 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalmBridge: A Plug-and-Play Feature Alignment Framework for Open-Set Palmprint Verification
Jan 28, 2026Palmprint recognition is widely used in biometric systems, yet real-world performance often degrades due to feature distribution shifts caused by heterogeneous deployment conditions. Most deep palmprint models assume a closed and stationary distribution, leading to overfitting to dataset-specific textures rather than learning domain-invariant representations. Although data augmentation is commonly used to mitigate this issue, it assumes augmented samples can approximate the target deployment distribution, an assumption that often fails under significant domain mismatch. To address this limitation, we propose PalmBridge, a plug-and-play feature-space alignment framework for open-set palmprint verification based on vector quantization. Rather than relying solely on data-level augmentation, PalmBridge learns a compact set of representative vectors directly from training features. During enrollment and verification, each feature vector is mapped to its nearest representative vector under a minimum-distance criterion, and the mapped vector is then blended with the original vector. This design suppresses nuisance variation induced by domain shifts while retaining discriminative identity cues. The representative vectors are jointly optimized with the backbone network using task supervision, a feature-consistency objective, and an orthogonality regularization term to form a stable and well-structured shared embedding space. Furthermore, we analyze feature-to-representative mappings via assignment consistency and collision rate to assess model's sensitivity to blending weights. Experiments on multiple palmprint datasets and backbone architectures show that PalmBridge consistently reduces EER in intra-dataset open-set evaluation and improves cross-dataset generalization with negligible to modest runtime overhead.
LURE: Latent Space Unblocking for Multi-Concept Reawakening in Diffusion Models
Jan 20, 2026Concept erasure aims to suppress sensitive content in diffusion models, but recent studies show that erased concepts can still be reawakened, revealing vulnerabilities in erasure methods. Existing reawakening methods mainly rely on prompt-level optimization to manipulate sampling trajectories, neglecting other generative factors, which limits a comprehensive understanding of the underlying dynamics. In this paper, we model the generation process as an implicit function to enable a comprehensive theoretical analysis of multiple factors, including text conditions, model parameters, and latent states. We theoretically show that perturbing each factor can reawaken erased concepts. Building on this insight, we propose a novel concept reawakening method: Latent space Unblocking for concept REawakening (LURE), which reawakens erased concepts by reconstructing the latent space and guiding the sampling trajectory. Specifically, our semantic re-binding mechanism reconstructs the latent space by aligning denoising predictions with target distributions to reestablish severed text-visual associations. However, in multi-concept scenarios, naive reconstruction can cause gradient conflicts and feature entanglement. To address this, we introduce Gradient Field Orthogonalization, which enforces feature orthogonality to prevent mutual interference. Additionally, our Latent Semantic Identification-Guided Sampling (LSIS) ensures stability of the reawakening process via posterior density verification. Extensive experiments demonstrate that LURE enables simultaneous, high-fidelity reawakening of multiple erased concepts across diverse erasure tasks and methods.
Palmprint De-Identification Using Diffusion Model for High-Quality and Diverse Synthesis
Apr 11, 2025



Palmprint recognition techniques have advanced significantly in recent years, enabling reliable recognition even when palmprints are captured in uncontrolled or challenging environments. However, this strength also introduces new risks, as publicly available palmprint images can be misused by adversaries for malicious activities. Despite this growing concern, research on methods to obscure or anonymize palmprints remains largely unexplored. Thus, it is essential to develop a palmprint de-identification technique capable of removing identity-revealing features while retaining the image's utility and preserving non-sensitive information. In this paper, we propose a training-free framework that utilizes pre-trained diffusion models to generate diverse, high-quality palmprint images that conceal identity features for de-identification purposes. To ensure greater stability and controllability in the synthesis process, we incorporate a semantic-guided embedding fusion alongside a prior interpolation mechanism. We further propose the de-identification ratio, a novel metric for intuitive de-identification assessment. Extensive experiments across multiple palmprint datasets and recognition methods demonstrate that our method effectively conceals identity-related traits with significant diversity across de-identified samples. The de-identified samples preserve high visual fidelity and maintain excellent usability, achieving a balance between de-identification and retaining non-identity information.
TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection
Apr 03, 2025



We aim to solve unsupervised anomaly detection in a practical challenging environment where the normal dataset is both contaminated with defective regions and its product class distribution is tailed but unknown. We observe that existing models suffer from tail-versus-noise trade-off where if a model is robust against pixel noise, then its performance deteriorates on tail class samples, and vice versa. To mitigate the issue, we handle the tail class and noise samples independently. To this end, we propose TailSampler, a novel class size predictor that estimates the class cardinality of samples based on a symmetric assumption on the class-wise distribution of embedding similarities. TailSampler can be utilized to sample the tail class samples exclusively, allowing to handle them separately. Based on these facets, we build a memory-based anomaly detection model TailedCore, whose memory both well captures tail class information and is noise-robust. We extensively validate the effectiveness of TailedCore on the unsupervised long-tail noisy anomaly detection setting, and show that TailedCore outperforms the state-of-the-art in most settings.
FedPalm: A General Federated Learning Framework for Closed- and Open-Set Palmprint Verification
Mar 05, 2025



Current deep learning (DL)-based palmprint verification models rely on centralized training with large datasets, which raises significant privacy concerns due to biometric data's sensitive and immutable nature. Federated learning~(FL), a privacy-preserving distributed learning paradigm, offers a compelling alternative by enabling collaborative model training without the need for data sharing. However, FL-based palmprint verification faces critical challenges, including data heterogeneity from diverse identities and the absence of standardized evaluation benchmarks. This paper addresses these gaps by establishing a comprehensive benchmark for FL-based palmprint verification, which explicitly defines and evaluates two practical scenarios: closed-set and open-set verification. We propose FedPalm, a unified FL framework that balances local adaptability with global generalization. Each client trains a personalized textural expert tailored to local data and collaboratively contributes to a shared global textural expert for extracting generalized features. To further enhance verification performance, we introduce a Textural Expert Interaction Module that dynamically routes textural features among experts to generate refined side textural features. Learnable parameters are employed to model relationships between original and side features, fostering cross-texture-expert interaction and improving feature discrimination. Extensive experiments validate the effectiveness of FedPalm, demonstrating robust performance across both scenarios and providing a promising foundation for advancing FL-based palmprint verification research.
Deep Learning in Palmprint Recognition-A Comprehensive Survey
Jan 02, 2025



Palmprint recognition has emerged as a prominent biometric technology, widely applied in diverse scenarios. Traditional handcrafted methods for palmprint recognition often fall short in representation capability, as they heavily depend on researchers' prior knowledge. Deep learning (DL) has been introduced to address this limitation, leveraging its remarkable successes across various domains. While existing surveys focus narrowly on specific tasks within palmprint recognition-often grounded in traditional methodologies-there remains a significant gap in comprehensive research exploring DL-based approaches across all facets of palmprint recognition. This paper bridges that gap by thoroughly reviewing recent advancements in DL-powered palmprint recognition. The paper systematically examines progress across key tasks, including region-of-interest segmentation, feature extraction, and security/privacy-oriented challenges. Beyond highlighting these advancements, the paper identifies current challenges and uncovers promising opportunities for future research. By consolidating state-of-the-art progress, this review serves as a valuable resource for researchers, enabling them to stay abreast of cutting-edge technologies and drive innovation in palmprint recognition.
Face Reconstruction Transfer Attack as Out-of-Distribution Generalization
Jul 02, 2024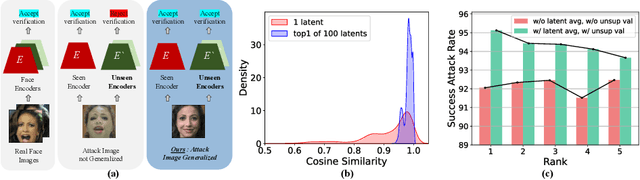
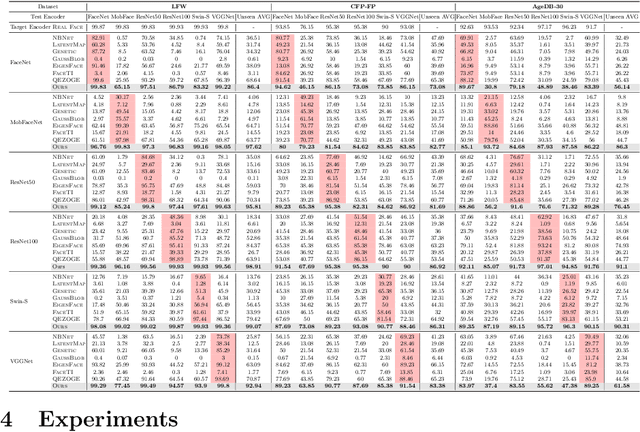
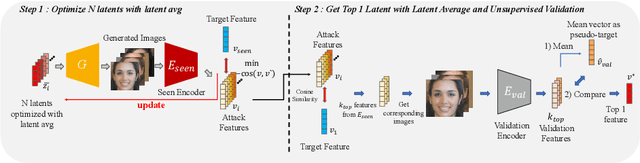
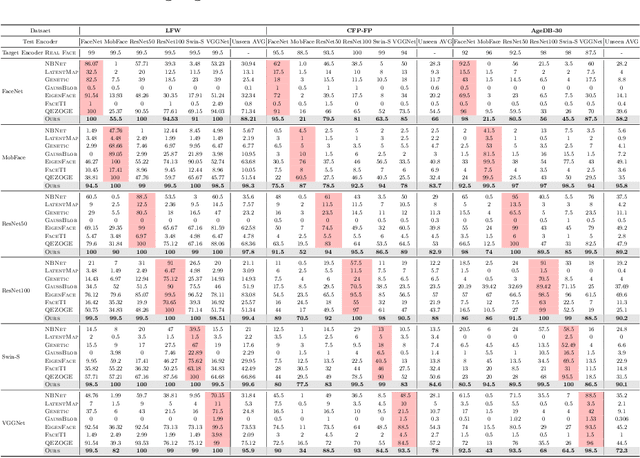
Understanding the vulnerability of face recognition systems to malicious attacks is of critical importance. Previous works have focused on reconstructing face images that can penetrate a targeted verification system. Even in the white-box scenario, however, naively reconstructed images misrepresent the identity information, hence the attacks are easily neutralized once the face system is updated or changed. In this paper, we aim to reconstruct face images which are capable of transferring face attacks on unseen encoders. We term this problem as Face Reconstruction Transfer Attack (FRTA) and show that it can be formulated as an out-of-distribution (OOD) generalization problem. Inspired by its OOD nature, we propose to solve FRTA by Averaged Latent Search and Unsupervised Validation with pseudo target (ALSUV). To strengthen the reconstruction attack on OOD unseen encoders, ALSUV reconstructs the face by searching the latent of amortized generator StyleGAN2 through multiple latent optimization, latent optimization trajectory averaging, and unsupervised validation with a pseudo target. We demonstrate the efficacy and generalization of our method on widely used face datasets, accompanying it with extensive ablation studies and visually, qualitatively, and quantitatively analyses. The source code will be released.
Beyond First-Order: A Multi-Scale Approach to Finger Knuckle Print Biometrics
Jun 28, 2024Recently, finger knuckle prints (FKPs) have gained attention due to their rich textural patterns, positioning them as a promising biometric for identity recognition. Prior FKP recognition methods predominantly leverage first-order feature descriptors, which capture intricate texture details but fail to account for structural information. Emerging research, however, indicates that second-order textures, which describe the curves and arcs of the textures, encompass this overlooked structural information. This paper introduces a novel FKP recognition approach, the Dual-Order Texture Competition Network (DOTCNet), designed to capture texture information in FKP images comprehensively. DOTCNet incorporates three dual-order texture competitive modules (DTCMs), each targeting textures at different scales. Each DTCM employs a learnable texture descriptor, specifically a learnable Gabor filter (LGF), to extract texture features. By leveraging LGFs, the network extracts first and second order textures to describe fine textures and structural features thoroughly. Furthermore, an attention mechanism enhances relevant features in the first-order features, thereby highlighting significant texture details. For second-order features, a competitive mechanism emphasizes structural information while reducing noise from higher-order features. Extensive experimental results reveal that DOTCNet significantly outperforms several standard algorithms on the publicly available PolyU-FKP dataset.
Scale-aware competition network for palmprint recognition
Nov 21, 2023Palmprint biometrics garner heightened attention in palm-scanning payment and social security due to their distinctive attributes. However, prevailing methodologies singularly prioritize texture orientation, neglecting the significant texture scale dimension. We design an innovative network for concurrently extracting intra-scale and inter-scale features to redress this limitation. This paper proposes a scale-aware competitive network (SAC-Net), which includes the Inner-Scale Competition Module (ISCM) and the Across-Scale Competition Module (ASCM) to capture texture characteristics related to orientation and scale. ISCM efficiently integrates learnable Gabor filters and a self-attention mechanism to extract rich orientation data and discern textures with long-range discriminative properties. Subsequently, ASCM leverages a competitive strategy across various scales to effectively encapsulate the competitive texture scale elements. By synergizing ISCM and ASCM, our method adeptly characterizes palmprint features. Rigorous experimentation across three benchmark datasets unequivocally demonstrates our proposed approach's exceptional recognition performance and resilience relative to state-of-the-art alternatives.
Energizing Federated Learning via Filter-Aware Attention
Nov 18, 2023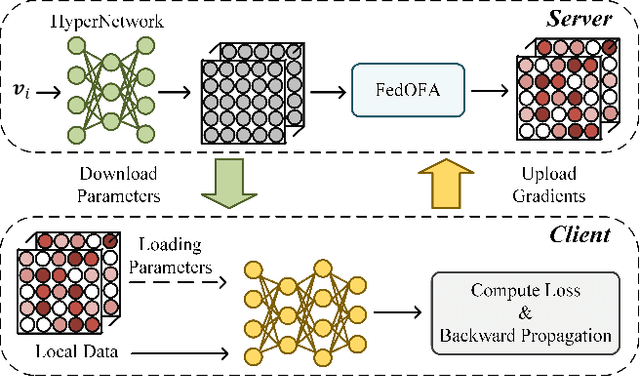
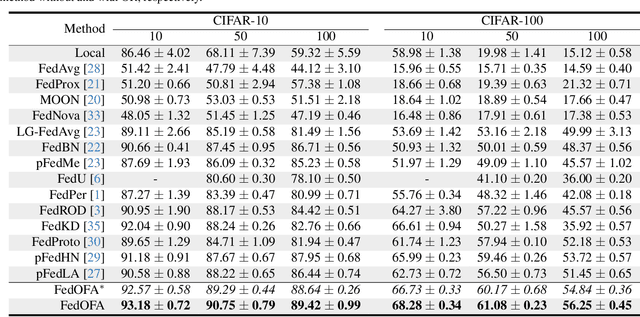
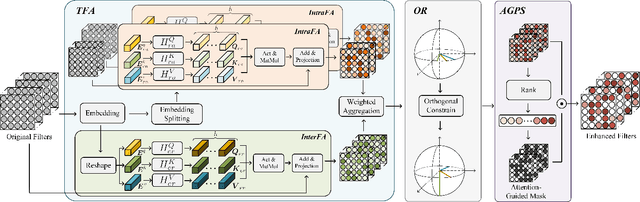
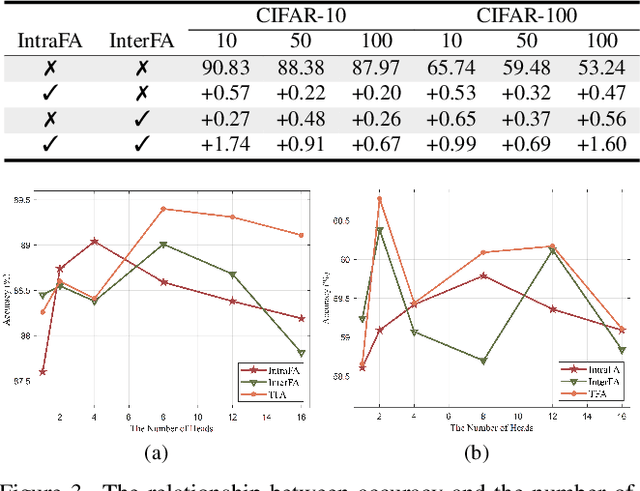
Federated learning (FL) is a promising distributed paradigm, eliminating the need for data sharing but facing challenges from data heterogeneity. Personalized parameter generation through a hypernetwork proves effective, yet existing methods fail to personalize local model structures. This leads to redundant parameters struggling to adapt to diverse data distributions. To address these limitations, we propose FedOFA, utilizing personalized orthogonal filter attention for parameter recalibration. The core is the Two-stream Filter-aware Attention (TFA) module, meticulously designed to extract personalized filter-aware attention maps, incorporating Intra-Filter Attention (IntraFa) and Inter-Filter Attention (InterFA) streams. These streams enhance representation capability and explore optimal implicit structures for local models. Orthogonal regularization minimizes redundancy by averting inter-correlation between filters. Furthermore, we introduce an Attention-Guided Pruning Strategy (AGPS) for communication efficiency. AGPS selectively retains crucial neurons while masking redundant ones, reducing communication costs without performance sacrifice. Importantly, FedOFA operates on the server side, incurring no additional computational cost on the client, making it advantageous in communication-constrained scenarios. Extensive experiments validate superior performance over state-of-the-art approaches, with code availability upon paper acceptance.