 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and How Unlabeled Data Provably Improve In-Context Learning
Jun 18, 2025Recent research shows that in-context learning (ICL) can be effective even when demonstrations have missing or incorrect labels. To shed light on this capability, we examine a canonical setting where the demonstrations are drawn according to a binary Gaussian mixture model (GMM) and a certain fraction of the demonstrations have missing labels. We provide a comprehensive theoretical study to show that: (1) The loss landscape of one-layer linear attention models recover the optimal fully-supervised estimator but completely fail to exploit unlabeled data; (2) In contrast, multilayer or looped transformers can effectively leverage unlabeled data by implicitly constructing estimators of the form $\sum_{i\ge 0} a_i (X^\top X)^iX^\top y$ with $X$ and $y$ denoting features and partially-observed labels (with missing entries set to zero). We characterize the class of polynomials that can be expressed as a function of depth and draw connections to Expectation Maximization, an iterative pseudo-labeling algorithm commonly used in semi-supervised learning. Importantly, the leading polynomial power is exponential in depth, so mild amount of depth/looping suffices. As an application of theory, we propose looping off-the-shelf tabular foundation models to enhance their semi-supervision capabilities. Extensive evaluations on real-world datasets show that our method significantly improves the semisupervised tabular learning performance over the standard single pass inference.
Extrapolation by Association: Length Generalization Transfer in Transformers
Jun 10, 2025Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this paper, we investigate length generalization--the ability to extrapolate from shorter to longer inputs--through the lens of \textit{task association}. We find that length generalization can be \textit{transferred} across related tasks. That is, training a model with a longer and related auxiliary task can lead it to generalize to unseen and longer inputs from some other target task. We demonstrate this length generalization transfer across diverse algorithmic tasks, including arithmetic operations, string transformations, and maze navigation. Our results show that transformer models can inherit generalization capabilities from similar tasks when trained jointly. Moreover, we observe similar transfer effects in pretrained language models, suggesting that pretraining equips models with reusable computational scaffolding that facilitates extrapolation in downstream settings. Finally, we provide initial mechanistic evidence that length generalization transfer correlates with the re-use of the same attention heads between the tasks. Together, our findings deepen our understanding of how transformers generalize to out-of-distribution inputs and highlight the compositional reuse of inductive structure across tasks.
Continuous Chain of Thought Enables Parallel Exploration and Reasoning
May 29, 2025Current language models generate chain-of-thought traces by autoregressively sampling tokens from a finite vocabulary. While this discrete sampling has achieved remarkable success, conducting chain-of-thought with continuously-valued tokens (CoT2) offers a richer and more expressive alternative. Our work examines the benefits of CoT2 through logical reasoning tasks that inherently require search capabilities and provide optimization and exploration methods for CoT2. Theoretically, we show that CoT2 allows the model to track multiple traces in parallel and quantify its benefits for inference efficiency. Notably, one layer transformer equipped with CoT2 can provably solve the combinatorial "subset sum problem" given sufficient embedding dimension. These insights lead to a novel and effective supervision strategy where we match the softmax outputs to the empirical token distributions of a set of target traces. Complementing this, we introduce sampling strategies that unlock policy optimization and self-improvement for CoT2. Our first strategy samples and composes $K$ discrete tokens at each decoding step to control the level of parallelism, and reduces to standard CoT when $K=1$. Our second strategy relies on continuous exploration over the probability simplex. Experiments confirm that policy optimization with CoT2 indeed improves the performance of the model beyond its initial discrete or continuous supervision.
Attention with Trained Embeddings Provably Selects Important Tokens
May 22, 2025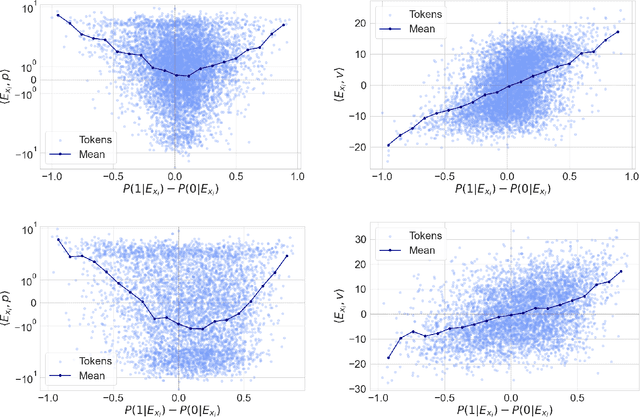
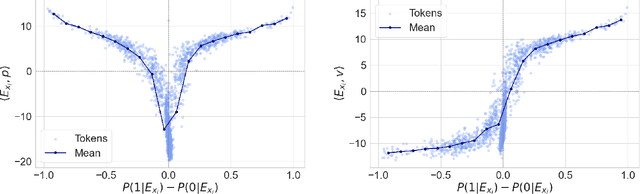
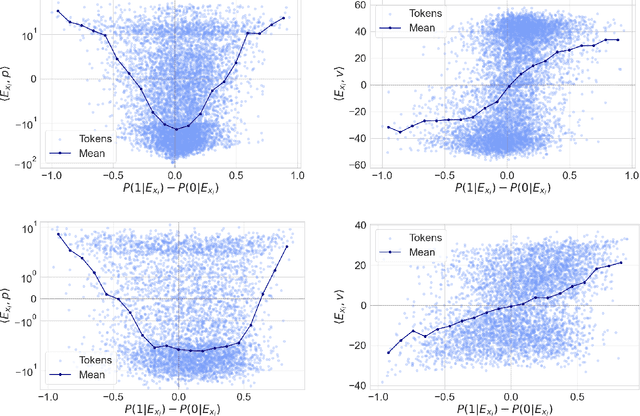
Token embeddings play a crucial role in language modeling but, despite this practical relevance, their theoretical understanding remains limited. Our paper addresses the gap by characterizing the structure of embeddings obtained via gradient descent. Specifically, we consider a one-layer softmax attention model with a linear head for binary classification, i.e., $\texttt{Softmax}( p^\top E_X^\top ) E_X v = \frac{ \sum_{i=1}^T \exp(p^\top E_{x_i}) E_{x_i}^\top v}{\sum_{j=1}^T \exp(p^\top E_{x_{j}}) }$, where $E_X = [ E_{x_1} , \dots, E_{x_T} ]^\top$ contains the embeddings of the input sequence, $p$ is the embedding of the $\mathrm{\langle cls \rangle}$ token and $v$ the output vector. First, we show that, already after a single step of gradient training with the logistic loss, the embeddings $E_X$ capture the importance of tokens in the dataset by aligning with the output vector $v$ proportionally to the frequency with which the corresponding tokens appear in the dataset. Then, after training $p$ via gradient flow until convergence, the softmax selects the important tokens in the sentence (i.e., those that are predictive of the label), and the resulting $\mathrm{\langle cls \rangle}$ embedding maximizes the margin for such a selection. Experiments on real-world datasets (IMDB, Yelp) exhibit a phenomenology close to that unveiled by our theory.
Making Small Language Models Efficient Reasoners: Intervention, Supervision, Reinforcement
May 14, 2025Recent research enhances language model reasoning by scaling test-time compute via longer chain-of-thought traces. This often improves accuracy but also introduces redundancy and high computational cost, especially for small language models distilled with supervised fine-tuning (SFT). In this work, we propose new algorithms to improve token-efficient reasoning with small-scale models by effectively trading off accuracy and computation. We first show that the post-SFT model fails to determine the optimal stopping point of the reasoning process, resulting in verbose and repetitive outputs. Verbosity also significantly varies across wrong vs correct responses. To address these issues, we propose two solutions: (1) Temperature scaling (TS) to control the stopping point for the thinking phase and thereby trace length, and (2) TLDR: a length-regularized reinforcement learning method based on GRPO that facilitates multi-level trace length control (e.g. short, medium, long reasoning). Experiments on four reasoning benchmarks, MATH500, AMC, AIME24 and OlympiadBench, demonstrate that TS is highly effective compared to s1's budget forcing approach and TLDR significantly improves token efficiency by about 50% with minimal to no accuracy loss over the SFT baseline. Moreover, TLDR also facilitates flexible control over the response length, offering a practical and effective solution for token-efficient reasoning in small models. Ultimately, our work reveals the importance of stopping time control, highlights shortcomings of pure SFT, and provides effective algorithmic recipes.
Gating is Weighting: Understanding Gated Linear Attention through In-context Learning
Apr 06, 2025Linear attention methods offer a compelling alternative to softmax attention due to their efficiency in recurrent decoding. Recent research has focused on enhancing standard linear attention by incorporating gating while retaining its computational benefits. Such Gated Linear Attention (GLA) architectures include competitive models such as Mamba and RWKV. In this work, we investigate the in-context learning capabilities of the GLA model and make the following contributions. We show that a multilayer GLA can implement a general class of Weighted Preconditioned Gradient Descent (WPGD) algorithms with data-dependent weights. These weights are induced by the gating mechanism and the input, enabling the model to control the contribution of individual tokens to prediction. To further understand the mechanics of this weighting, we introduce a novel data model with multitask prompts and characterize the optimization landscape of learning a WPGD algorithm. Under mild conditions, we establish the existence and uniqueness (up to scaling) of a global minimum, corresponding to a unique WPGD solution. Finally, we translate these findings to explore the optimization landscape of GLA and shed light on how gating facilitates context-aware learning and when it is provably better than vanilla linear attention.
Test-Time Training Provably Improves Transformers as In-context Learners
Mar 14, 2025Test-time training (TTT) methods explicitly update the weights of a model to adapt to the specific test instance, and they have found success in a variety of settings, including most recently language modeling and reasoning. To demystify this success, we investigate a gradient-based TTT algorithm for in-context learning, where we train a transformer model on the in-context demonstrations provided in the test prompt. Specifically, we provide a comprehensive theoretical characterization of linear transformers when the update rule is a single gradient step. Our theory (i) delineates the role of alignment between pretraining distribution and target task, (ii) demystifies how TTT can alleviate distribution shift, and (iii) quantifies the sample complexity of TTT including how it can significantly reduce the eventual sample size required for in-context learning. As our empirical contribution, we study the benefits of TTT for TabPFN, a tabular foundation model. In line with our theory, we demonstrate that TTT significantly reduces the required sample size for tabular classification (3 to 5 times fewer) unlocking substantial inference efficiency with a negligible training cost.
Identifying Trustworthiness Challenges in Deep Learning Models for Continental-Scale Water Quality Prediction
Mar 13, 2025



Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning models, particularly Long Short-Term Memory (LSTM) networks, offer transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges including fairness, uncertainty, interpretability, robustness, generalizability, and reproducibility. In this work, we present the first comprehensive evaluation of trustworthiness in a continental-scale multi-task LSTM model predicting 20 water quality variables (encompassing physical/chemical processes, geochemical weathering, and nutrient cycling) across 482 U.S. basins. Our investigation uncovers systematic patterns of model performance disparities linked to basin characteristics, the inherent complexity of biogeochemical processes, and variable predictability, emphasizing critical performance fairness concerns. We further propose methodological frameworks for quantitatively evaluating critical aspects of trustworthiness, including uncertainty, interpretability, and robustness, identifying key limitations that could challenge reliable real-world deployment. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management.
Provable Benefits of Task-Specific Prompts for In-context Learning
Mar 05, 2025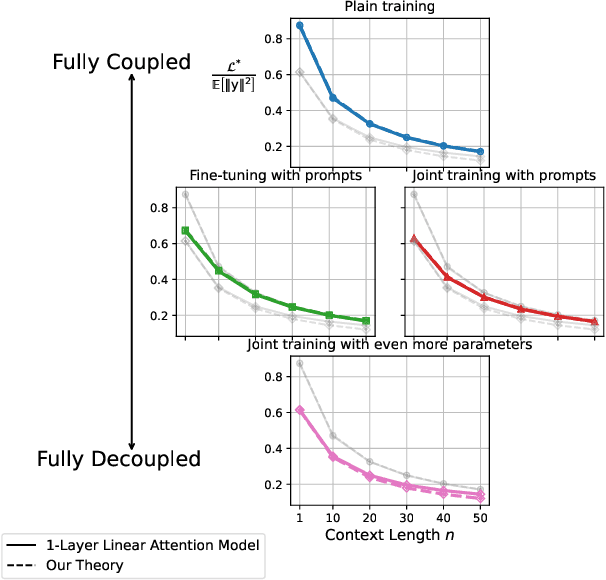
The in-context learning capabilities of modern language models have motivated a deeper mathematical understanding of sequence models. A line of recent work has shown that linear attention models can emulate projected gradient descent iterations to implicitly learn the task vector from the data provided in the context window. In this work, we consider a novel setting where the global task distribution can be partitioned into a union of conditional task distributions. We then examine the use of task-specific prompts and prediction heads for learning the prior information associated with the conditional task distribution using a one-layer attention model. Our results on loss landscape show that task-specific prompts facilitate a covariance-mean decoupling where prompt-tuning explains the conditional mean of the distribution whereas the variance is learned/explained through in-context learning. Incorporating task-specific head further aids this process by entirely decoupling estimation of mean and variance components. This covariance-mean perspective similarly explains how jointly training prompt and attention weights can provably help over fine-tuning after pretraining.
TimePFN: Effective Multivariate Time Series Forecasting with Synthetic Data
Feb 22, 2025The diversity of time series applications and scarcity of domain-specific data highlight the need for time-series models with strong few-shot learning capabilities. In this work, we propose a novel training scheme and a transformer-based architecture, collectively referred to as TimePFN, for multivariate time-series (MTS) forecasting. TimePFN is based on the concept of Prior-data Fitted Networks (PFN), which aims to approximate Bayesian inference. Our approach consists of (1) generating synthetic MTS data through diverse Gaussian process kernels and the linear coregionalization method, and (2) a novel MTS architecture capable of utilizing both temporal and cross-channel dependencies across all input patches. We evaluate TimePFN on several benchmark datasets and demonstrate that it outperforms the existing state-of-the-art models for MTS forecasting in both zero-shot and few-shot settings. Notably, fine-tuning TimePFN with as few as 500 data points nearly matches full dataset training error, and even 50 data points yield competitive results. We also find that TimePFN exhibits strong univariate forecasting performance, attesting to its generalization ability. Overall, this work unlocks the power of synthetic data priors for MTS forecasting and facilitates strong zero- and few-shot forecasting performance.