 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Mixer Models: Flexible Sequence Modeling with Shared Representations
May 27, 2026Softmax attention is the cornerstone of modern large language models, but its memory scales linearly and compute quadratically with sequence length. Linear recurrent models, such as linear attention and state space models, have become widely studied as alternatives to attention due to their linear compute and constant memory. While these sub-quadratic token mixing methods, or mixers, achieve promising efficiency gains and competitive results on a wide range of benchmarks, current linear recurrent models still lag behind on tasks that require long-context retrieval or in-context learning. A growing body of work studies hybrid architectures that attempt to mitigate these trade-offs by statically interleaving or merging attention and recurrent blocks. In this work, we explore a new axis of developing hybrid models: across the token sequence. We propose Oryx, a hybrid model that can, throughout a sequence, flexibly switch between different mixers, for example quadratic attention for rich context utilization and linear recurrences for efficient generation. Oryx ties at least 90% of its parameters across mixers, enabling attention and recurrent modes to operate over shared internal representations. We validate our design with Mamba-2 and Gated DeltaNet variants, up to 1.4B models. Under fixed token budgets and a mixed-training strategy, Oryx achieves comparable or better performance than its single-mixer baselines. At the 1.4B scale, all instances of Oryx outperform their respective baselines by at least 0.7 percentage points on averaged language modeling tasks. On retrieval tasks, Oryx achieves performance comparable to the Transformer baseline even when processing only a tiny fraction (<10%) of the tokens in attention mode. These results suggest that attention and linear recurrent models can share internal representations, and motivate sequence-axis hybridization as a promising direction.
Mimetic Initialization of MLPs
Feb 06, 2026Mimetic initialization uses pretrained models as case studies of good initialization, using observations of structures in trained weights to inspire new, simple initialization techniques. So far, it has been applied only to spatial mixing layers, such convolutional, self-attention, and state space layers. In this work, we present the first attempt to apply the method to channel mixing layers, namely multilayer perceptrons (MLPs). Our extremely simple technique for MLPs -- to give the first layer a nonzero mean -- speeds up training on small-scale vision tasks like CIFAR-10 and ImageNet-1k. Though its effect is much smaller than spatial mixing initializations, it can be used in conjunction with them for an additional positive effect.
Antidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
Antidistillation Sampling
Apr 17, 2025Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. \emph{Antidistillation sampling} provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.
Mimetic Initialization Helps State Space Models Learn to Recall
Oct 14, 2024



Recent work has shown that state space models such as Mamba are significantly worse than Transformers on recall-based tasks due to the fact that their state size is constant with respect to their input sequence length. But in practice, state space models have fairly large state sizes, and we conjecture that they should be able to perform much better at these tasks than previously reported. We investigate whether their poor copying and recall performance could be due in part to training difficulties rather than fundamental capacity constraints. Based on observations of their "attention" maps, we propose a structured initialization technique that allows state space layers to more readily mimic attention. Across a variety of architecture settings, our initialization makes it substantially easier for Mamba to learn to copy and do associative recall from scratch.
Mimetic Initialization of Self-Attention Layers
May 16, 2023



It is notoriously difficult to train Transformers on small datasets; typically, large pre-trained models are instead used as the starting point. We explore the weights of such pre-trained Transformers (particularly for vision) to attempt to find reasons for this discrepancy. Surprisingly, we find that simply initializing the weights of self-attention layers so that they "look" more like their pre-trained counterparts allows us to train vanilla Transformers faster and to higher final accuracies, particularly on vision tasks such as CIFAR-10 and ImageNet classification, where we see gains in accuracy of over 5% and 4%, respectively. Our initialization scheme is closed form, learning-free, and very simple: we set the product of the query and key weights to be approximately the identity, and the product of the value and projection weights to approximately the negative identity. As this mimics the patterns we saw in pre-trained Transformers, we call the technique "mimetic initialization".
Understanding the Covariance Structure of Convolutional Filters
Oct 07, 2022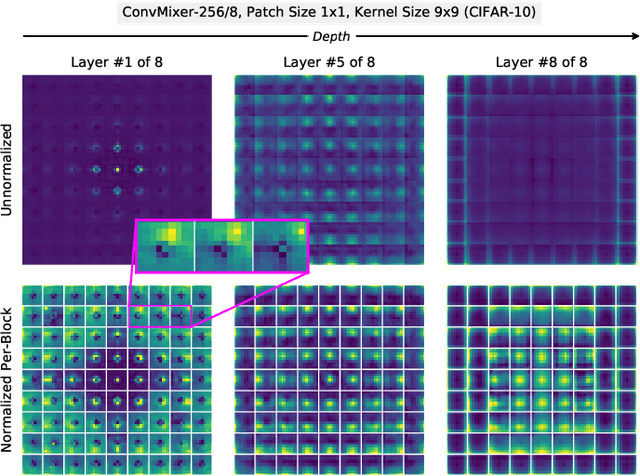
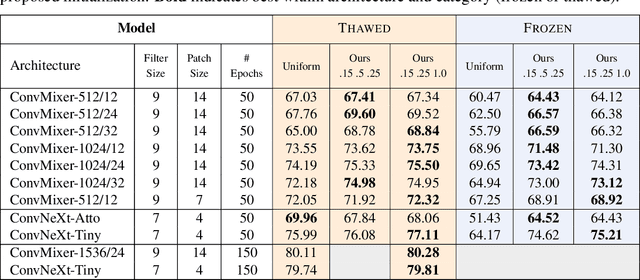
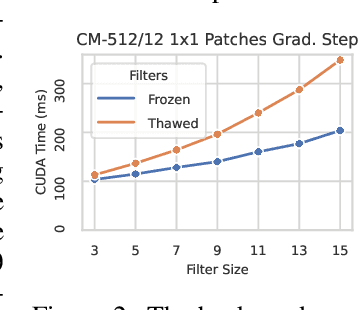

Neural network weights are typically initialized at random from univariate distributions, controlling just the variance of individual weights even in highly-structured operations like convolutions. Recent ViT-inspired convolutional networks such as ConvMixer and ConvNeXt use large-kernel depthwise convolutions whose learned filters have notable structure; this presents an opportunity to study their empirical covariances. In this work, we first observe that such learned filters have highly-structured covariance matrices, and moreover, we find that covariances calculated from small networks may be used to effectively initialize a variety of larger networks of different depths, widths, patch sizes, and kernel sizes, indicating a degree of model-independence to the covariance structure. Motivated by these findings, we then propose a learning-free multivariate initialization scheme for convolutional filters using a simple, closed-form construction of their covariance. Models using our initialization outperform those using traditional univariate initializations, and typically meet or exceed the performance of those initialized from the covariances of learned filters; in some cases, this improvement can be achieved without training the depthwise convolutional filters at all.
Patches Are All You Need?
Jan 24, 2022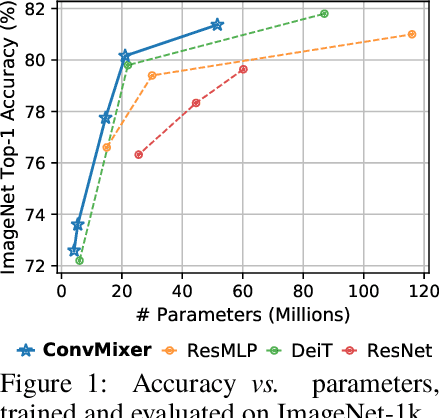
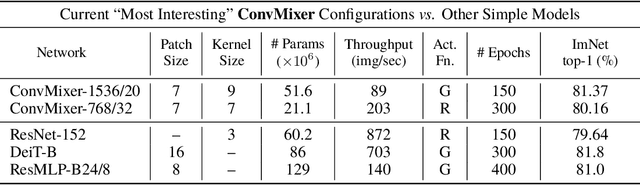
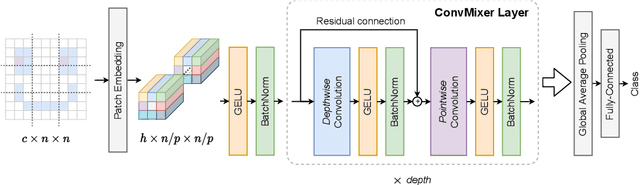
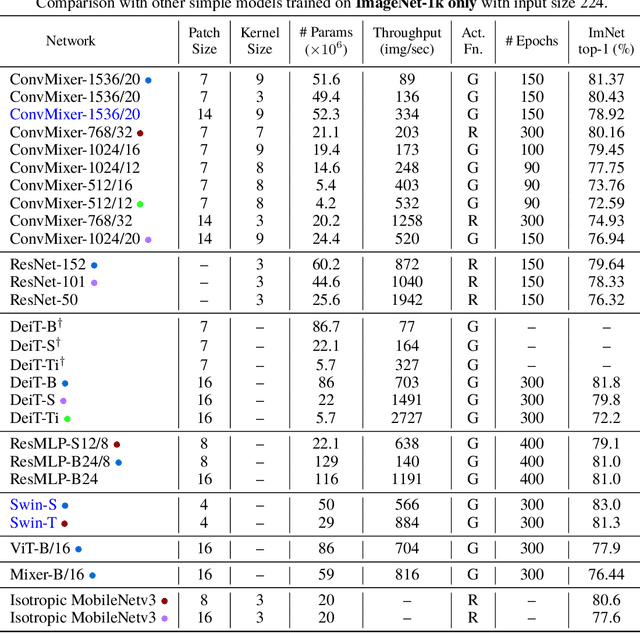
Although convolutional networks have been the dominant architecture for vision tasks for many years, recent experiments have shown that Transformer-based models, most notably the Vision Transformer (ViT), may exceed their performance in some settings. However, due to the quadratic runtime of the self-attention layers in Transformers, ViTs require the use of patch embeddings, which group together small regions of the image into single input features, in order to be applied to larger image sizes. This raises a question: Is the performance of ViTs due to the inherently-more-powerful Transformer architecture, or is it at least partly due to using patches as the input representation? In this paper, we present some evidence for the latter: specifically, we propose the ConvMixer, an extremely simple model that is similar in spirit to the ViT and the even-more-basic MLP-Mixer in that it operates directly on patches as input, separates the mixing of spatial and channel dimensions, and maintains equal size and resolution throughout the network. In contrast, however, the ConvMixer uses only standard convolutions to achieve the mixing steps. Despite its simplicity, we show that the ConvMixer outperforms the ViT, MLP-Mixer, and some of their variants for similar parameter counts and data set sizes, in addition to outperforming classical vision models such as the ResNet. Our code is available at https://github.com/locuslab/convmixer.
Orthogonalizing Convolutional Layers with the Cayley Transform
Apr 14, 2021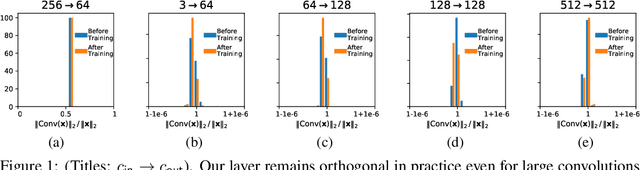
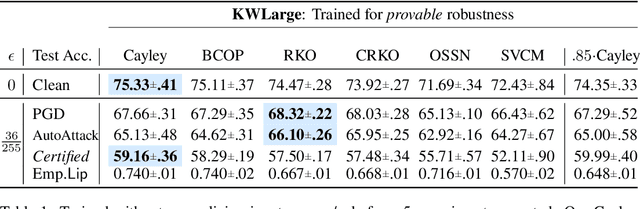
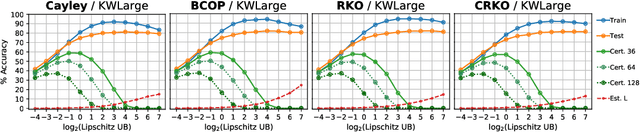
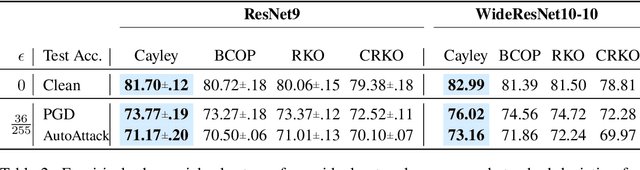
Recent work has highlighted several advantages of enforcing orthogonality in the weight layers of deep networks, such as maintaining the stability of activations, preserving gradient norms, and enhancing adversarial robustness by enforcing low Lipschitz constants. Although numerous methods exist for enforcing the orthogonality of fully-connected layers, those for convolutional layers are more heuristic in nature, often focusing on penalty methods or limited classes of convolutions. In this work, we propose and evaluate an alternative approach to directly parameterize convolutional layers that are constrained to be orthogonal. Specifically, we propose to apply the Cayley transform to a skew-symmetric convolution in the Fourier domain, so that the inverse convolution needed by the Cayley transform can be computed efficiently. We compare our method to previous Lipschitz-constrained and orthogonal convolutional layers and show that it indeed preserves orthogonality to a high degree even for large convolutions. Applied to the problem of certified adversarial robustness, we show that networks incorporating the layer outperform existing deterministic methods for certified defense against $\ell_2$-norm-bounded adversaries, while scaling to larger architectures than previously investigated. Code is available at https://github.com/locuslab/orthogonal-convolutions.