 2024


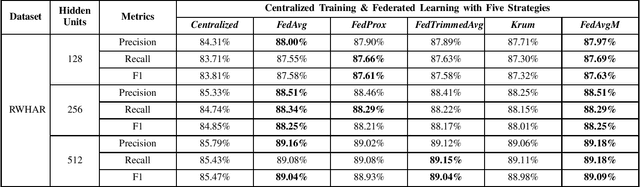
Recent research in the field of Human Activity Recognition has shown that an improvement in prediction performance can be achieved by reducing the number of LSTM layers. However, this kind of enhancement is only significant on monolithic architectures, and when it runs on large-scale distributed training, data security and privacy issues will be reconsidered, and its prediction performance is unknown. In this paper, we introduce a novel framework: FedBChain, which integrates the federated learning paradigm based on a modified DeepConvLSTM architecture with a single LSTM layer. This framework performs comparative tests of prediction performance on three different real-world datasets based on three different hidden layer units (128, 256, and 512) combined with five different federated learning strategies, respectively. The results show that our architecture has significant improvements in Precision, Recall and F1-score compared to the centralized training approach on all datasets with all hidden layer units for all strategies: FedAvg strategy improves on average by 4.54%, FedProx improves on average by 4.57%, FedTrimmedAvg improves on average by 4.35%, Krum improves by 4.18% on average, and FedAvgM improves by 4.46% on average. Based on our results, it can be seen that FedBChain not only improves in performance, but also guarantees the security and privacy of user data compared to centralized training methods during the training process. The code for our experiments is publicly available (https://github.com/Glen909/FedBChain).
Feasibility of Neural Radiance Fields for Crime Scene Video Reconstruction
Jul 11, 2024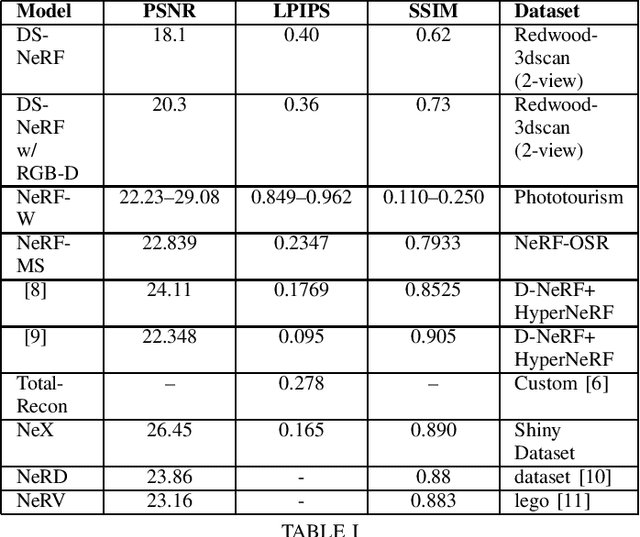
This paper aims to review and determine the feasibility of using variations of NeRF models in order to reconstruct crime scenes given input videos of the scene. We focus on three main innovations of NeRF when it comes to reconstructing crime scenes: Multi-object Synthesis, Deformable Synthesis, and Lighting. From there, we analyse its innovation progress against the requirements to be met in order to be able to reconstruct crime scenes with given videos of such scenes.
Transferable Class-Modelling for Decentralized Source Attribution of GAN-Generated Images
Mar 18, 2022
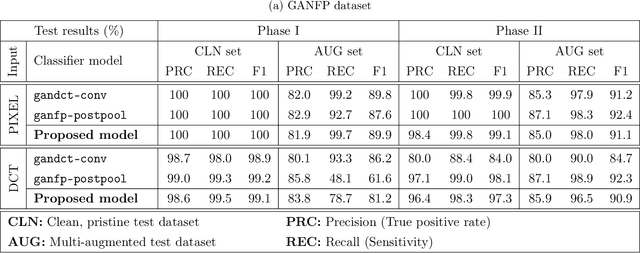
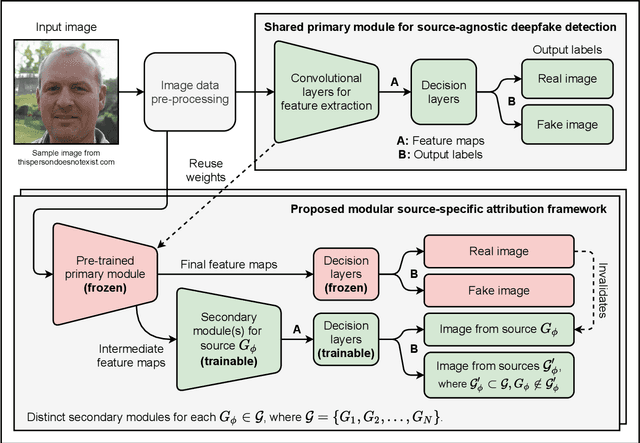
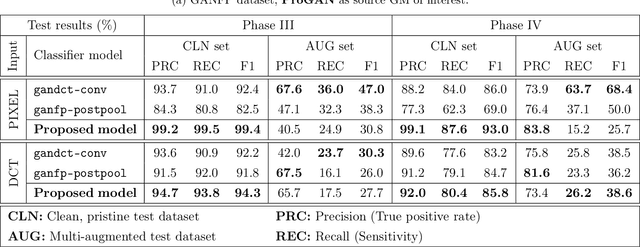
GAN-generated deepfakes as a genre of digital images are gaining ground as both catalysts of artistic expression and malicious forms of deception, therefore demanding systems to enforce and accredit their ethical use. Existing techniques for the source attribution of synthetic images identify subtle intrinsic fingerprints using multiclass classification neural nets limited in functionality and scalability. Hence, we redefine the deepfake detection and source attribution problems as a series of related binary classification tasks. We leverage transfer learning to rapidly adapt forgery detection networks for multiple independent attribution problems, by proposing a semi-decentralized modular design to solve them simultaneously and efficiently. Class activation mapping is also demonstrated as an effective means of feature localization for model interpretation. Our models are determined via experimentation to be competitive with current benchmarks, and capable of decent performance on human portraits in ideal conditions. Decentralized fingerprint-based attribution is found to retain validity in the presence of novel sources, but is more susceptible to type II errors that intensify with image perturbations and attributive uncertainty. We describe both our conceptual framework and model prototypes for further enhancement when investigating the technical limits of reactive deepfake attribution.
Fuzzy human motion analysis: A review
Dec 02, 2014

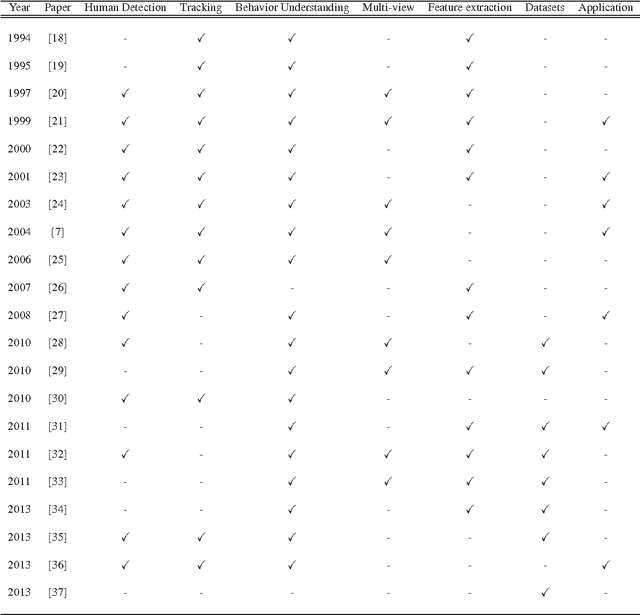
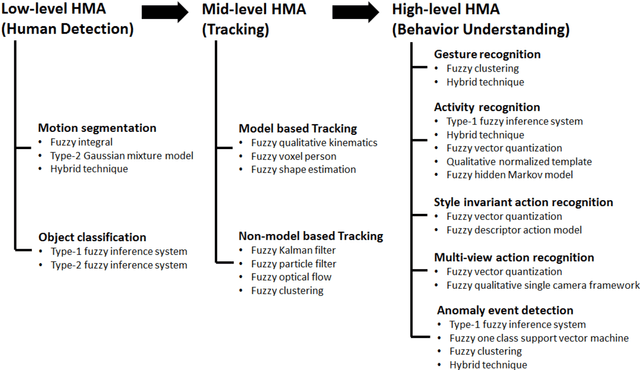
Human Motion Analysis (HMA) is currently one of the most popularly active research domains as such significant research interests are motivated by a number of real world applications such as video surveillance, sports analysis, healthcare monitoring and so on. However, most of these real world applications face high levels of uncertainties that can affect the operations of such applications. Hence, the fuzzy set theory has been applied and showed great success in the recent past. In this paper, we aim at reviewing the fuzzy set oriented approaches for HMA, individuating how the fuzzy set may improve the HMA, envisaging and delineating the future perspectives. To the best of our knowledge, there is not found a single survey in the current literature that has discussed and reviewed fuzzy approaches towards the HMA. For ease of understanding, we conceptually classify the human motion into three broad levels: Low-Level (LoL), Mid-Level (MiL), and High-Level (HiL) HMA.
* Accepted in Pattern Recognition, first survey paper that discusses and reviews fuzzy approaches towards HMA
Scene Image is Non-Mutually Exclusive - A Fuzzy Qualitative Scene Understanding
Oct 14, 2014



Ambiguity or uncertainty is a pervasive element of many real world decision making processes. Variation in decisions is a norm in this situation when the same problem is posed to different subjects. Psychological and metaphysical research had proven that decision making by human is subjective. It is influenced by many factors such as experience, age, background, etc. Scene understanding is one of the computer vision problems that fall into this category. Conventional methods relax this problem by assuming scene images are mutually exclusive; and therefore, focus on developing different approaches to perform the binary classification tasks. In this paper, we show that scene images are non-mutually exclusive, and propose the Fuzzy Qualitative Rank Classifier (FQRC) to tackle the aforementioned problems. The proposed FQRC provides a ranking interpretation instead of binary decision. Evaluations in term of qualitative and quantitative using large numbers and challenging public scene datasets have shown the effectiveness of our proposed method in modeling the non-mutually exclusive scene images.
* Accepted in IEEE Transactions on Fuzzy Systems