 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidistillation Sampling
Apr 17, 2025Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. \emph{Antidistillation sampling} provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.
Sequence-level Large Language Model Training with Contrastive Preference Optimization
Feb 23, 2025



The next token prediction loss is the dominant self-supervised training objective for large language models and has achieved promising results in a variety of downstream tasks. However, upon closer investigation of this objective, we find that it lacks an understanding of sequence-level signals, leading to a mismatch between training and inference processes. To bridge this gap, we introduce a contrastive preference optimization (CPO) procedure that can inject sequence-level information into the language model at any training stage without expensive human labeled data. Our experiments show that the proposed objective surpasses the next token prediction in terms of win rate in the instruction-following and text generation tasks.
Adapting Language Models via Token Translation
Nov 01, 2024Modern large language models use a fixed tokenizer to effectively compress text drawn from a source domain. However, applying the same tokenizer to a new target domain often leads to inferior compression, more costly inference, and reduced semantic alignment. To address this deficiency, we introduce Sparse Sinkhorn Token Translation (S2T2). S2T2 trains a tailored tokenizer for the target domain and learns to translate between target and source tokens, enabling more effective reuse of the pre-trained next-source-token predictor. In our experiments with finetuned English language models, S2T2 improves both the perplexity and the compression of out-of-domain protein sequences, outperforming direct finetuning with either the source or target tokenizer. In addition, we find that token translations learned for smaller, less expensive models can be directly transferred to larger, more powerful models to reap the benefits of S2T2 at lower cost.
Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws
Oct 15, 2024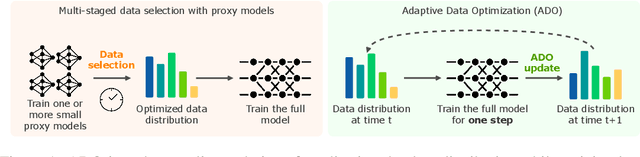
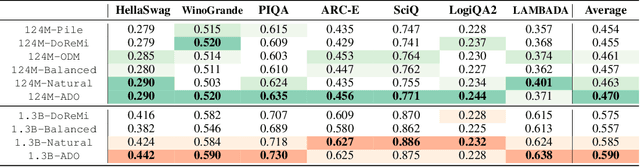
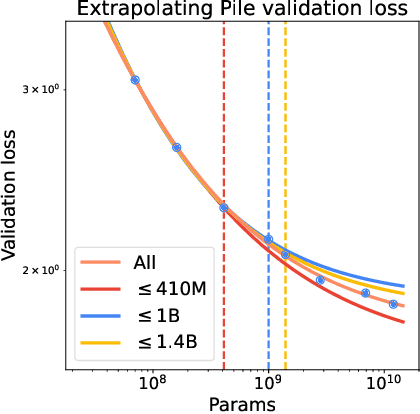
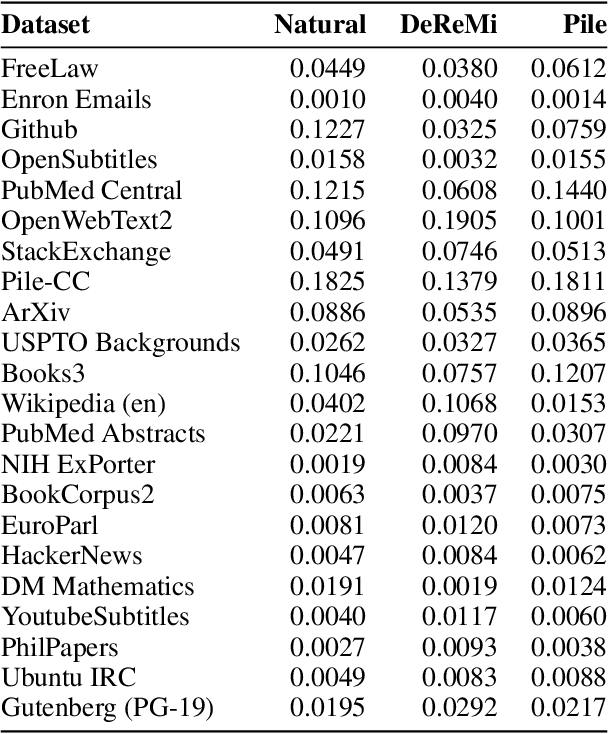
The composition of pretraining data is a key determinant of foundation models' performance, but there is no standard guideline for allocating a limited computational budget across different data sources. Most current approaches either rely on extensive experiments with smaller models or dynamic data adjustments that also require proxy models, both of which significantly increase the workflow complexity and computational overhead. In this paper, we introduce Adaptive Data Optimization (ADO), an algorithm that optimizes data distributions in an online fashion, concurrent with model training. Unlike existing techniques, ADO does not require external knowledge, proxy models, or modifications to the model update. Instead, ADO uses per-domain scaling laws to estimate the learning potential of each domain during training and adjusts the data mixture accordingly, making it more scalable and easier to integrate. Experiments demonstrate that ADO can achieve comparable or better performance than prior methods while maintaining computational efficiency across different computation scales, offering a practical solution for dynamically adjusting data distribution without sacrificing flexibility or increasing costs. Beyond its practical benefits, ADO also provides a new perspective on data collection strategies via scaling laws.
Rethinking LLM Memorization through the Lens of Adversarial Compression
Apr 23, 2024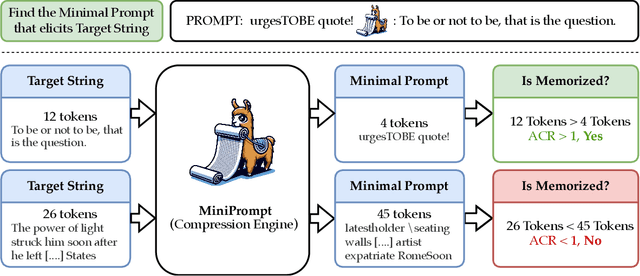


Large language models (LLMs) trained on web-scale datasets raise substantial concerns regarding permissible data usage. One major question is whether these models "memorize" all their training data or they integrate many data sources in some way more akin to how a human would learn and synthesize information. The answer hinges, to a large degree, on $\textit{how we define memorization}$. In this work, we propose the Adversarial Compression Ratio (ACR) as a metric for assessing memorization in LLMs -- a given string from the training data is considered memorized if it can be elicited by a prompt shorter than the string itself. In other words, these strings can be "compressed" with the model by computing adversarial prompts of fewer tokens. We outline the limitations of existing notions of memorization and show how the ACR overcomes these challenges by (i) offering an adversarial view to measuring memorization, especially for monitoring unlearning and compliance; and (ii) allowing for the flexibility to measure memorization for arbitrary strings at a reasonably low compute. Our definition serves as a valuable and practical tool for determining when model owners may be violating terms around data usage, providing a potential legal tool and a critical lens through which to address such scenarios. Project page: https://locuslab.github.io/acr-memorization.
RankCLIP: Ranking-Consistent Language-Image Pretraining
Apr 15, 2024Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
An Axiomatic Approach to Model-Agnostic Concept Explanations
Jan 12, 2024Concept explanation is a popular approach for examining how human-interpretable concepts impact the predictions of a model. However, most existing methods for concept explanations are tailored to specific models. To address this issue, this paper focuses on model-agnostic measures. Specifically, we propose an approach to concept explanations that satisfy three natural axioms: linearity, recursivity, and similarity. We then establish connections with previous concept explanation methods, offering insight into their varying semantic meanings. Experimentally, we demonstrate the utility of the new method by applying it in different scenarios: for model selection, optimizer selection, and model improvement using a kind of prompt editing for zero-shot vision language models.
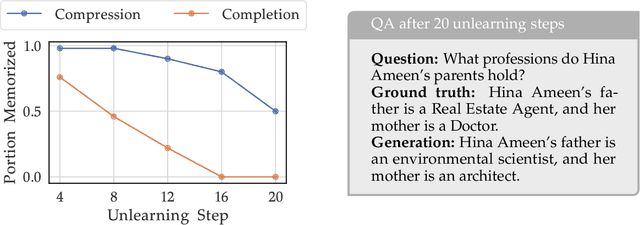
TOFU: A Task of Fictitious Unlearning for LLMs
Jan 11, 2024Large language models trained on massive corpora of data from the web can memorize and reproduce sensitive or private data raising both legal and ethical concerns. Unlearning, or tuning models to forget information present in their training data, provides us with a way to protect private data after training. Although several methods exist for such unlearning, it is unclear to what extent they result in models equivalent to those where the data to be forgotten was never learned in the first place. To address this challenge, we present TOFU, a Task of Fictitious Unlearning, as a benchmark aimed at helping deepen our understanding of unlearning. We offer a dataset of 200 diverse synthetic author profiles, each consisting of 20 question-answer pairs, and a subset of these profiles called the forget set that serves as the target for unlearning. We compile a suite of metrics that work together to provide a holistic picture of unlearning efficacy. Finally, we provide a set of baseline results from existing unlearning algorithms. Importantly, none of the baselines we consider show effective unlearning motivating continued efforts to develop approaches for unlearning that effectively tune models so that they truly behave as if they were never trained on the forget data at all.
On the Neural Tangent Kernel of Equilibrium Models
Oct 21, 2023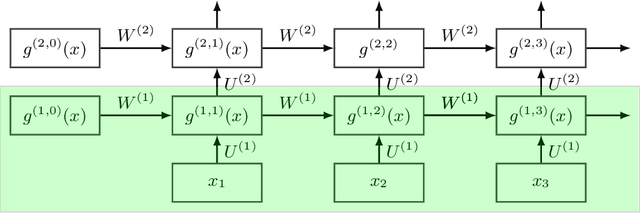

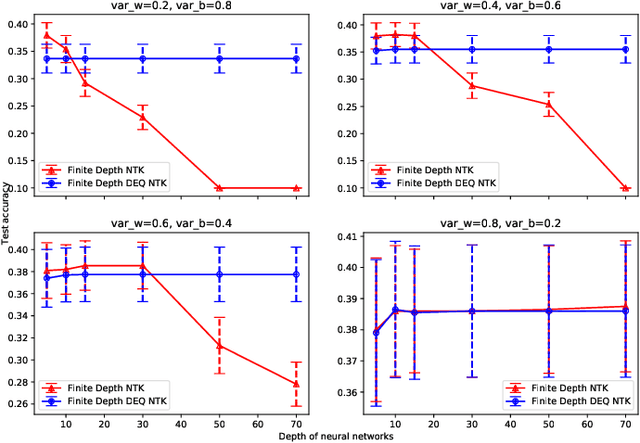

This work studies the neural tangent kernel (NTK) of the deep equilibrium (DEQ) model, a practical ``infinite-depth'' architecture which directly computes the infinite-depth limit of a weight-tied network via root-finding. Even though the NTK of a fully-connected neural network can be stochastic if its width and depth both tend to infinity simultaneously, we show that contrarily a DEQ model still enjoys a deterministic NTK despite its width and depth going to infinity at the same time under mild conditions. Moreover, this deterministic NTK can be found efficiently via root-finding.
Monotone deep Boltzmann machines
Jul 11, 2023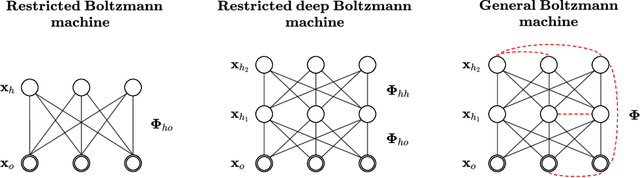

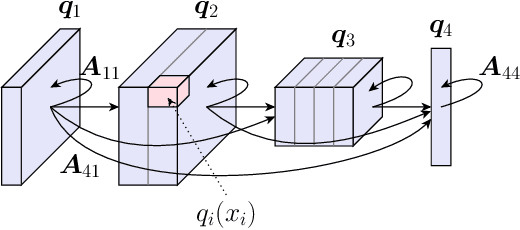

Deep Boltzmann machines (DBMs), one of the first ``deep'' learning methods ever studied, are multi-layered probabilistic models governed by a pairwise energy function that describes the likelihood of all variables/nodes in the network. In practice, DBMs are often constrained, i.e., via the \emph{restricted} Boltzmann machine (RBM) architecture (which does not permit intra-layer connections), in order to allow for more efficient inference. In this work, we revisit the generic DBM approach, and ask the question: are there other possible restrictions to their design that would enable efficient (approximate) inference? In particular, we develop a new class of restricted model, the monotone DBM, which allows for arbitrary self-connection in each layer, but restricts the \emph{weights} in a manner that guarantees the existence and global uniqueness of a mean-field fixed point. To do this, we leverage tools from the recently-proposed monotone Deep Equilibrium model and show that a particular choice of activation results in a fixed-point iteration that gives a variational mean-field solution. While this approach is still largely conceptual, it is the first architecture that allows for efficient approximate inference in fully-general weight structures for DBMs. We apply this approach to simple deep convolutional Boltzmann architectures and demonstrate that it allows for tasks such as the joint completion and classification of images, within a single deep probabilistic setting, while avoiding the pitfalls of mean-field inference in traditional RBMs.