 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFE-GAN: Efficient GAN-based Framework for Document Image Enhancement and Binarization with Multi-scale Feature Extraction
Dec 16, 2025



Document image enhancement and binarization are commonly performed prior to document analysis and recognition tasks for improving the efficiency and accuracy of optical character recognition (OCR) systems. This is because directly recognizing text in degraded documents, particularly in color images, often results in unsatisfactory recognition performance. To address these issues, existing methods train independent generative adversarial networks (GANs) for different color channels to remove shadows and noise, which, in turn, facilitates efficient text information extraction. However, deploying multiple GANs results in long training and inference times. To reduce both training and inference times of document image enhancement and binarization models, we propose MFE-GAN, an efficient GAN-based framework with multi-scale feature extraction (MFE), which incorporates Haar wavelet transformation (HWT) and normalization to process document images before feeding them into GANs for training. In addition, we present novel generators, discriminators, and loss functions to improve the model's performance, and we conduct ablation studies to demonstrate their effectiveness. Experimental results on the Benchmark, Nabuco, and CMATERdb datasets demonstrate that the proposed MFE-GAN significantly reduces the total training and inference times while maintaining comparable performance with respect to state-of-the-art (SOTA) methods. The implementation of this work is available at https://ruiyangju.github.io/MFE-GAN.
Baitradar: A Multi-Model Clickbait Detection Algorithm Using Deep Learning
May 23, 2025Following the rising popularity of YouTube, there is an emerging problem on this platform called clickbait, which provokes users to click on videos using attractive titles and thumbnails. As a result, users ended up watching a video that does not have the content as publicized in the title. This issue is addressed in this study by proposing an algorithm called BaitRadar, which uses a deep learning technique where six inference models are jointly consulted to make the final classification decision. These models focus on different attributes of the video, including title, comments, thumbnail, tags, video statistics and audio transcript. The final classification is attained by computing the average of multiple models to provide a robust and accurate output even in situation where there is missing data. The proposed method is tested on 1,400 YouTube videos. On average, a test accuracy of 98% is achieved with an inference time of less than 2s.
Efficient GANs for Document Image Binarization Based on DWT and Normalization
Jul 05, 2024



For document image binarization task, generative adversarial networks (GANs) can generate images where shadows and noise are effectively removed, which allow for text information extraction. The current state-of-the-art (SOTA) method proposes a three-stage network architecture that utilizes six GANs. Despite its excellent model performance, the SOTA network architecture requires long training and inference times. To overcome this problem, this work introduces an efficient GAN method based on the three-stage network architecture that incorporates the Discrete Wavelet Transformation and normalization to reduce the input image size, which in turns, decrease both training and inference times. In addition, this work presents novel generators, discriminators, and loss functions to improve the model's performance. Experimental results show that the proposed method reduces the training time by 10% and the inference time by 26% when compared to the SOTA method while maintaining the model performance at 73.79 of Avg-Score. Our implementation code is available on GitHub at https://github.com/RuiyangJu/Efficient_Document_Image_Binarization.
GTA-HDR: A Large-Scale Synthetic Dataset for HDR Image Reconstruction
Mar 26, 2024



High Dynamic Range (HDR) content (i.e., images and videos) has a broad range of applications. However, capturing HDR content from real-world scenes is expensive and time-consuming. Therefore, the challenging task of reconstructing visually accurate HDR images from their Low Dynamic Range (LDR) counterparts is gaining attention in the vision research community. A major challenge in this research problem is the lack of datasets, which capture diverse scene conditions (e.g., lighting, shadows, weather, locations, landscapes, objects, humans, buildings) and various image features (e.g., color, contrast, saturation, hue, luminance, brightness, radiance). To address this gap, in this paper, we introduce GTA-HDR, a large-scale synthetic dataset of photo-realistic HDR images sampled from the GTA-V video game. We perform thorough evaluation of the proposed dataset, which demonstrates significant qualitative and quantitative improvements of the state-of-the-art HDR image reconstruction methods. Furthermore, we demonstrate the effectiveness of the proposed dataset and its impact on additional computer vision tasks including 3D human pose estimation, human body part segmentation, and holistic scene segmentation. The dataset, data collection pipeline, and evaluation code are available at: https://github.com/HrishavBakulBarua/GTA-HDR.
HistoHDR-Net: Histogram Equalization for Single LDR to HDR Image Translation
Feb 08, 2024



High Dynamic Range (HDR) imaging aims to replicate the high visual quality and clarity of real-world scenes. Due to the high costs associated with HDR imaging, the literature offers various data-driven methods for HDR image reconstruction from Low Dynamic Range (LDR) counterparts. A common limitation of these approaches is missing details in regions of the reconstructed HDR images, which are over- or under-exposed in the input LDR images. To this end, we propose a simple and effective method, HistoHDR-Net, to recover the fine details (e.g., color, contrast, saturation, and brightness) of HDR images via a fusion-based approach utilizing histogram-equalized LDR images along with self-attention guidance. Our experiments demonstrate the efficacy of the proposed approach over the state-of-art methods.
ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation
Sep 07, 2023



High Dynamic Range (HDR) content creation has become an important topic for modern media and entertainment sectors, gaming and Augmented/Virtual Reality industries. Many methods have been proposed to recreate the HDR counterparts of input Low Dynamic Range (LDR) images/videos given a single exposure or multi-exposure LDRs. The state-of-the-art methods focus primarily on the preservation of the reconstruction's structural similarity and the pixel-wise accuracy. However, these conventional approaches do not emphasize preserving the artistic intent of the images in terms of human visual perception, which is an essential element in media, entertainment and gaming. In this paper, we attempt to study and fill this gap. We propose an architecture called ArtHDR-Net based on a Convolutional Neural Network that uses multi-exposed LDR features as input. Experimental results show that ArtHDR-Net can achieve state-of-the-art performance in terms of the HDR-VDP-2 score (i.e., mean opinion score index) while reaching competitive performance in terms of PSNR and SSIM.
HDR image watermarking using saliency detection and quantization index modulation
Feb 23, 2023High-dynamic range (HDR) images are circulated rapidly over the internet with risks of being exploited for unauthorized usage. To protect these images, some HDR image based watermarking (HDR-IW) methods were put forward. However, they inherited the same problem faced by conventional IW methods for standard dynamic range (SDR) images, where only trade-offs among conflicting requirements are managed instead of simultaneous improvement. In this paper, a novel saliency (eye-catching object) detection based trade-off independent HDR-IW is proposed, to simultaneously improve robustness, imperceptibility and payload. First, the host image goes through our proposed salient object detection model to produce a saliency map, which is, in turn, exploited to segment the foreground and background of the host image. Next, the binary watermark is partitioned into the foregrounds and backgrounds using the same mask and scrambled using a random permutation algorithm. Finally, the watermark segments are embedded into selected bit-plane of the corresponding host segments using quantized indexed modulation. Experimental results suggest that the proposed work outperforms state-of-the-art methods in terms of improving the conflicting requirements.
A Generalized Approach for Cancellable Template and Its Realization for Minutia Cylinder-Code
Mar 02, 2022


Hashing technology gains much attention in protecting the biometric template lately. For instance, Index-of-Max (IoM), a recent reported hashing technique, is a ranking-based locality sensitive hashing technique, which illustrates the feasibility to protect the ordered and fixed-length biometric template. However, biometric templates are not always in the form of ordered and fixed-length, rather it may be an unordered and variable size point set e.g. fingerprint minutiae, which restricts the usage of the traditional hashing technology. In this paper, we proposed a generalized version of IoM hashing namely gIoM, and therefore the unordered and variable size biometric template can be used. We demonstrate a realization using a well-known variable size feature vector, fingerprint Minutia Cylinder-Code (MCC). The gIoM transforms MCC into index domain to form indexing-based feature representation. Consequently, the inversion of MCC from the transformed representation is computational infeasible, thus to achieve non-invertibility while the performance is preserved. Public fingerprint databases FVC2002 and FVC2004 are employed for experiment as benchmark to demonstrate a fair comparison with other methods. Moreover, the security and privacy analysis suggest that gIoM meets the criteria of template protection: non-invertibility, revocability, and non-linkability.
Synthesize-It-Classifier: Learning a Generative Classifier through RecurrentSelf-analysis
Mar 26, 2021
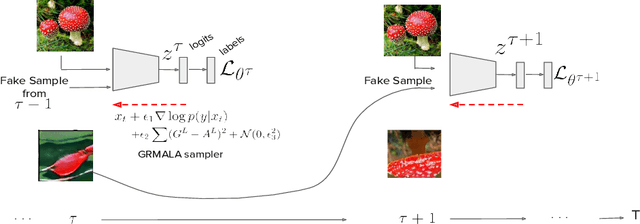


In this work, we show the generative capability of an image classifier network by synthesizing high-resolution, photo-realistic, and diverse images at scale. The overall methodology, called Synthesize-It-Classifier (STIC), does not require an explicit generator network to estimate the density of the data distribution and sample images from that, but instead uses the classifier's knowledge of the boundary to perform gradient ascent w.r.t. class logits and then synthesizes images using Gram Matrix Metropolis Adjusted Langevin Algorithm (GRMALA) by drawing on a blank canvas. During training, the classifier iteratively uses these synthesized images as fake samples and re-estimates the class boundary in a recurrent fashion to improve both the classification accuracy and quality of synthetic images. The STIC shows the mixing of the hard fake samples (i.e. those synthesized by the one hot class conditioning), and the soft fake samples (which are synthesized as a convex combination of classes, i.e. a mixup of classes) improves class interpolation. We demonstrate an Attentive-STIC network that shows an iterative drawing of synthesized images on the ImageNet dataset that has thousands of classes. In addition, we introduce the synthesis using a class conditional score classifier (Score-STIC) instead of a normal image classifier and show improved results on several real-world datasets, i.e. ImageNet, LSUN, and CIFAR 10.
On the Reliability of Cancelable Biometrics: Revisit the Irreversibility
Oct 22, 2019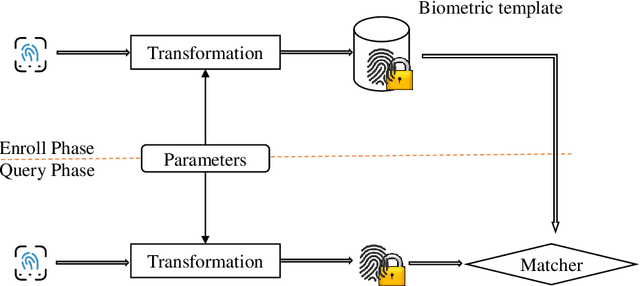
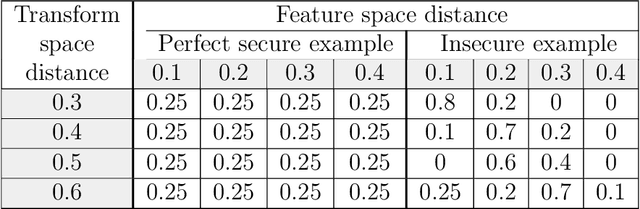
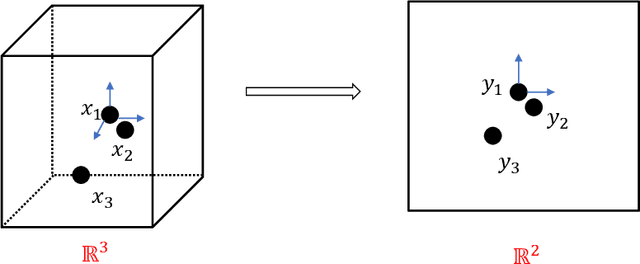
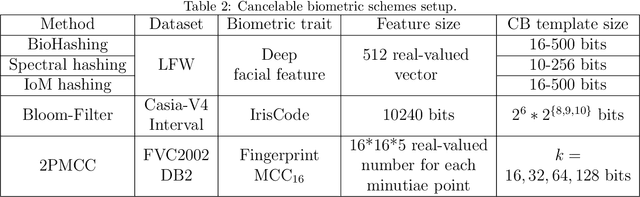
Over the years, many biometric template protection schemes, primarily based on the notion of "cancelable biometrics" have been proposed. A cancelable biometric algorithm needs to satisfy four biometric template protection criteria, i.e., irreversibility, revocability, unlinkability, and performance preservation. However, a systematic analysis of irreversibility has been often neglected. In this paper, the common distance correlation characteristic of cancelable biometrics is analyzed. Next, a similarity-based attack is formulated to break the irreversibility of cancelable biometric under the Kerckhoffs's assumption where the cancelable biometrics algorithm and parameter are known to the attackers. The irreversibility based on the mutual information is also redefined, and a framework to measure the information leakage from the distance correlation characteristic is proposed. The results achieved on face, iris, and fingerprint prove that it is theoretically hard to meet full irreversibility. To have a good biometric system, a balance has to be achieved between accuracy and security.