 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolation by Association: Length Generalization Transfer in Transformers
Jun 10, 2025Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this paper, we investigate length generalization--the ability to extrapolate from shorter to longer inputs--through the lens of \textit{task association}. We find that length generalization can be \textit{transferred} across related tasks. That is, training a model with a longer and related auxiliary task can lead it to generalize to unseen and longer inputs from some other target task. We demonstrate this length generalization transfer across diverse algorithmic tasks, including arithmetic operations, string transformations, and maze navigation. Our results show that transformer models can inherit generalization capabilities from similar tasks when trained jointly. Moreover, we observe similar transfer effects in pretrained language models, suggesting that pretraining equips models with reusable computational scaffolding that facilitates extrapolation in downstream settings. Finally, we provide initial mechanistic evidence that length generalization transfer correlates with the re-use of the same attention heads between the tasks. Together, our findings deepen our understanding of how transformers generalize to out-of-distribution inputs and highlight the compositional reuse of inductive structure across tasks.
Predictive control of blast furnace temperature in steelmaking with hybrid depth-infused quantum neural networks
Apr 16, 2025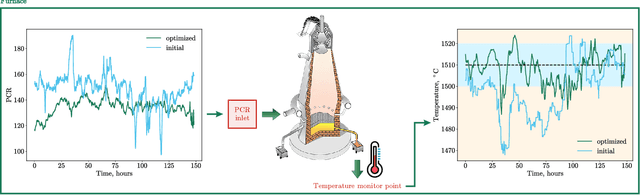
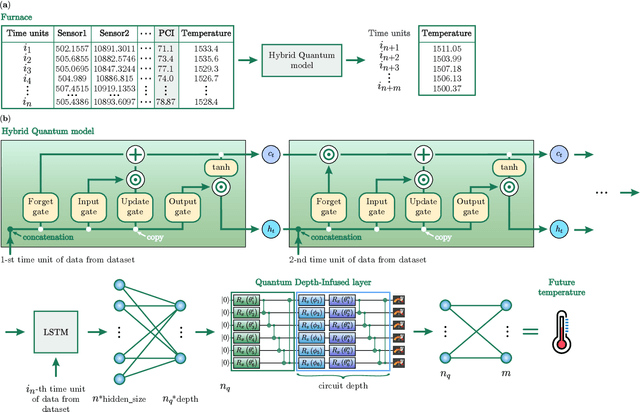
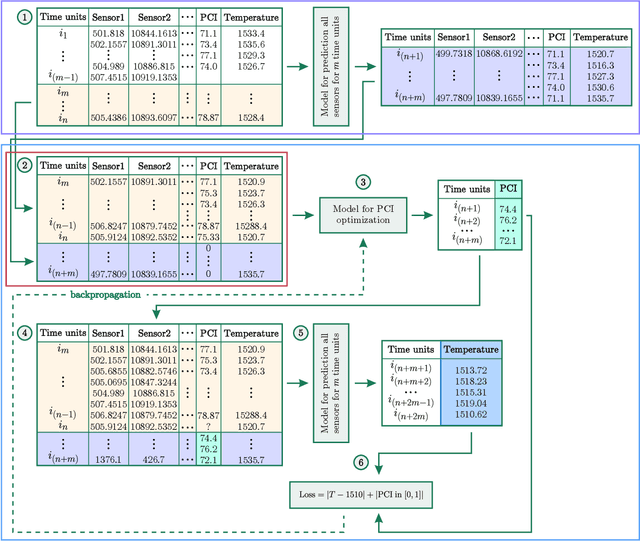
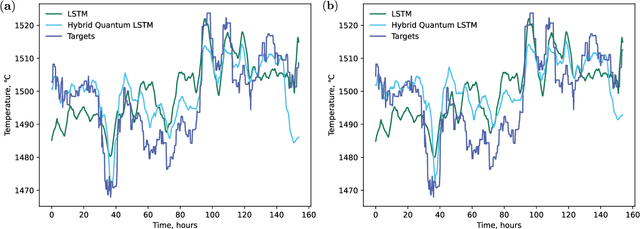
Accurate prediction and stabilization of blast furnace temperatures are crucial for optimizing the efficiency and productivity of steel production. Traditional methods often struggle with the complex and non-linear nature of the temperature fluctuations within blast furnaces. This paper proposes a novel approach that combines hybrid quantum machine learning with pulverized coal injection control to address these challenges. By integrating classical machine learning techniques with quantum computing algorithms, we aim to enhance predictive accuracy and achieve more stable temperature control. For this we utilized a unique prediction-based optimization method. Our method leverages quantum-enhanced feature space exploration and the robustness of classical regression models to forecast temperature variations and optimize pulverized coal injection values. Our results demonstrate a significant improvement in prediction accuracy over 25 percent and our solution improved temperature stability to +-7.6 degrees of target range from the earlier variance of +-50 degrees, highlighting the potential of hybrid quantum machine learning models in industrial steel production applications.
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
Feb 03, 2025Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a self-improvement approach where models iteratively generate and learn from their own solutions, progressively tackling harder problems while maintaining a standard transformer architecture. Across diverse tasks including arithmetic, string manipulation, and maze solving, self-improving enables models to solve problems far beyond their initial training distribution-for instance, generalizing from 10-digit to 100-digit addition without apparent saturation. We observe that in some cases filtering for correct self-generated examples leads to exponential improvements in out-of-distribution performance across training rounds. Additionally, starting from pretrained models significantly accelerates this self-improvement process for several tasks. Our results demonstrate how controlled weak-to-strong curricula can systematically teach a model logical extrapolation without any changes to the positional embeddings, or the model architecture.
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Feb 06, 2024State-space models (SSMs), such as Mamba Gu & Dao (2034), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, \variant, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
Teaching Arithmetic to Small Transformers
Jul 07, 2023



Large language models like GPT-4 exhibit emergent capabilities across general-purpose tasks, such as basic arithmetic, when trained on extensive text data, even though these tasks are not explicitly encoded by the unsupervised, next-token prediction objective. This study investigates how small transformers, trained from random initialization, can efficiently learn arithmetic operations such as addition, multiplication, and elementary functions like square root, using the next-token prediction objective. We first demonstrate that conventional training data is not the most effective for arithmetic learning, and simple formatting changes can significantly improve accuracy. This leads to sharp phase transitions as a function of training data scale, which, in some cases, can be explained through connections to low-rank matrix completion. Building on prior work, we then train on chain-of-thought style data that includes intermediate step results. Even in the complete absence of pretraining, this approach significantly and simultaneously improves accuracy, sample complexity, and convergence speed. We also study the interplay between arithmetic and text data during training and examine the effects of few-shot prompting, pretraining, and model scale. Additionally, we discuss length generalization challenges. Our work highlights the importance of high-quality, instructive data that considers the particular characteristics of the next-word prediction objective for rapidly eliciting arithmetic capabilities.