 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024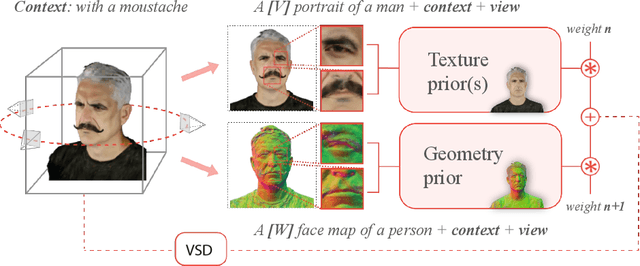



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Content-Consistent Generation of Realistic Eyes with Style
Nov 08, 2019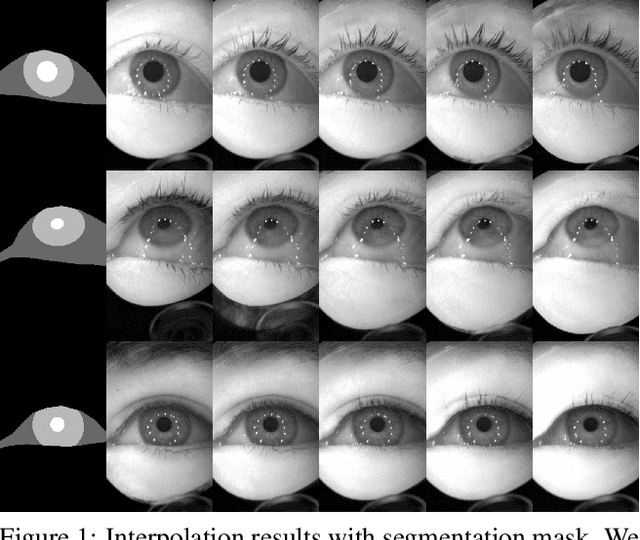
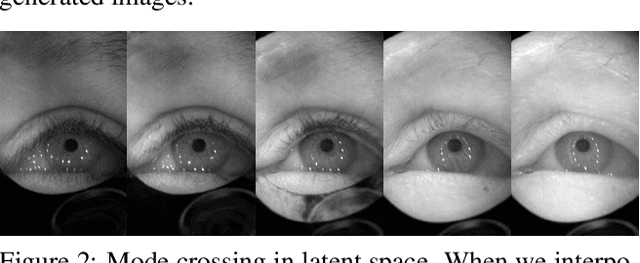
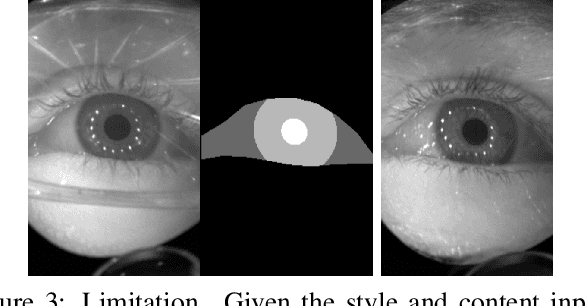
Accurately labeled real-world training data can be scarce, and hence recent works adapt, modify or generate images to boost target datasets. However, retaining relevant details from input data in the generated images is challenging and failure could be critical to the performance on the final task. In this work, we synthesize person-specific eye images that satisfy a given semantic segmentation mask (content), while following the style of a specified person from only a few reference images. We introduce two approaches, (a) one used to win the OpenEDS Synthetic Eye Generation Challenge at ICCV 2019, and (b) a principled approach to solving the problem involving simultaneous injection of style and content information at multiple scales. Our implementation is available at https://github.com/mcbuehler/Seg2Eye.