 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREEF: Relevance-Aware and Efficient LLM Adapter for Video Understanding
Apr 07, 2025Integrating vision models into large language models (LLMs) has sparked significant interest in creating vision-language foundation models, especially for video understanding. Recent methods often utilize memory banks to handle untrimmed videos for video-level understanding. However, they typically compress visual memory using similarity-based greedy approaches, which can overlook the contextual importance of individual tokens. To address this, we introduce an efficient LLM adapter designed for video-level understanding of untrimmed videos that prioritizes the contextual relevance of spatio-temporal tokens. Our framework leverages scorer networks to selectively compress the visual memory bank and filter spatial tokens based on relevance, using a differentiable Top-K operator for end-to-end training. Across three key video-level understanding tasks$\unicode{x2013}$ untrimmed video classification, video question answering, and video captioning$\unicode{x2013}$our method achieves competitive or superior results on four large-scale datasets while reducing computational overhead by up to 34%. The code will be available soon on GitHub.
TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection
Apr 03, 2025



We aim to solve unsupervised anomaly detection in a practical challenging environment where the normal dataset is both contaminated with defective regions and its product class distribution is tailed but unknown. We observe that existing models suffer from tail-versus-noise trade-off where if a model is robust against pixel noise, then its performance deteriorates on tail class samples, and vice versa. To mitigate the issue, we handle the tail class and noise samples independently. To this end, we propose TailSampler, a novel class size predictor that estimates the class cardinality of samples based on a symmetric assumption on the class-wise distribution of embedding similarities. TailSampler can be utilized to sample the tail class samples exclusively, allowing to handle them separately. Based on these facets, we build a memory-based anomaly detection model TailedCore, whose memory both well captures tail class information and is noise-robust. We extensively validate the effectiveness of TailedCore on the unsupervised long-tail noisy anomaly detection setting, and show that TailedCore outperforms the state-of-the-art in most settings.
Generalization Error Analysis for Selective State-Space Models Through the Lens of Attention
Feb 03, 2025State-space models (SSMs) are a new class of foundation models that have emerged as a compelling alternative to Transformers and their attention mechanisms for sequence processing tasks. This paper provides a detailed theoretical analysis of selective SSMs, the core components of the Mamba and Mamba-2 architectures. We leverage the connection between selective SSMs and the self-attention mechanism to highlight the fundamental similarities between these models. Building on this connection, we establish a length independent covering number-based generalization bound for selective SSMs, providing a deeper understanding of their theoretical performance guarantees. We analyze the effects of state matrix stability and input-dependent discretization, shedding light on the critical role played by these factors in the generalization capabilities of selective SSMs. Finally, we empirically demonstrate the sequence length independence of the derived bounds on two tasks.
HAT: History-Augmented Anchor Transformer for Online Temporal Action Localization
Aug 12, 2024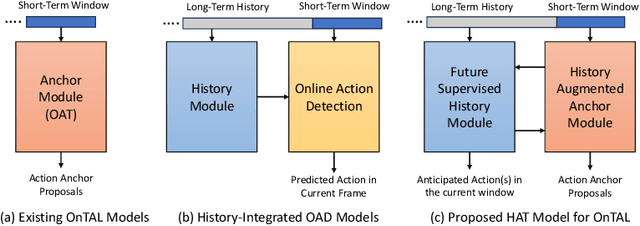
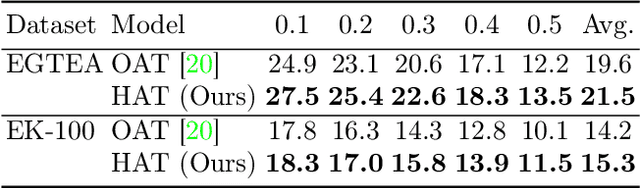
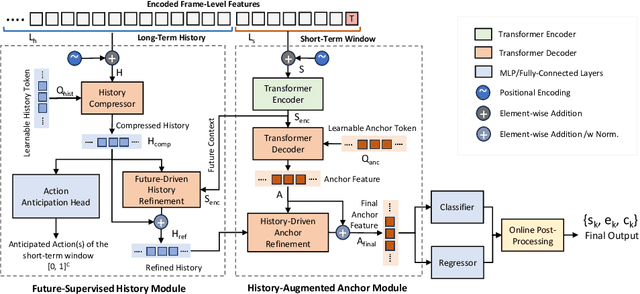
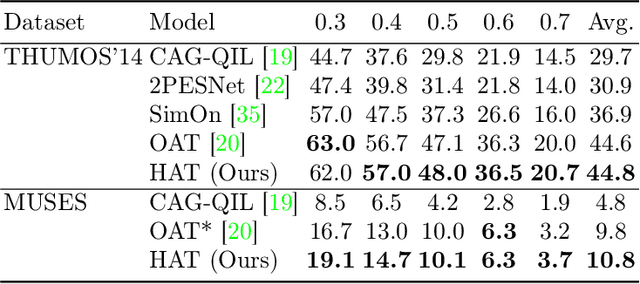
Online video understanding often relies on individual frames, leading to frame-by-frame predictions. Recent advancements such as Online Temporal Action Localization (OnTAL), extend this approach to instance-level predictions. However, existing methods mainly focus on short-term context, neglecting historical information. To address this, we introduce the History-Augmented Anchor Transformer (HAT) Framework for OnTAL. By integrating historical context, our framework enhances the synergy between long-term and short-term information, improving the quality of anchor features crucial for classification and localization. We evaluate our model on both procedural egocentric (PREGO) datasets (EGTEA and EPIC) and standard non-PREGO OnTAL datasets (THUMOS and MUSES). Results show that our model outperforms state-of-the-art approaches significantly on PREGO datasets and achieves comparable or slightly superior performance on non-PREGO datasets, underscoring the importance of leveraging long-term history, especially in procedural and egocentric action scenarios. Code is available at: https://github.com/sakibreza/ECCV24-HAT/
Face Reconstruction Transfer Attack as Out-of-Distribution Generalization
Jul 02, 2024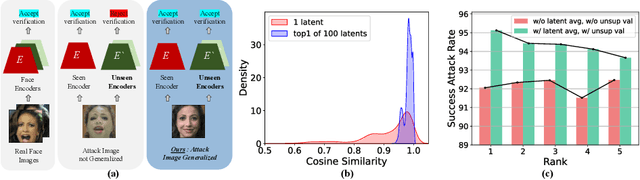
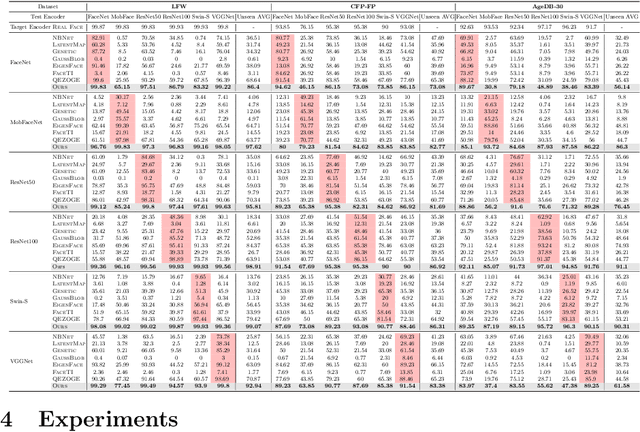
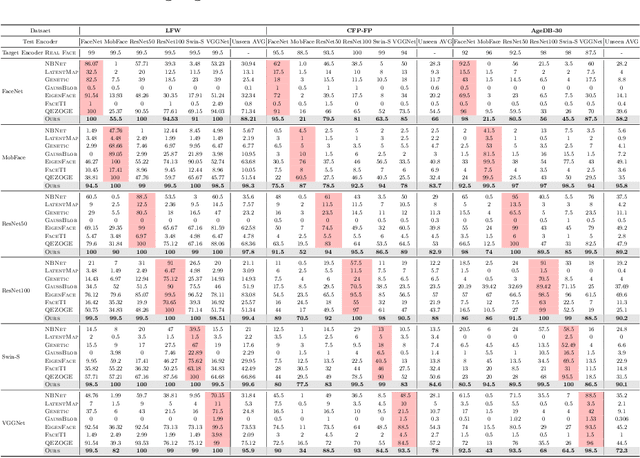
Understanding the vulnerability of face recognition systems to malicious attacks is of critical importance. Previous works have focused on reconstructing face images that can penetrate a targeted verification system. Even in the white-box scenario, however, naively reconstructed images misrepresent the identity information, hence the attacks are easily neutralized once the face system is updated or changed. In this paper, we aim to reconstruct face images which are capable of transferring face attacks on unseen encoders. We term this problem as Face Reconstruction Transfer Attack (FRTA) and show that it can be formulated as an out-of-distribution (OOD) generalization problem. Inspired by its OOD nature, we propose to solve FRTA by Averaged Latent Search and Unsupervised Validation with pseudo target (ALSUV). To strengthen the reconstruction attack on OOD unseen encoders, ALSUV reconstructs the face by searching the latent of amortized generator StyleGAN2 through multiple latent optimization, latent optimization trajectory averaging, and unsupervised validation with a pseudo target. We demonstrate the efficacy and generalization of our method on widely used face datasets, accompanying it with extensive ablation studies and visually, qualitatively, and quantitatively analyses. The source code will be released.
3D-HGS: 3D Half-Gaussian Splatting
Jun 04, 2024Photo-realistic 3D Reconstruction is a fundamental problem in 3D computer vision. This domain has seen considerable advancements owing to the advent of recent neural rendering techniques. These techniques predominantly aim to focus on learning volumetric representations of 3D scenes and refining these representations via loss functions derived from rendering. Among these, 3D Gaussian Splatting (3D-GS) has emerged as a significant method, surpassing Neural Radiance Fields (NeRFs). 3D-GS uses parameterized 3D Gaussians for modeling both spatial locations and color information, combined with a tile-based fast rendering technique. Despite its superior rendering performance and speed, the use of 3D Gaussian kernels has inherent limitations in accurately representing discontinuous functions, notably at edges and corners for shape discontinuities, and across varying textures for color discontinuities. To address this problem, we propose to employ 3D Half-Gaussian (3D-HGS) kernels, which can be used as a plug-and-play kernel. Our experiments demonstrate their capability to improve the performance of current 3D-GS related methods and achieve state-of-the-art rendering performance on various datasets without compromising rendering speed.
Solving Masked Jigsaw Puzzles with Diffusion Vision Transformers
Apr 10, 2024



Solving image and video jigsaw puzzles poses the challenging task of rearranging image fragments or video frames from unordered sequences to restore meaningful images and video sequences. Existing approaches often hinge on discriminative models tasked with predicting either the absolute positions of puzzle elements or the permutation actions applied to the original data. Unfortunately, these methods face limitations in effectively solving puzzles with a large number of elements. In this paper, we propose JPDVT, an innovative approach that harnesses diffusion transformers to address this challenge. Specifically, we generate positional information for image patches or video frames, conditioned on their underlying visual content. This information is then employed to accurately assemble the puzzle pieces in their correct positions, even in scenarios involving missing pieces. Our method achieves state-of-the-art performance on several datasets.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024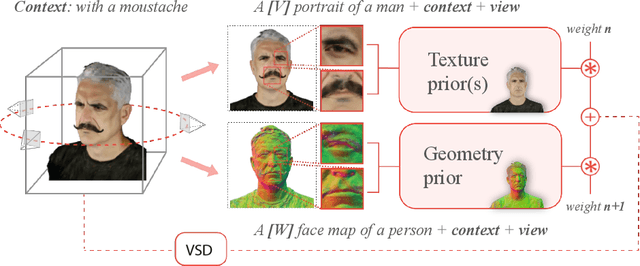



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Inferring Relational Potentials in Interacting Systems
Oct 23, 2023Systems consisting of interacting agents are prevalent in the world, ranging from dynamical systems in physics to complex biological networks. To build systems which can interact robustly in the real world, it is thus important to be able to infer the precise interactions governing such systems. Existing approaches typically discover such interactions by explicitly modeling the feed-forward dynamics of the trajectories. In this work, we propose Neural Interaction Inference with Potentials (NIIP) as an alternative approach to discover such interactions that enables greater flexibility in trajectory modeling: it discovers a set of relational potentials, represented as energy functions, which when minimized reconstruct the original trajectory. NIIP assigns low energy to the subset of trajectories which respect the relational constraints observed. We illustrate that with these representations NIIP displays unique capabilities in test-time. First, it allows trajectory manipulation, such as interchanging interaction types across separately trained models, as well as trajectory forecasting. Additionally, it allows adding external hand-crafted potentials at test-time. Finally, NIIP enables the detection of out-of-distribution samples and anomalies without explicit training. Website: https://energy-based-model.github.io/interaction-potentials.
Enhancing Transformer Backbone for Egocentric Video Action Segmentation
May 23, 2023Egocentric temporal action segmentation in videos is a crucial task in computer vision with applications in various fields such as mixed reality, human behavior analysis, and robotics. Although recent research has utilized advanced visual-language frameworks, transformers remain the backbone of action segmentation models. Therefore, it is necessary to improve transformers to enhance the robustness of action segmentation models. In this work, we propose two novel ideas to enhance the state-of-the-art transformer for action segmentation. First, we introduce a dual dilated attention mechanism to adaptively capture hierarchical representations in both local-to-global and global-to-local contexts. Second, we incorporate cross-connections between the encoder and decoder blocks to prevent the loss of local context by the decoder. We also utilize state-of-the-art visual-language representation learning techniques to extract richer and more compact features for our transformer. Our proposed approach outperforms other state-of-the-art methods on the Georgia Tech Egocentric Activities (GTEA) and HOI4D Office Tools datasets, and we validate our introduced components with ablation studies. The source code and supplementary materials are publicly available on https://www.sail-nu.com/dxformer.