 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREEF: Relevance-Aware and Efficient LLM Adapter for Video Understanding
Apr 07, 2025Integrating vision models into large language models (LLMs) has sparked significant interest in creating vision-language foundation models, especially for video understanding. Recent methods often utilize memory banks to handle untrimmed videos for video-level understanding. However, they typically compress visual memory using similarity-based greedy approaches, which can overlook the contextual importance of individual tokens. To address this, we introduce an efficient LLM adapter designed for video-level understanding of untrimmed videos that prioritizes the contextual relevance of spatio-temporal tokens. Our framework leverages scorer networks to selectively compress the visual memory bank and filter spatial tokens based on relevance, using a differentiable Top-K operator for end-to-end training. Across three key video-level understanding tasks$\unicode{x2013}$ untrimmed video classification, video question answering, and video captioning$\unicode{x2013}$our method achieves competitive or superior results on four large-scale datasets while reducing computational overhead by up to 34%. The code will be available soon on GitHub.
MetaFAP: Meta-Learning for Frequency Agnostic Prediction of Metasurface Properties
Mar 19, 2025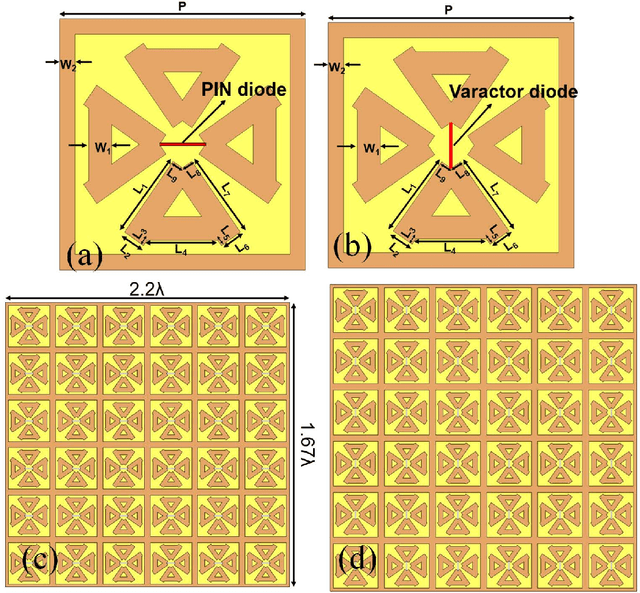
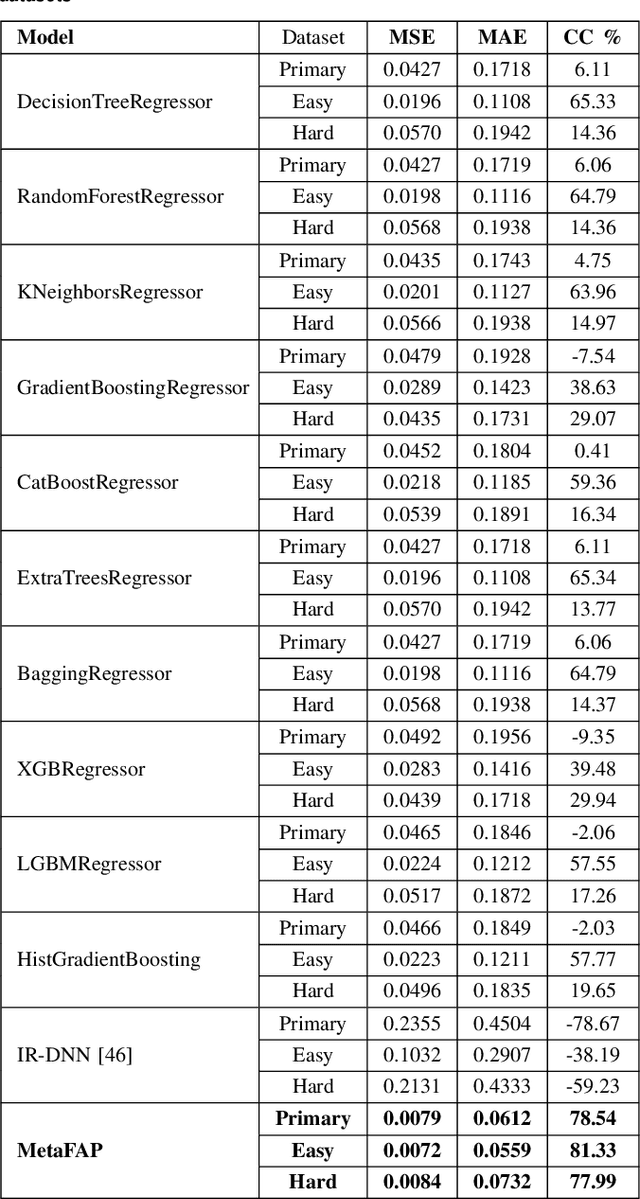
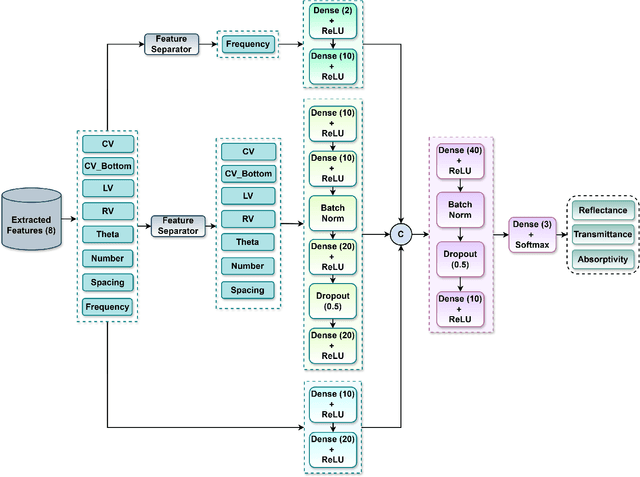
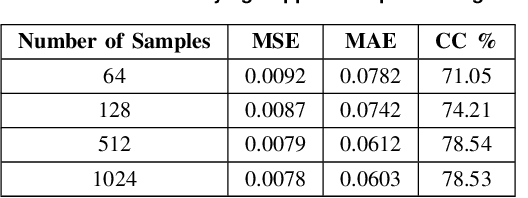
Metasurfaces, and in particular reconfigurable intelligent surfaces (RIS), are revolutionizing wireless communications by dynamically controlling electromagnetic waves. Recent wireless communication advancements necessitate broadband and multi-band RIS, capable of supporting dynamic spectrum access and carrier aggregation from sub-6 GHz to mmWave and THz bands. The inherent frequency dependence of meta-atom resonances degrades performance as operating conditions change, making real-time, frequency-agnostic metasurface property prediction crucial for practical deployment. Yet, accurately predicting metasurface behavior across different frequencies remains challenging. Traditional simulations struggle with complexity, while standard deep learning models often overfit or generalize poorly. To address this, we introduce MetaFAP (Meta-Learning for Frequency-Agnostic Prediction), a novel framework built on the meta-learning paradigm for predicting metasurface properties. By training on diverse frequency tasks, MetaFAP learns broadly applicable patterns. This allows it to adapt quickly to new spectral conditions with minimal data, solving key limitations of existing methods. Experimental evaluations demonstrate that MetaFAP reduces prediction errors by an order of magnitude in MSE and MAE while maintaining high Pearson correlations. Remarkably, it achieves inference in less than a millisecond, bypassing the computational bottlenecks of traditional simulations, which take minutes per unit cell and scale poorly with array size. These improvements enable real-time RIS optimization in dynamic environments and support scalable, frequency-agnostic designs. MetaFAP thus bridges the gap between intelligent electromagnetic systems and practical deployment, offering a critical tool for next-generation wireless networks.
HAT: History-Augmented Anchor Transformer for Online Temporal Action Localization
Aug 12, 2024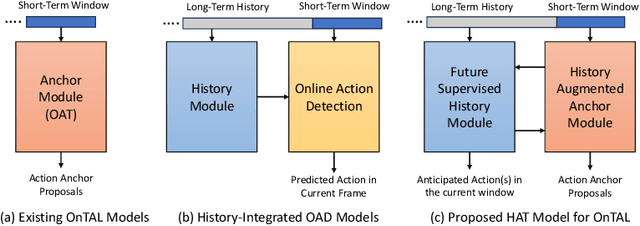
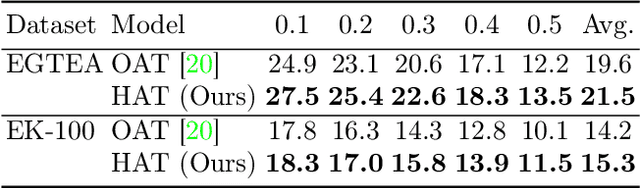
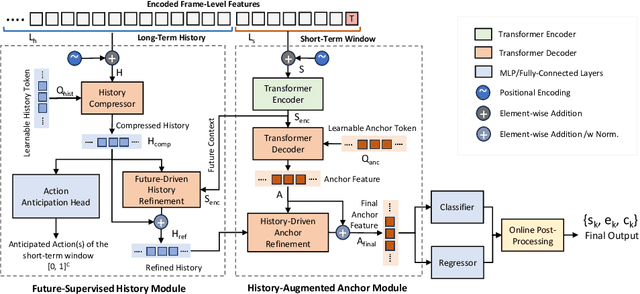
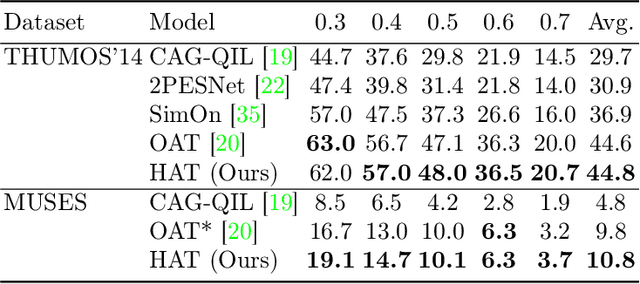
Online video understanding often relies on individual frames, leading to frame-by-frame predictions. Recent advancements such as Online Temporal Action Localization (OnTAL), extend this approach to instance-level predictions. However, existing methods mainly focus on short-term context, neglecting historical information. To address this, we introduce the History-Augmented Anchor Transformer (HAT) Framework for OnTAL. By integrating historical context, our framework enhances the synergy between long-term and short-term information, improving the quality of anchor features crucial for classification and localization. We evaluate our model on both procedural egocentric (PREGO) datasets (EGTEA and EPIC) and standard non-PREGO OnTAL datasets (THUMOS and MUSES). Results show that our model outperforms state-of-the-art approaches significantly on PREGO datasets and achieves comparable or slightly superior performance on non-PREGO datasets, underscoring the importance of leveraging long-term history, especially in procedural and egocentric action scenarios. Code is available at: https://github.com/sakibreza/ECCV24-HAT/
Enhancing Transformer Backbone for Egocentric Video Action Segmentation
May 23, 2023Egocentric temporal action segmentation in videos is a crucial task in computer vision with applications in various fields such as mixed reality, human behavior analysis, and robotics. Although recent research has utilized advanced visual-language frameworks, transformers remain the backbone of action segmentation models. Therefore, it is necessary to improve transformers to enhance the robustness of action segmentation models. In this work, we propose two novel ideas to enhance the state-of-the-art transformer for action segmentation. First, we introduce a dual dilated attention mechanism to adaptively capture hierarchical representations in both local-to-global and global-to-local contexts. Second, we incorporate cross-connections between the encoder and decoder blocks to prevent the loss of local context by the decoder. We also utilize state-of-the-art visual-language representation learning techniques to extract richer and more compact features for our transformer. Our proposed approach outperforms other state-of-the-art methods on the Georgia Tech Egocentric Activities (GTEA) and HOI4D Office Tools datasets, and we validate our introduced components with ablation studies. The source code and supplementary materials are publicly available on https://www.sail-nu.com/dxformer.