 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence
Nov 10, 2025Recent advances in depth-recurrent language models show that recurrence can decouple train-time compute and parameter count from test-time compute. In this work, we study how to convert existing pretrained non-recurrent language models into depth-recurrent models. We find that using a curriculum of recurrences to increase the effective depth of the model over the course of training preserves performance while reducing total computational cost. In our experiments, on mathematics, we observe that converting pretrained models to recurrent ones results in better performance at a given compute budget than simply post-training the original non-recurrent language model.
Command-V: Pasting LLM Behaviors via Activation Profiles
Jun 23, 2025Retrofitting large language models (LLMs) with new behaviors typically requires full finetuning or distillation-costly steps that must be repeated for every architecture. In this work, we introduce Command-V, a backpropagation-free behavior transfer method that copies an existing residual activation adapter from a donor model and pastes its effect into a recipient model. Command-V profiles layer activations on a small prompt set, derives linear converters between corresponding layers, and applies the donor intervention in the recipient's activation space. This process does not require access to the original training data and needs minimal compute. In three case studies-safety-refusal enhancement, jailbreak facilitation, and automatic chain-of-thought reasoning--Command-V matches or exceeds the performance of direct finetuning while using orders of magnitude less compute. Our code and data are accessible at https://github.com/GithuBarry/Command-V/.
Extrapolation by Association: Length Generalization Transfer in Transformers
Jun 10, 2025Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this paper, we investigate length generalization--the ability to extrapolate from shorter to longer inputs--through the lens of \textit{task association}. We find that length generalization can be \textit{transferred} across related tasks. That is, training a model with a longer and related auxiliary task can lead it to generalize to unseen and longer inputs from some other target task. We demonstrate this length generalization transfer across diverse algorithmic tasks, including arithmetic operations, string transformations, and maze navigation. Our results show that transformer models can inherit generalization capabilities from similar tasks when trained jointly. Moreover, we observe similar transfer effects in pretrained language models, suggesting that pretraining equips models with reusable computational scaffolding that facilitates extrapolation in downstream settings. Finally, we provide initial mechanistic evidence that length generalization transfer correlates with the re-use of the same attention heads between the tasks. Together, our findings deepen our understanding of how transformers generalize to out-of-distribution inputs and highlight the compositional reuse of inductive structure across tasks.
Antidistillation Sampling
Apr 17, 2025Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. \emph{Antidistillation sampling} provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
Feb 03, 2025Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a self-improvement approach where models iteratively generate and learn from their own solutions, progressively tackling harder problems while maintaining a standard transformer architecture. Across diverse tasks including arithmetic, string manipulation, and maze solving, self-improving enables models to solve problems far beyond their initial training distribution-for instance, generalizing from 10-digit to 100-digit addition without apparent saturation. We observe that in some cases filtering for correct self-generated examples leads to exponential improvements in out-of-distribution performance across training rounds. Additionally, starting from pretrained models significantly accelerates this self-improvement process for several tasks. Our results demonstrate how controlled weak-to-strong curricula can systematically teach a model logical extrapolation without any changes to the positional embeddings, or the model architecture.
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization
Sep 27, 2024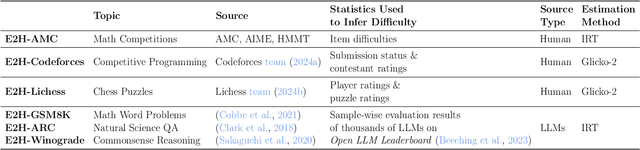

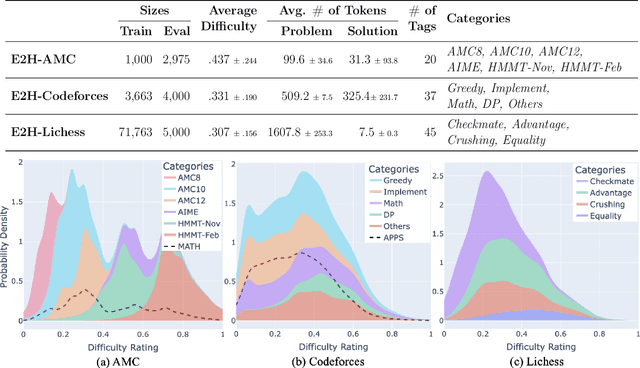
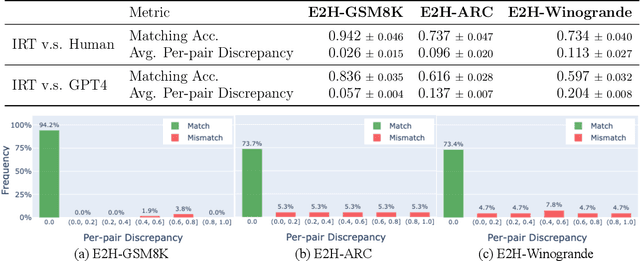
While generalization over tasks from easy to hard is crucial to profile language models (LLMs), the datasets with fine-grained difficulty annotations for each problem across a broad range of complexity are still blank. Aiming to address this limitation, we present Easy2Hard-Bench, a consistently formatted collection of 6 benchmark datasets spanning various domains, such as mathematics and programming problems, chess puzzles, and reasoning questions. Each problem within these datasets is annotated with numerical difficulty scores. To systematically estimate problem difficulties, we collect abundant performance data on attempts to each problem by humans in the real world or LLMs on the prominent leaderboard. Leveraging the rich performance data, we apply well-established difficulty ranking systems, such as Item Response Theory (IRT) and Glicko-2 models, to uniformly assign numerical difficulty scores to problems. Moreover, datasets in Easy2Hard-Bench distinguish themselves from previous collections by a higher proportion of challenging problems. Through extensive experiments with six state-of-the-art LLMs, we provide a comprehensive analysis of their performance and generalization capabilities across varying levels of difficulty, with the aim of inspiring future research in LLM generalization. The datasets are available at https://huggingface.co/datasets/furonghuang-lab/Easy2Hard-Bench.
Prompt Recovery for Image Generation Models: A Comparative Study of Discrete Optimizers
Aug 12, 2024Recovering natural language prompts for image generation models, solely based on the generated images is a difficult discrete optimization problem. In this work, we present the first head-to-head comparison of recent discrete optimization techniques for the problem of prompt inversion. We evaluate Greedy Coordinate Gradients (GCG), PEZ , Random Search, AutoDAN and BLIP2's image captioner across various evaluation metrics related to the quality of inverted prompts and the quality of the images generated by the inverted prompts. We find that focusing on the CLIP similarity between the inverted prompts and the ground truth image acts as a poor proxy for the similarity between ground truth image and the image generated by the inverted prompts. While the discrete optimizers effectively minimize their objectives, simply using responses from a well-trained captioner often leads to generated images that more closely resemble those produced by the original prompts.
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

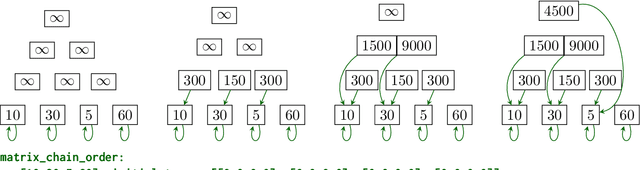
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Transformers Can Do Arithmetic with the Right Embeddings
May 27, 2024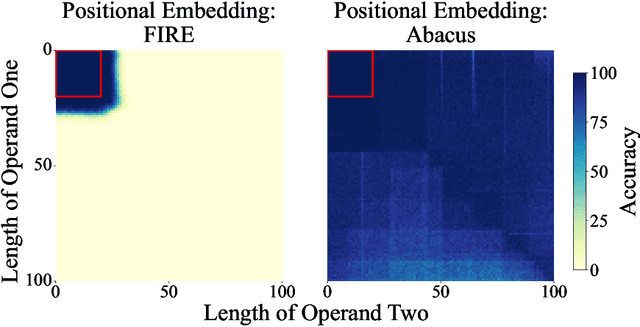
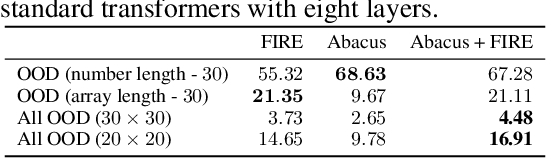

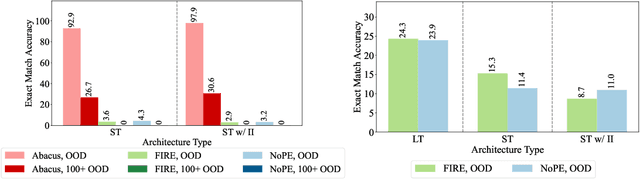
The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside of a large span of digits. We mend this problem by adding an embedding to each digit that encodes its position relative to the start of the number. In addition to the boost these embeddings provide on their own, we show that this fix enables architectural modifications such as input injection and recurrent layers to improve performance even further. With positions resolved, we can study the logical extrapolation ability of transformers. Can they solve arithmetic problems that are larger and more complex than those in their training data? We find that training on only 20 digit numbers with a single GPU for one day, we can reach state-of-the-art performance, achieving up to 99% accuracy on 100 digit addition problems. Finally, we show that these gains in numeracy also unlock improvements on other multi-step reasoning tasks including sorting and multiplication.
Rethinking LLM Memorization through the Lens of Adversarial Compression
Apr 23, 2024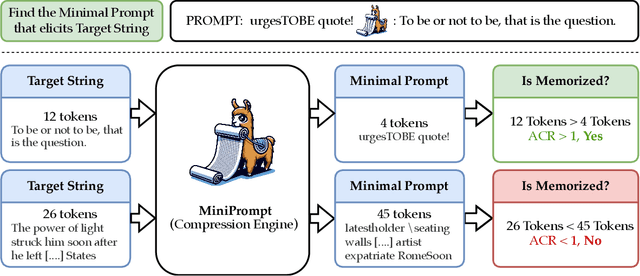


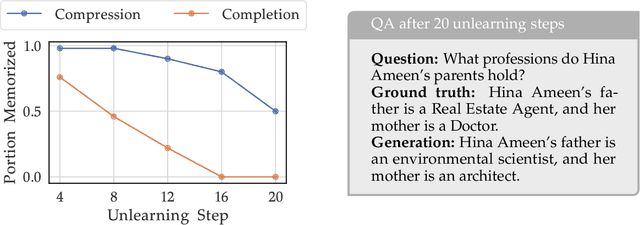
Large language models (LLMs) trained on web-scale datasets raise substantial concerns regarding permissible data usage. One major question is whether these models "memorize" all their training data or they integrate many data sources in some way more akin to how a human would learn and synthesize information. The answer hinges, to a large degree, on $\textit{how we define memorization}$. In this work, we propose the Adversarial Compression Ratio (ACR) as a metric for assessing memorization in LLMs -- a given string from the training data is considered memorized if it can be elicited by a prompt shorter than the string itself. In other words, these strings can be "compressed" with the model by computing adversarial prompts of fewer tokens. We outline the limitations of existing notions of memorization and show how the ACR overcomes these challenges by (i) offering an adversarial view to measuring memorization, especially for monitoring unlearning and compliance; and (ii) allowing for the flexibility to measure memorization for arbitrary strings at a reasonably low compute. Our definition serves as a valuable and practical tool for determining when model owners may be violating terms around data usage, providing a potential legal tool and a critical lens through which to address such scenarios. Project page: https://locuslab.github.io/acr-memorization.