 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Diffusion Sampling for Predictive Control in Offline Decision Making
Dec 09, 2025Offline decision-making requires synthesizing reliable behaviors from fixed datasets without further interaction, yet existing generative approaches often yield trajectories that are dynamically infeasible. We propose Model Predictive Diffuser (MPDiffuser), a compositional model-based diffusion framework consisting of: (i) a planner that generates diverse, task-aligned trajectories; (ii) a dynamics model that enforces consistency with the underlying system dynamics; and (iii) a ranker module that selects behaviors aligned with the task objectives. MPDiffuser employs an alternating diffusion sampling scheme, where planner and dynamics updates are interleaved to progressively refine trajectories for both task alignment and feasibility during the sampling process. We also provide a theoretical rationale for this procedure, showing how it balances fidelity to data priors with dynamics consistency. Empirically, the compositional design improves sample efficiency, as it leverages even low-quality data for dynamics learning and adapts seamlessly to novel dynamics. We evaluate MPDiffuser on both unconstrained (D4RL) and constrained (DSRL) offline decision-making benchmarks, demonstrating consistent gains over existing approaches. Furthermore, we present a preliminary study extending MPDiffuser to vision-based control tasks, showing its potential to scale to high-dimensional sensory inputs. Finally, we deploy our method on a real quadrupedal robot, showcasing its practicality for real-world control.
A Model-Based Approach to Imitation Learning through Multi-Step Predictions
Apr 18, 2025Imitation learning is a widely used approach for training agents to replicate expert behavior in complex decision-making tasks. However, existing methods often struggle with compounding errors and limited generalization, due to the inherent challenge of error correction and the distribution shift between training and deployment. In this paper, we present a novel model-based imitation learning framework inspired by model predictive control, which addresses these limitations by integrating predictive modeling through multi-step state predictions. Our method outperforms traditional behavior cloning numerical benchmarks, demonstrating superior robustness to distribution shift and measurement noise both in available data and during execution. Furthermore, we provide theoretical guarantees on the sample complexity and error bounds of our method, offering insights into its convergence properties.
Can Transformers Learn Optimal Filtering for Unknown Systems?
Aug 16, 2023



Transformers have demonstrated remarkable success in natural language processing; however, their potential remains mostly unexplored for problems arising in dynamical systems. In this work, we investigate the optimal output estimation problem using transformers, which generate output predictions using all the past ones. We train the transformer using various systems drawn from a prior distribution and then evaluate its performance on previously unseen systems from the same distribution. As a result, the obtained transformer acts like a prediction algorithm that learns in-context and quickly adapts to and predicts well for different systems - thus we call it meta-output-predictor (MOP). MOP matches the performance of the optimal output estimator, based on Kalman filter, for most linear dynamical systems even though it does not have access to a model. We observe via extensive numerical experiments that MOP also performs well in challenging scenarios with non-i.i.d. noise, time-varying dynamics, and nonlinear dynamics like a quadrotor system with unknown parameters. To further support this observation, in the second part of the paper, we provide statistical guarantees on the performance of MOP and quantify the required amount of training to achieve a desired excess risk during test-time. Finally, we point out some limitations of MOP by identifying two classes of problems MOP fails to perform well, highlighting the need for caution when using transformers for control and estimation.
EFE: End-to-end Frame-to-Gaze Estimation
May 09, 2023
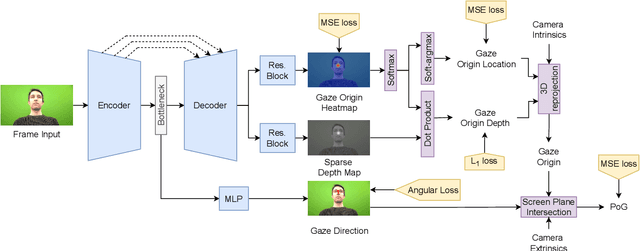
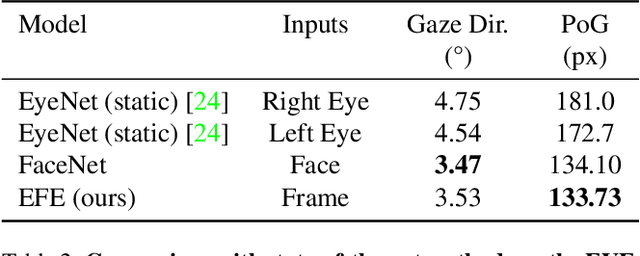
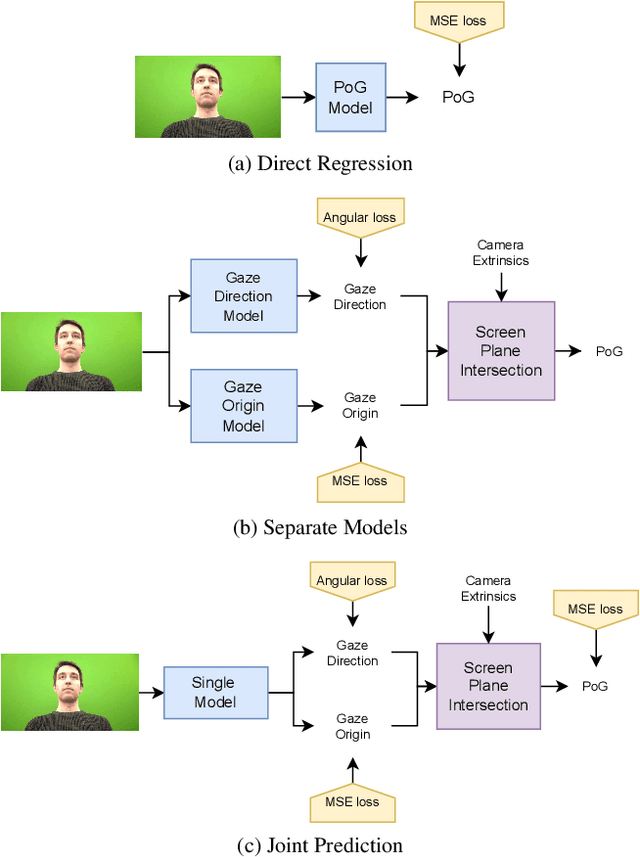
Despite the recent development of learning-based gaze estimation methods, most methods require one or more eye or face region crops as inputs and produce a gaze direction vector as output. Cropping results in a higher resolution in the eye regions and having fewer confounding factors (such as clothing and hair) is believed to benefit the final model performance. However, this eye/face patch cropping process is expensive, erroneous, and implementation-specific for different methods. In this paper, we propose a frame-to-gaze network that directly predicts both 3D gaze origin and 3D gaze direction from the raw frame out of the camera without any face or eye cropping. Our method demonstrates that direct gaze regression from the raw downscaled frame, from FHD/HD to VGA/HVGA resolution, is possible despite the challenges of having very few pixels in the eye region. The proposed method achieves comparable results to state-of-the-art methods in Point-of-Gaze (PoG) estimation on three public gaze datasets: GazeCapture, MPIIFaceGaze, and EVE, and generalizes well to extreme camera view changes.