 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGPT: Geometry Grounded Point Transformer
Mar 11, 2026Recent feed-forward networks have achieved remarkable progress in sparse-view 3D reconstruction by predicting dense point maps directly from RGB images. However, they often suffer from geometric inconsistencies and limited fine-grained accuracy due to the absence of explicit multi-view constraints. We introduce the Geometry-Grounded Point Transformer (GGPT), a framework that augments feed-forward reconstruction with reliable sparse geometric guidance. We first propose an improved Structure-from-Motion pipeline based on dense feature matching and lightweight geometric optimisation to efficiently estimate accurate camera poses and partial 3D point clouds from sparse input views. Building on this foundation, we propose a geometry-guided 3D point transformer that refines dense point maps under explicit partial-geometry supervision using an optimised guidance encoding. Extensive experiments demonstrate that our method provides a principled mechanism for integrating geometric priors with dense feed-forward predictions, producing reconstructions that are both geometrically consistent and spatially complete, recovering fine structures and filling gaps in textureless areas. Trained solely on ScanNet++ with VGGT predictions, GGPT generalises across architectures and datasets, substantially outperforming state-of-the-art feed-forward 3D reconstruction models in both in-domain and out-of-domain settings.
UniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Feb 04, 2025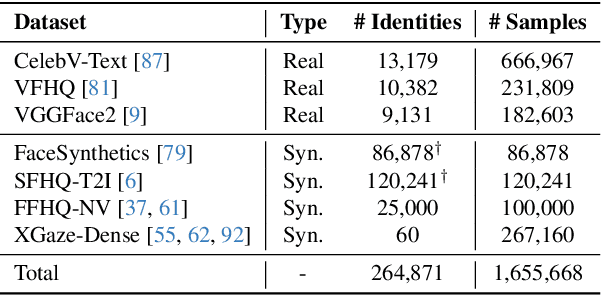
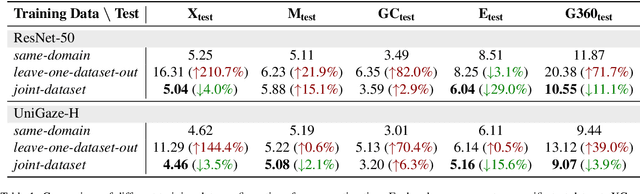

Despite decades of research on data collection and model architectures, current gaze estimation models face significant challenges in generalizing across diverse data domains. While recent advances in self-supervised pre-training have shown remarkable potential for improving model generalization in various vision tasks, their effectiveness in gaze estimation remains unexplored due to the geometric nature of the gaze regression task. We propose UniGaze, which leverages large-scale, in-the-wild facial datasets through self-supervised pre-training for gaze estimation. We carefully curate multiple facial datasets that capture diverse variations in identity, lighting, background, and head poses. By directly applying Masked Autoencoder (MAE) pre-training on normalized face images with a Vision Transformer (ViT) backbone, our UniGaze learns appropriate feature representations within the specific input space required by downstream gaze estimation models. Through comprehensive experiments using challenging cross-dataset evaluation and novel protocols, including leave-one-dataset-out and joint-dataset settings, we demonstrate that UniGaze significantly improves generalization across multiple data domains while minimizing reliance on costly labeled data. The source code and pre-trained models will be released upon acceptance.
PrivateGaze: Preserving User Privacy in Black-box Mobile Gaze Tracking Services
Aug 01, 2024



Eye gaze contains rich information about human attention and cognitive processes. This capability makes the underlying technology, known as gaze tracking, a critical enabler for many ubiquitous applications and has triggered the development of easy-to-use gaze estimation services. Indeed, by utilizing the ubiquitous cameras on tablets and smartphones, users can readily access many gaze estimation services. In using these services, users must provide their full-face images to the gaze estimator, which is often a black box. This poses significant privacy threats to the users, especially when a malicious service provider gathers a large collection of face images to classify sensitive user attributes. In this work, we present PrivateGaze, the first approach that can effectively preserve users' privacy in black-box gaze tracking services without compromising gaze estimation performance. Specifically, we proposed a novel framework to train a privacy preserver that converts full-face images into obfuscated counterparts, which are effective for gaze estimation while containing no privacy information. Evaluation on four datasets shows that the obfuscated image can protect users' private information, such as identity and gender, against unauthorized attribute classification. Meanwhile, when used directly by the black-box gaze estimator as inputs, the obfuscated images lead to comparable tracking performance to the conventional, unprotected full-face images.
GazeHTA: End-to-end Gaze Target Detection with Head-Target Association
Apr 19, 2024We propose an end-to-end approach for gaze target detection: predicting a head-target connection between individuals and the target image regions they are looking at. Most of the existing methods use independent components such as off-the-shelf head detectors or have problems in establishing associations between heads and gaze targets. In contrast, we investigate an end-to-end multi-person Gaze target detection framework with Heads and Targets Association (GazeHTA), which predicts multiple head-target instances based solely on input scene image. GazeHTA addresses challenges in gaze target detection by (1) leveraging a pre-trained diffusion model to extract scene features for rich semantic understanding, (2) re-injecting a head feature to enhance the head priors for improved head understanding, and (3) learning a connection map as the explicit visual associations between heads and gaze targets. Our extensive experimental results demonstrate that GazeHTA outperforms state-of-the-art gaze target detection methods and two adapted diffusion-based baselines on two standard datasets.
3D Kinematics Estimation from Video with a Biomechanical Model and Synthetic Training Data
Feb 26, 2024



Accurate 3D kinematics estimation of human body is crucial in various applications for human health and mobility, such as rehabilitation, injury prevention, and diagnosis, as it helps to understand the biomechanical loading experienced during movement. Conventional marker-based motion capture is expensive in terms of financial investment, time, and the expertise required. Moreover, due to the scarcity of datasets with accurate annotations, existing markerless motion capture methods suffer from challenges including unreliable 2D keypoint detection, limited anatomic accuracy, and low generalization capability. In this work, we propose a novel biomechanics-aware network that directly outputs 3D kinematics from two input views with consideration of biomechanical prior and spatio-temporal information. To train the model, we create synthetic dataset ODAH with accurate kinematics annotations generated by aligning the body mesh from the SMPL-X model and a full-body OpenSim skeletal model. Our extensive experiments demonstrate that the proposed approach, only trained on synthetic data, outperforms previous state-of-the-art methods when evaluated across multiple datasets, revealing a promising direction for enhancing video-based human motion capture.
Unsupervised Gaze-aware Contrastive Learning with Subject-specific Condition
Sep 08, 2023



Appearance-based gaze estimation has shown great promise in many applications by using a single general-purpose camera as the input device. However, its success is highly depending on the availability of large-scale well-annotated gaze datasets, which are sparse and expensive to collect. To alleviate this challenge we propose ConGaze, a contrastive learning-based framework that leverages unlabeled facial images to learn generic gaze-aware representations across subjects in an unsupervised way. Specifically, we introduce the gaze-specific data augmentation to preserve the gaze-semantic features and maintain the gaze consistency, which are proven to be crucial for effective contrastive gaze representation learning. Moreover, we devise a novel subject-conditional projection module that encourages a share feature extractor to learn gaze-aware and generic representations. Our experiments on three public gaze estimation datasets show that ConGaze outperforms existing unsupervised learning solutions by 6.7% to 22.5%; and achieves 15.1% to 24.6% improvement over its supervised learning-based counterpart in cross-dataset evaluations.
Investigation of Architectures and Receptive Fields for Appearance-based Gaze Estimation
Aug 18, 2023


With the rapid development of deep learning technology in the past decade, appearance-based gaze estimation has attracted great attention from both computer vision and human-computer interaction research communities. Fascinating methods were proposed with variant mechanisms including soft attention, hard attention, two-eye asymmetry, feature disentanglement, rotation consistency, and contrastive learning. Most of these methods take the single-face or multi-region as input, yet the basic architecture of gaze estimation has not been fully explored. In this paper, we reveal the fact that tuning a few simple parameters of a ResNet architecture can outperform most of the existing state-of-the-art methods for the gaze estimation task on three popular datasets. With our extensive experiments, we conclude that the stride number, input image resolution, and multi-region architecture are critical for the gaze estimation performance while their effectiveness dependent on the quality of the input face image. We obtain the state-of-the-art performances on three datasets with 3.64 on ETH-XGaze, 4.50 on MPIIFaceGaze, and 9.13 on Gaze360 degrees gaze estimation error by taking ResNet-50 as the backbone.
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
May 25, 2023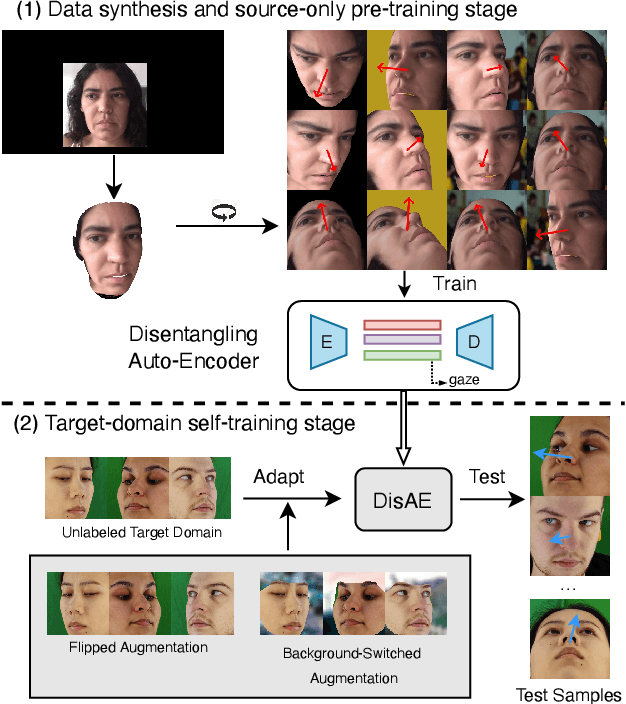
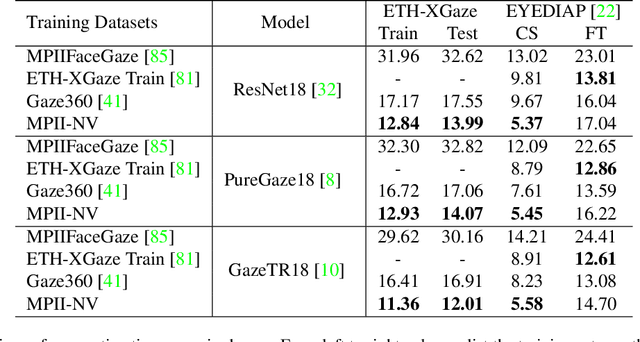
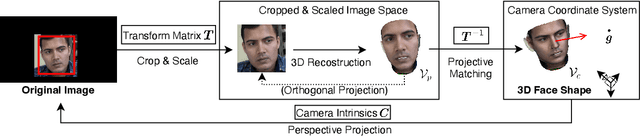
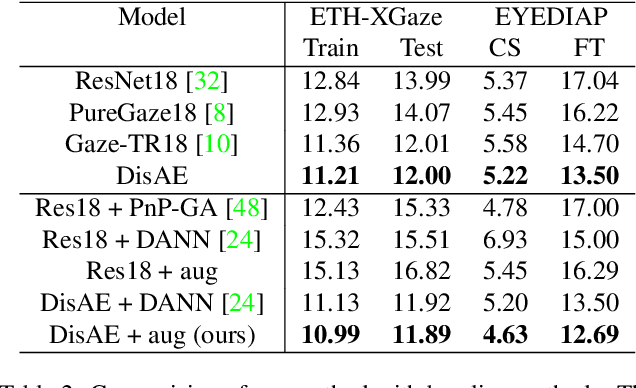
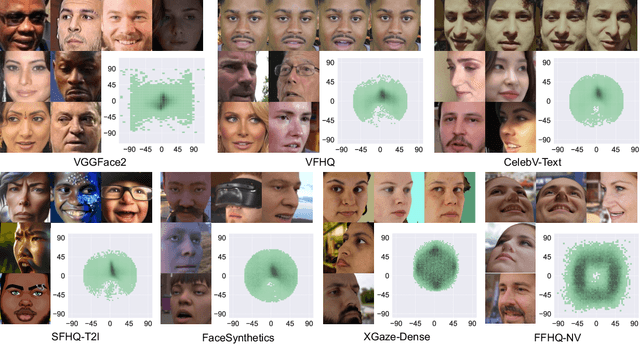
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play a significant role in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, we show that the model only using monocular-reconstructed synthetic training data can perform comparably to real data with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at \url{https://github.com/ut-vision/AdaptiveGaze}.
EFE: End-to-end Frame-to-Gaze Estimation
May 09, 2023
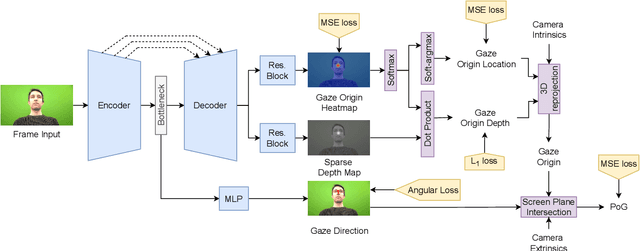
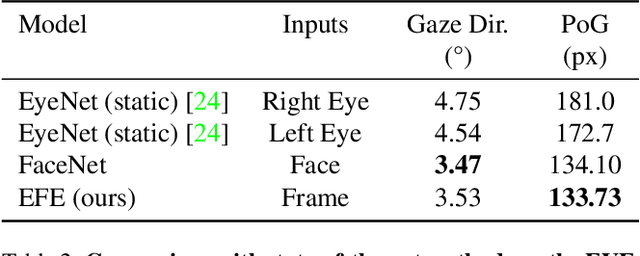
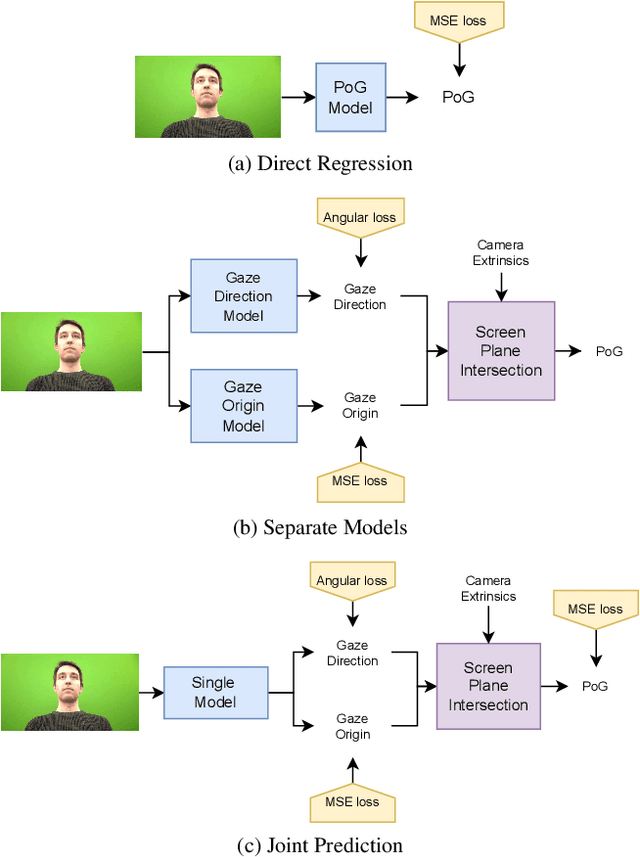
Despite the recent development of learning-based gaze estimation methods, most methods require one or more eye or face region crops as inputs and produce a gaze direction vector as output. Cropping results in a higher resolution in the eye regions and having fewer confounding factors (such as clothing and hair) is believed to benefit the final model performance. However, this eye/face patch cropping process is expensive, erroneous, and implementation-specific for different methods. In this paper, we propose a frame-to-gaze network that directly predicts both 3D gaze origin and 3D gaze direction from the raw frame out of the camera without any face or eye cropping. Our method demonstrates that direct gaze regression from the raw downscaled frame, from FHD/HD to VGA/HVGA resolution, is possible despite the challenges of having very few pixels in the eye region. The proposed method achieves comparable results to state-of-the-art methods in Point-of-Gaze (PoG) estimation on three public gaze datasets: GazeCapture, MPIIFaceGaze, and EVE, and generalizes well to extreme camera view changes.
Towards Single Camera Human 3D-Kinematics
Jan 13, 2023



Markerless estimation of 3D Kinematics has the great potential to clinically diagnose and monitor movement disorders without referrals to expensive motion capture labs; however, current approaches are limited by performing multiple de-coupled steps to estimate the kinematics of a person from videos. Most current techniques work in a multi-step approach by first detecting the pose of the body and then fitting a musculoskeletal model to the data for accurate kinematic estimation. Errors in training data of the pose detection algorithms, model scaling, as well the requirement of multiple cameras limit the use of these techniques in a clinical setting. Our goal is to pave the way toward fast, easily applicable and accurate 3D kinematic estimation \xdeleted{in a clinical setting}. To this end, we propose a novel approach for direct 3D human kinematic estimation D3KE from videos using deep neural networks. Our experiments demonstrate that the proposed end-to-end training is robust and outperforms 2D and 3D markerless motion capture based kinematic estimation pipelines in terms of joint angles error by a large margin (35\% from 5.44 to 3.54 degrees). We show that D3KE is superior to the multi-step approach and can run at video framerate speeds. This technology shows the potential for clinical analysis from mobile devices in the future.
* Published in the MDPI Sensors special Issue "Sensors and Musculoskeletal Dynamics to Evaluate Human Movement" on December 28, 2022