 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Frame Proposal Network for Efficient Pose Estimation in Videos
Paper and Code


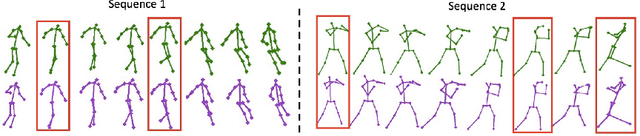

Human pose estimation in video relies on local information by either estimating each frame independently or tracking poses across frames. In this paper, we propose a novel method combining local approaches with global context. We introduce a light weighted, unsupervised, key frame proposal network (K-FPN) to select informative frames and a learned dictionary to recover the entire pose sequence from these frames. The K-FPN speeds up the pose estimation and provides robustness to bad frames with occlusion, motion blur, and illumination changes, while the learned dictionary provides global dynamic context. Experiments on Penn Action and sub-JHMDB datasets show that the proposed method achieves state-of-the-art accuracy, with substantial speed-up.