 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Scientist via Synthetic Task Scaling
Mar 17, 2026With the advent of AI agents, automatic scientific discovery has become a tenable goal. Many recent works scaffold agentic systems that can perform machine learning research, but don't offer a principled way to train such agents -- and current LLMs often generate plausible-looking but ineffective ideas. To make progress on training agents that can learn from doing, we provide a novel synthetic environment generation pipeline targeting machine learning agents. Our pipeline automatically synthesizes machine learning challenges compatible with the SWE-agent framework, covering topic sampling, dataset proposal, and code generation. The resulting synthetic tasks are 1) grounded in real machine learning datasets, because the proposed datasets are verified against the Huggingface API and are 2) verified for higher quality with a self-debugging loop. To validate the effectiveness of our synthetic tasks, we tackle MLGym, a benchmark for machine learning tasks. From the synthetic tasks, we sample trajectories from a teacher model (GPT-5), then use the trajectories to train a student model (Qwen3-4B and Qwen3-8B). The student models trained with our synthetic tasks achieve improved performance on MLGym, raising the AUP metric by 9% for Qwen3-4B and 12% for Qwen3-8B.
h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning
Oct 08, 2025Large language models excel at short-horizon reasoning tasks, but performance drops as reasoning horizon lengths increase. Existing approaches to combat this rely on inference-time scaffolding or costly step-level supervision, neither of which scales easily. In this work, we introduce a scalable method to bootstrap long-horizon reasoning capabilities using only existing, abundant short-horizon data. Our approach synthetically composes simple problems into complex, multi-step dependency chains of arbitrary length. We train models on this data using outcome-only rewards under a curriculum that automatically increases in complexity, allowing RL training to be scaled much further without saturating. Empirically, our method generalizes remarkably well: curriculum training on composed 6th-grade level math problems (GSM8K) boosts accuracy on longer, competition-level benchmarks (GSM-Symbolic, MATH-500, AIME) by up to 2.06x. Importantly, our long-horizon improvements are significantly higher than baselines even at high pass@k, showing that models can learn new reasoning paths under RL. Theoretically, we show that curriculum RL with outcome rewards achieves an exponential improvement in sample complexity over full-horizon training, providing training signal comparable to dense supervision. h1 therefore introduces an efficient path towards scaling RL for long-horizon problems using only existing data.
Extrapolation by Association: Length Generalization Transfer in Transformers
Jun 10, 2025Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this paper, we investigate length generalization--the ability to extrapolate from shorter to longer inputs--through the lens of \textit{task association}. We find that length generalization can be \textit{transferred} across related tasks. That is, training a model with a longer and related auxiliary task can lead it to generalize to unseen and longer inputs from some other target task. We demonstrate this length generalization transfer across diverse algorithmic tasks, including arithmetic operations, string transformations, and maze navigation. Our results show that transformer models can inherit generalization capabilities from similar tasks when trained jointly. Moreover, we observe similar transfer effects in pretrained language models, suggesting that pretraining equips models with reusable computational scaffolding that facilitates extrapolation in downstream settings. Finally, we provide initial mechanistic evidence that length generalization transfer correlates with the re-use of the same attention heads between the tasks. Together, our findings deepen our understanding of how transformers generalize to out-of-distribution inputs and highlight the compositional reuse of inductive structure across tasks.
R&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
May 01, 2025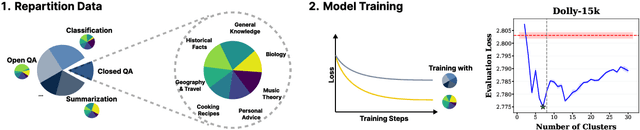
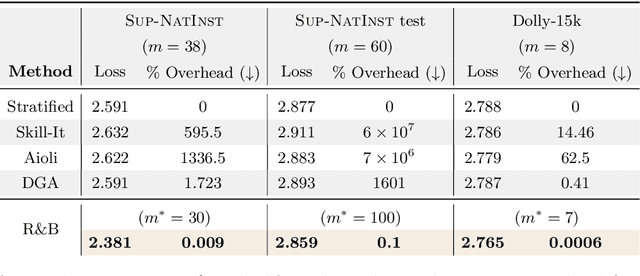
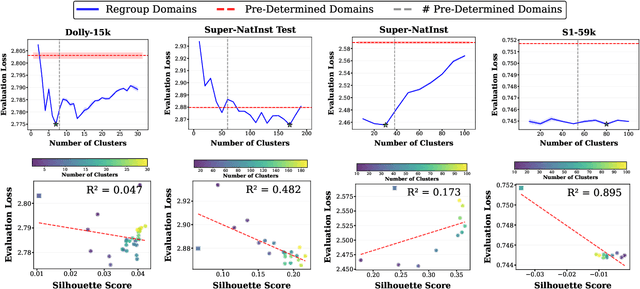
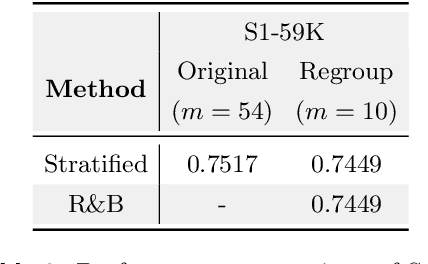
Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
Feb 03, 2025Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a self-improvement approach where models iteratively generate and learn from their own solutions, progressively tackling harder problems while maintaining a standard transformer architecture. Across diverse tasks including arithmetic, string manipulation, and maze solving, self-improving enables models to solve problems far beyond their initial training distribution-for instance, generalizing from 10-digit to 100-digit addition without apparent saturation. We observe that in some cases filtering for correct self-generated examples leads to exponential improvements in out-of-distribution performance across training rounds. Additionally, starting from pretrained models significantly accelerates this self-improvement process for several tasks. Our results demonstrate how controlled weak-to-strong curricula can systematically teach a model logical extrapolation without any changes to the positional embeddings, or the model architecture.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024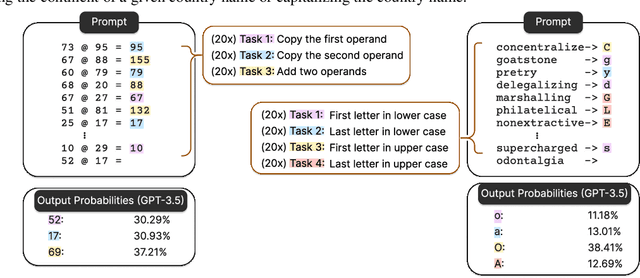

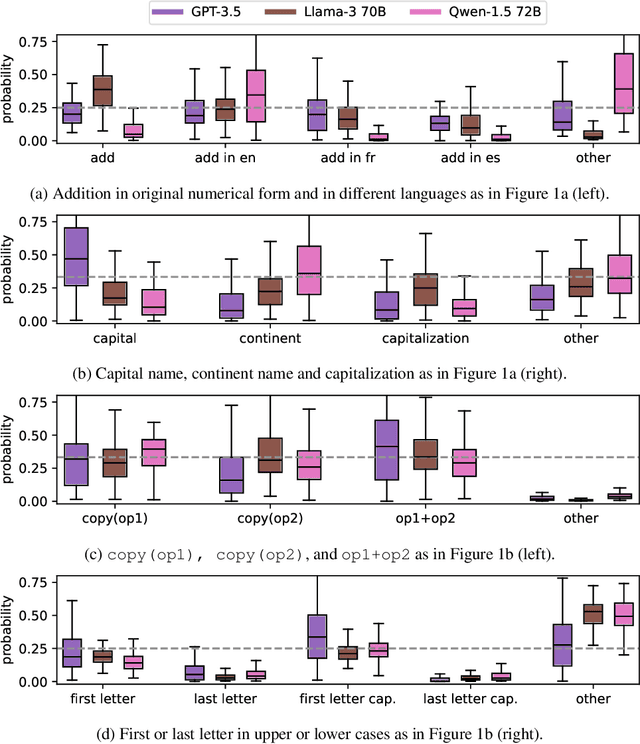
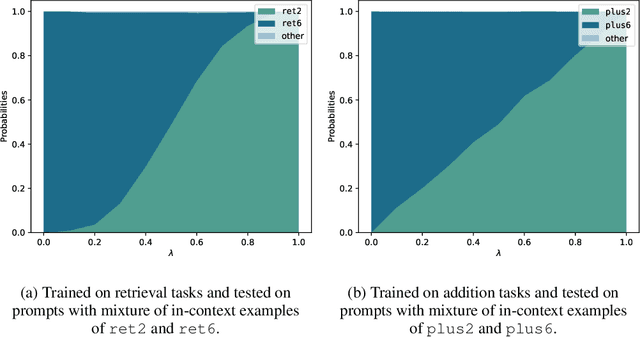
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
Delving into Out-of-Distribution Detection with Vision-Language Representations
Nov 24, 2022Recognizing out-of-distribution (OOD) samples is critical for machine learning systems deployed in the open world. The vast majority of OOD detection methods are driven by a single modality (e.g., either vision or language), leaving the rich information in multi-modal representations untapped. Inspired by the recent success of vision-language pre-training, this paper enriches the landscape of OOD detection from a single-modal to a multi-modal regime. Particularly, we propose Maximum Concept Matching (MCM), a simple yet effective zero-shot OOD detection method based on aligning visual features with textual concepts. We contribute in-depth analysis and theoretical insights to understand the effectiveness of MCM. Extensive experiments demonstrate that MCM achieves superior performance on a wide variety of real-world tasks. MCM with vision-language features outperforms a common baseline with pure visual features on a hard OOD task with semantically similar classes by 13.1% (AUROC). Code is available at https://github.com/deeplearning-wisc/MCM.