 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAT: History-Augmented Anchor Transformer for Online Temporal Action Localization
Aug 12, 2024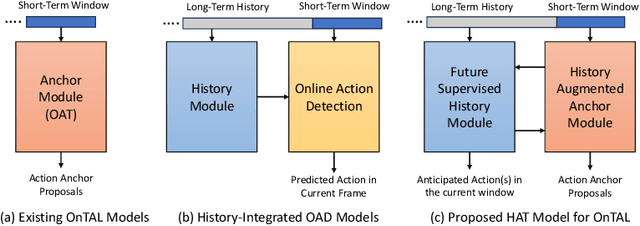
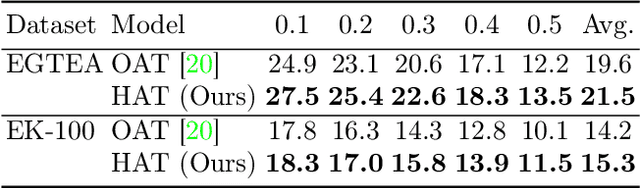
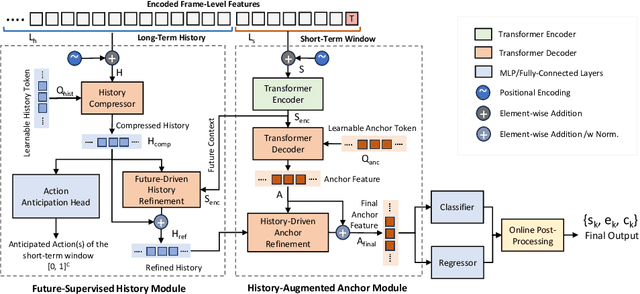
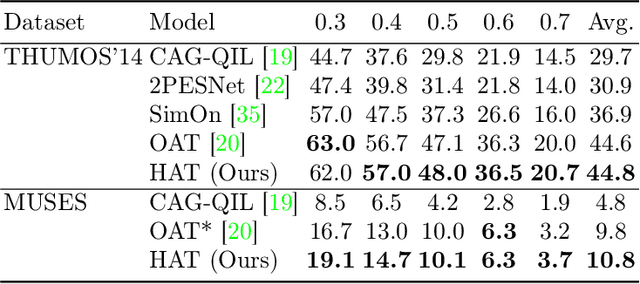
Online video understanding often relies on individual frames, leading to frame-by-frame predictions. Recent advancements such as Online Temporal Action Localization (OnTAL), extend this approach to instance-level predictions. However, existing methods mainly focus on short-term context, neglecting historical information. To address this, we introduce the History-Augmented Anchor Transformer (HAT) Framework for OnTAL. By integrating historical context, our framework enhances the synergy between long-term and short-term information, improving the quality of anchor features crucial for classification and localization. We evaluate our model on both procedural egocentric (PREGO) datasets (EGTEA and EPIC) and standard non-PREGO OnTAL datasets (THUMOS and MUSES). Results show that our model outperforms state-of-the-art approaches significantly on PREGO datasets and achieves comparable or slightly superior performance on non-PREGO datasets, underscoring the importance of leveraging long-term history, especially in procedural and egocentric action scenarios. Code is available at: https://github.com/sakibreza/ECCV24-HAT/
Cross-view Action Recognition via Contrastive View-invariant Representation
May 02, 2023Cross view action recognition (CVAR) seeks to recognize a human action when observed from a previously unseen viewpoint. This is a challenging problem since the appearance of an action changes significantly with the viewpoint. Applications of CVAR include surveillance and monitoring of assisted living facilities where is not practical or feasible to collect large amounts of training data when adding a new camera. We present a simple yet efficient CVAR framework to learn invariant features from either RGB videos, 3D skeleton data, or both. The proposed approach outperforms the current state-of-the-art achieving similar levels of performance across input modalities: 99.4% (RGB) and 99.9% (3D skeletons), 99.4% (RGB) and 99.9% (3D Skeletons), 97.3% (RGB), and 99.2% (3D skeletons), and 84.4%(RGB) for the N-UCLA, NTU-RGB+D 60, NTU-RGB+D 120, and UWA3DII datasets, respectively.
Key Frame Proposal Network for Efficient Pose Estimation in Videos
Jul 30, 2020

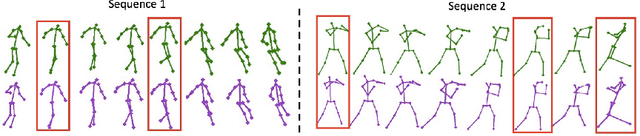

Human pose estimation in video relies on local information by either estimating each frame independently or tracking poses across frames. In this paper, we propose a novel method combining local approaches with global context. We introduce a light weighted, unsupervised, key frame proposal network (K-FPN) to select informative frames and a learned dictionary to recover the entire pose sequence from these frames. The K-FPN speeds up the pose estimation and provides robustness to bad frames with occlusion, motion blur, and illumination changes, while the learned dictionary provides global dynamic context. Experiments on Penn Action and sub-JHMDB datasets show that the proposed method achieves state-of-the-art accuracy, with substantial speed-up.